
System calls on Linux
- In the
s03-linuxsubdirectory, look atquotes.ccand usegdbstep through the execution of./quotes(starting with a breakpoint onmain).- Use
nito step over function calls until you reachwrite@plt. Then switch tosi. - About five instructions in, you will see the
syscallinstruction. Step to that point but not over it. What does this look like? It looks like a call. This instruction is designed to call to the operating system. But that’s a really weird thing for an instruction to do. Do we need different instructions for different operating systems? How can we figure out what the semantics of this instruction are? How can we figure out its calling convention? - Examine the registers to figure out the calling convention for
syscall. Where are the arguments?- Linux x86-64 uses a calling convention for system calls that is
similar to, but not identical to, the normal Linux x86-64 calling
convention for function calls. The first, second, and third
arguments are passed in
%rdi,%rsi, and%rdx. So you’ll find the string in%rsi, for example. In addition—although you wouldn’t know this at first glance—the%raxregister stores a number identifying the system call. You could figure this out by noticing that thewrite@pltimplementation loads%raxwith a value before executingsyscall. That value is 1, which means “the system call I want to invoke iswrite”. Linux x86-64 system call calling convention; Linux has more than 300 different system calls.
- Linux x86-64 uses a calling convention for system calls that is
similar to, but not identical to, the normal Linux x86-64 calling
convention for function calls. The first, second, and third
arguments are passed in
- Now step into the
syscallinstruction’s implementation by executingsi. As with normal function calls, you might expect this to step into the operating system, allowing us to see exactly how the system call is implemented. - But that doesn’t work!! Instead, the message is printed to the standard output all at once.
- Use
Notes
- A student asked why we use
writeinstead ofputs. If you step throughputs, you’ll see that there’s far more library code invoked when you useputsorfwritethan when you usewrite. Though it’s hard to find, if you step carefully enough,putswill eventually execute awritesystem call.
System calls on WeensyOS
- In the
s03-weensyossubdirectory, look atp-quotes.cc. This is a version ofquotesthat runs on a tiny operating system that we wrote for you. - Use
make run(and/ormake run-console) to show thatp-quotes.cchas the same effect asquotes.cc.make runis actually emulating an entire computer, including processor, registers, primary memory, and various hardware devices, including a screen. - Now, try
make run-gdb. This boots the tiny operating system, waits a bit, then connectsgdbto the running emulated computer. We can now debug the whole emulated computer as if it were a single process (which, actually, it is). Let’s step up to, and then into, thesyscallinstruction to see if this helps our understanding.- Set a breakpoint on
waitand typec. This will run until the quotes process starts a delay loop. - Use
finishto exit the delay loop, then start stepping withni(no need to step intostrlenandrand—although if you’re curious, you might as well!). - About 10 instructions later is the
syscallinstruction. When you reach it, single-step usingsi. This steps into the kernel, starting at a weird function calledsyscall_entry!- Experiment: Try using
nitoo. What happens? Why?
- Experiment: Try using
- We can step into the OS because the computer is emulated. Any operating
system must protect itself from unauthorized intrusions, which could
disrupt its operation or steal its secrets, so normally a process like a
debugger can’t control how the kernel runs. But here, GDB is allowed to
control the entire emulated hardware, including the operating system
running on it, because that emulated hardware is fundamentally not
privileged: an unprivileged user chose to run that emulator.
- This is a powerful debugging mechanism that real operating system designers use!
- Even more than that, you can actually look deeply into the operation of the emulated machine by changing the emulator’s source code or running it with more debugging and logging options.
- Or you can experiment with new kinds of hardware by mocking implementations of that hardware in the emulator!
- If you
sienough, the characters in the quote will start appearing on the screen one at a time—as opposed to the Linux case, where the characters appeared all at once.- This is because at the level of hardware the screen is controlled one character at a time (using memory-mapped I/O to the CGA console, as we saw in class).
- Set a breakpoint on
Protection in Linux
- Change the
s03-linux/quotes.ccto passnullptrtowrite. What do you expect to happen? What actually happens?- Remove the
int ssize_t w =part ofquotes.cc. We get a warning