
Character representation
- A brief history of coding systems
- Representation
- Efficiency
Unicode
A theme: Good systems design can achieve excellent tradeoffs between efficiency and representation!
Coding systems
- A coding system represents human language in form other than speech
- Standardization!
- Any written language is a coding system
- Alphabetic (a mark represents a part of a sound; Latin, Cyrillic, Coptic, Korean)
- Syllabic (a mark represents a sound combination; some Japanese scripts)
- Logographic (a mark represents a word; Chinese Hanzi)
- Representations can be translated into new forms!
Chappe semaphore, 1790s

- Letters → arrangements of mechanical arms visible from far away
Braille alphabet, 1820s

- Letters and letter combinations → patterns of dots perceptible to touch
Japanese Braille, 1880s

- Braille’s symbols repurposed to a completely different syllabary
- Issues of ambiguity and misinterpretation
- Meaning of Braille symbols depends on context
- How to unambiguously interpret a document combining French and Japanese Braille symbols?
Efficiency vs. representation
- Efficiency and parsimony are essential goals for computer systems
- Represent data in the smallest space
- Less expensive, more capacity
- Take less time to transmit
- Efficiency and parsimony are also essential for humans
- Human limitations in distinguishing marks
- Braille formerly had more symbols, distinguished by the use of dashes in some positions as well as dots (a ternary-like system), but “by the second edition in 1837 [Louis Braille] had discarded the dashes because they were too difficult to read.” ref
- Efficiency and parsimony can conflict with representation!
Telegraphy, 1930s
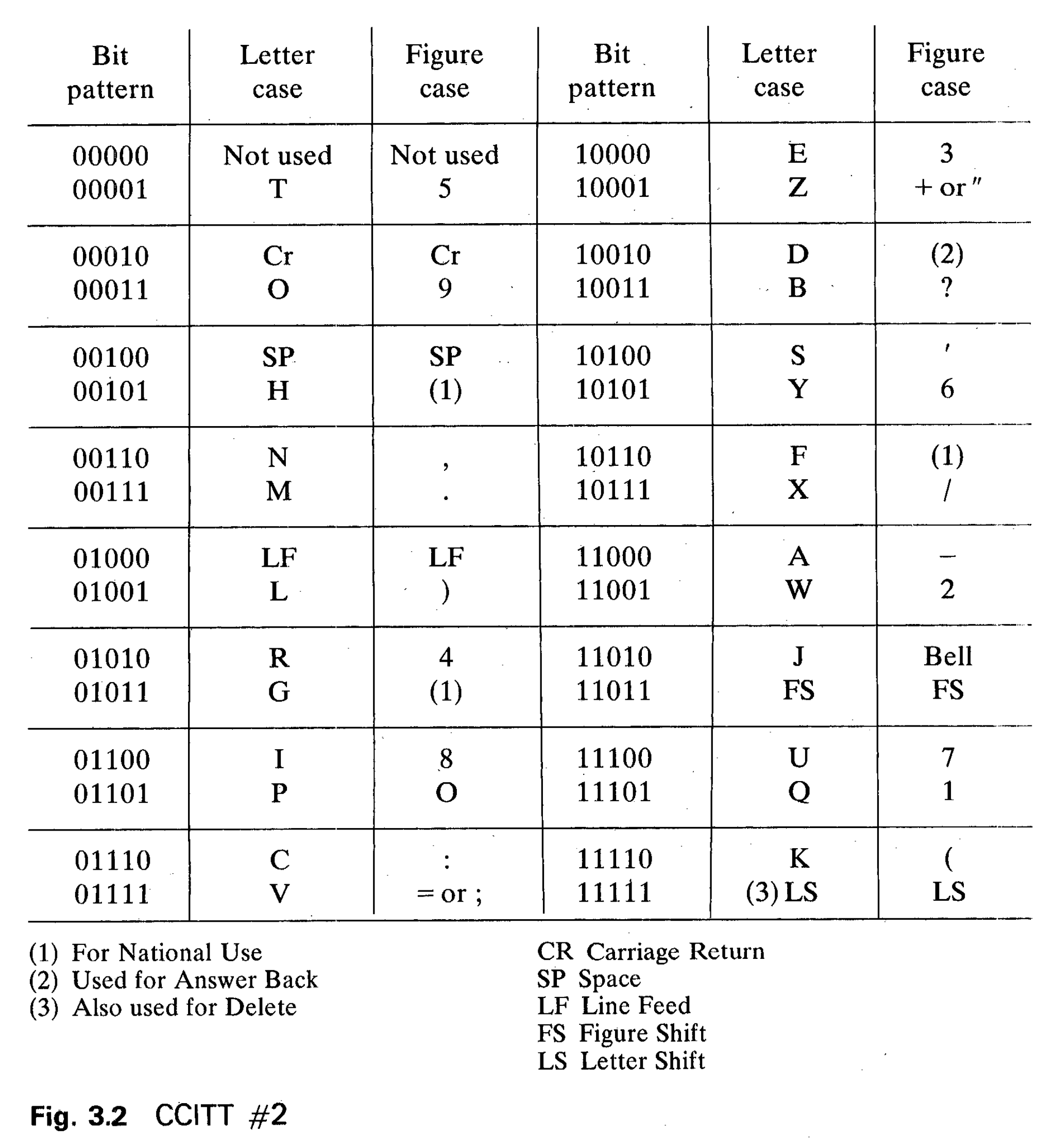
- Telegraphy uses a binary coding system (dot + dash)
- 25 = 32 distinct patterns
- Complex “shift” system multiplexes some patterns
11111011101101101110= “C:”- So the
01110pattern means different things depending on context - Vulnerable to error: a misinterpreted symbol can change meanings of all future symbols
BCDIC, 1930s
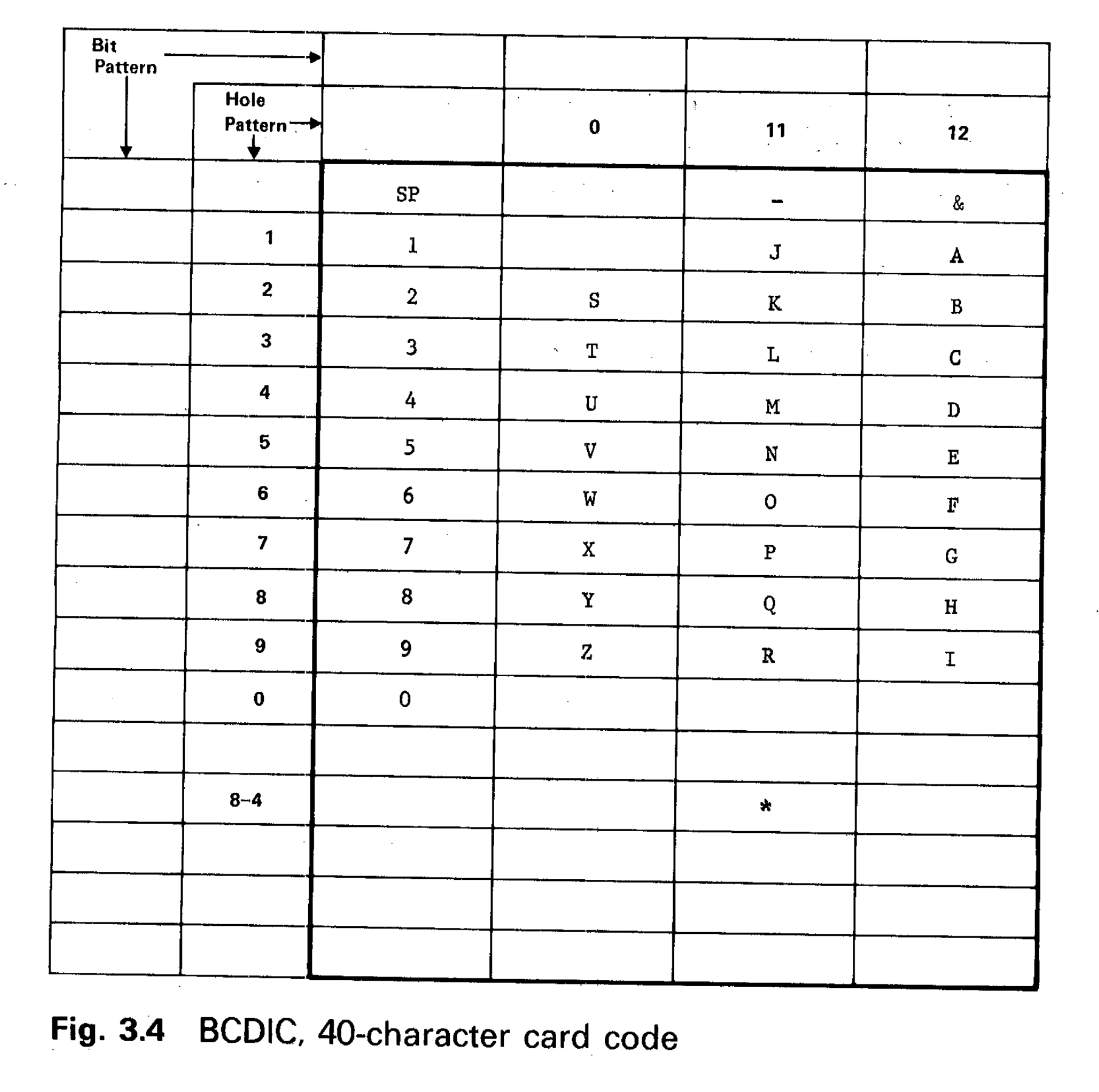
- Derived from punched-card codes originally developed for the US Census in the late 1800s
ASCII, 1960s
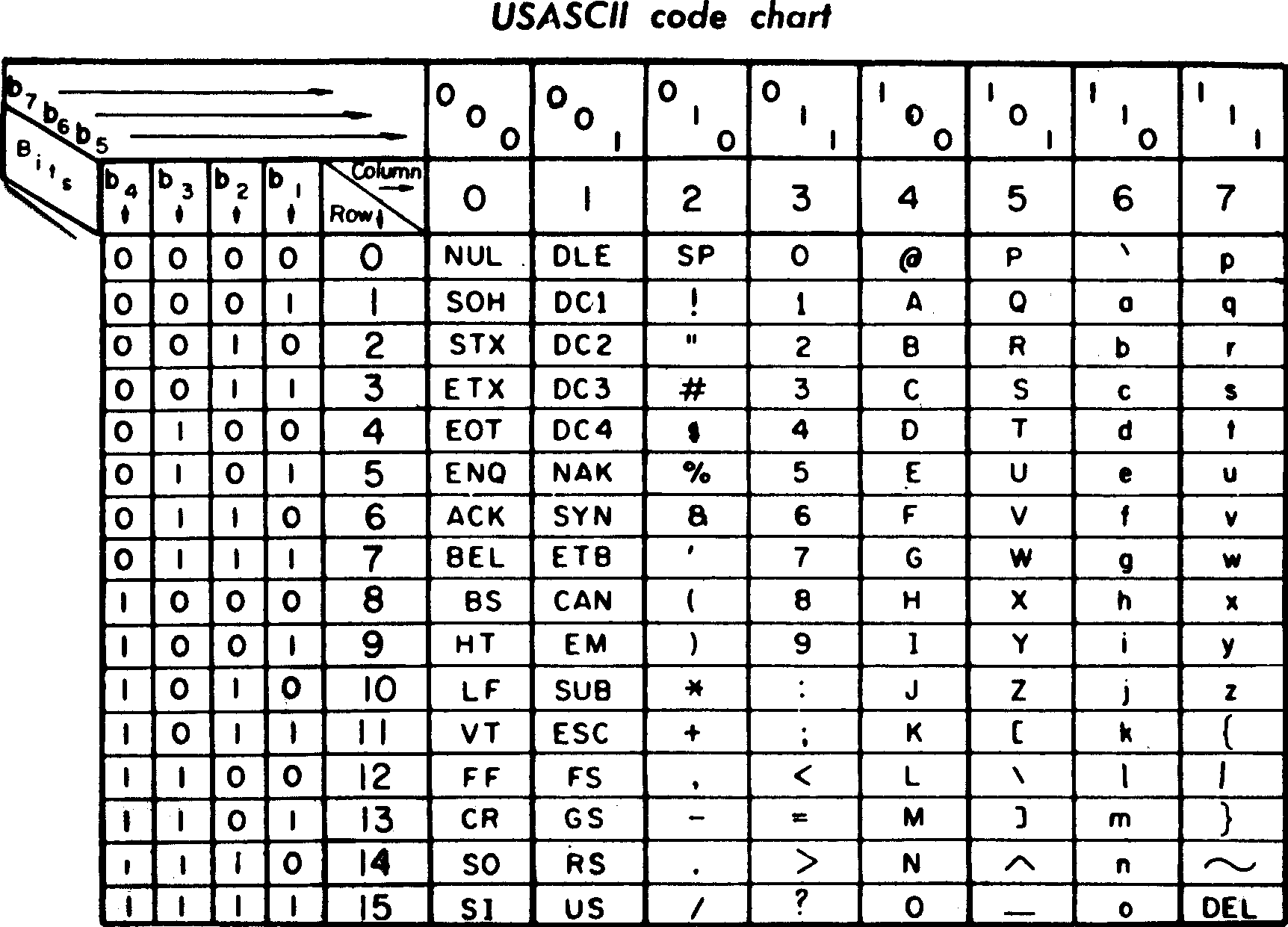
- American Standard Code for Information Interchange
- Foundation for many national standards
- Controversial at the time
MORE THAN 64 CHARACTERS!

America and the world
- ISO (International Standards Organization) adopted ASCII as ISO/IEC 646, with a caveat
- The characters
[ \ ] { | }(and, to a lesser extent,^ ~ # $ @ ') were “reserved for national use” - Different governments used those slots to represent critical characters in their languages
- Different nations speaking the same language made different choices!
| à | â | ç | É | é | ê | è | î | ô | ù | û | £ | ° | § | ¨ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| French (ISO-IR-025) | @ |
N/A | \ |
N/A | { |
N/A | } |
N/A | N/A | | |
N/A | # |
[ |
] |
~ |
| Canadian French #1 (ISO-IR-121) | @ |
[ |
\ |
N/A | { |
] |
} |
^ |
` |
| |
~ |
N/A | N/A | N/A | N/A |
| Canadian French #2 (ISO-IR-122) | @ |
[ |
\ |
^ |
{ |
] |
} |
N/A | ` |
| |
~ |
N/A | N/A | N/A | N/A |
- The meaning of an encoded text depends on national context!
- Does
^lemean that, orÉle(Canadian #2), orîle(Canadian #1)? - Humans can sort of adapt, but it’s painful
- Does
C
{ a[i] = '\n'; }C?
ä aÄiÜ = 'Ön'; ü…C?
??< a??(i??) = '??/n'; ??>What about that 7th bit?
- Error correction!
- Parity bit (checksum)
- Bit 7 = Bit 6 ^ Bit 5 ^ Bit 4 ^ Bit 3 ^ Bit 2 ^ Bit 1 ^ Bit 0
- Can detect any single-bit-flip error (“hit”)
MORE THAN 128 CHARACTERS!
- Telephone equipment gets better, errors less frequent, storage cheaper
- Use slots 128-255 for accented characters and additional symbols
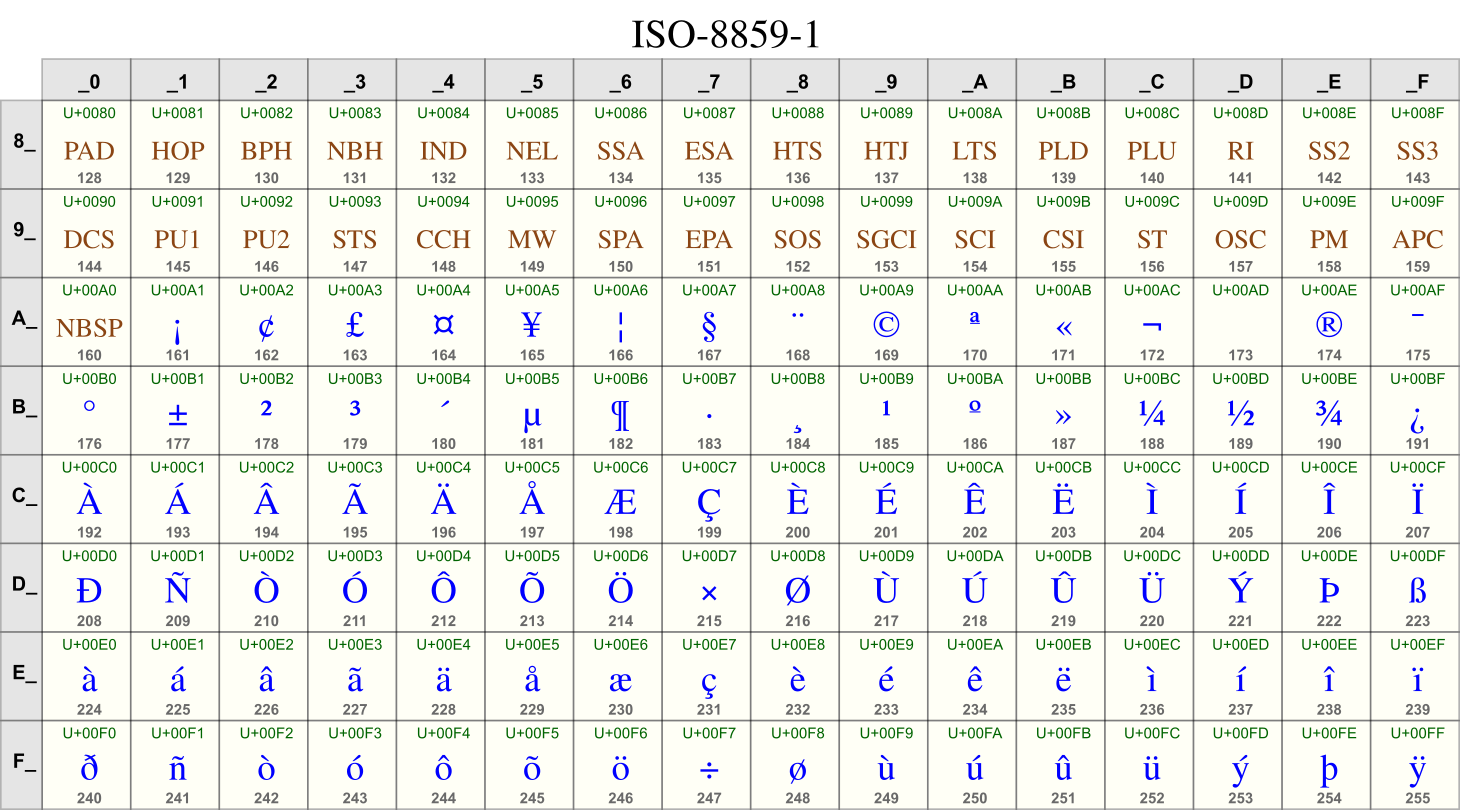
ISO 8859
- Can represent most texts for many Western languages
- The 7-bit subset agrees with ASCII
- Everyone can write C as intended!
- But not all Western languages are supported
- Different versions re-encode the upper 128 characters for other languages or scripts (Greek, Cyrillic)
- ISO 8859-1 becomes the most common and the default, but the choice of languages it represents seems odd to us
Ísland sigurinn
- Icelandic: supported by ISO 8859-1
Ỳ ỳ Þ þ Ð ð- ~360,000 speakers
- Turkish: not supported by ISO 8859-1
ı I (undotted I), i İ (dotted İ), ş Ş ğ Ğ- ~88,000,000 speakers!
- ISO 8859-9 replaces the Icelandic characters with the Turkish ones
- Still have ambiguity!
- Still unclear how to represent a text with both Icelandic and Turkish
- Metadata gives a different encoding for each byte range?
- Additional shift characters, as in telegraphy, change from language to language?
- No good choices
The panda in the room
- Hanzi
- Chinese logographs
- More than 50,000 in use!
- Hard to cram that into 128 bit patterns
Unicode: the dream
- Represent all the world’s languages in a single system
- Every character has one unambiguous encoding
- No ambiguity in interpretation
- Any text can contain fragments of any language without external metadata or internal shift patterns
Unicode 1
- 65,536 slots!
- Fixed-width two-byte encoding
- Enabled by “Han unification”
- Mapping of characters in different Hanzi national character sets into a set without duplicates
- Based on work by librarians and others: Taiwan’s Chinese Character Code for Information Interchange (CCCII); the Research Libraries Information Network’s East Asian Character Code (EACC); etc.
- Continued by a Unicode-convened Joint Research Group, working with experts from China, Japan, Korea (and now Vietnam, Taiwan) (reference)
- Representation problems
- Some scripts not included (Khmer, Mongolian, Cherokee)
- Some scripts excluded (historic scripts)
- Han unification successfully encoded most characters commonly used by people overall, but not some characters commonly used by particular people—such as characters for writing surnames!
Intense technical and social arguments
Have these people no shame?
This is what happens when a computing tradition that has never been able to move off ground-zero in associating 1 character to 1 glyph keeps grinding through the endless lists of variants, mistakes, rare, obsolete, nonce, idiosyncratic, and novel ideographs available through the millenia in East Asia.
I did not attend the meetings in which ISO 10646 was slowly turned into a de facto American industrial standard. I have read that the first person to broach the subject of "unifying" Chinese characters was a Canadian with links to the Unicode project. I have also read that the people looking out for Japan's interests are from a software house that produces word processors, Justsystem Corp. Most shockingly, I have read that the unification of Chinese characters is being conducted on the basis of the Chinese characters used in China, and that the organization pushing this project forward is a private company, not representatives of the Chinese government. … However, basic logic dictates that China should not be setting character standards for Japan, nor should Japan be setting character standards for China. Each country and/or region should have the right to set its own standard, and that standard should be drawn up by a non-commercial entity.
Unicode 2
- 1,114,112 slots!
- Non-fixed-width encoding
- Mapping and interpretation difficulties
- Waste
UTF-16
- Unicode Transformation Format, 16 bits
- Goal: Represent every character as a fixed width unit!
- Problem: Characters aren’t fixed width any more
- Problem: Economic harm!
- A large fraction of the world’s text can use a shorter encoding
- 16-bit encoding expands English texts by 2x
UTF-8
- Variable-width encoding for characters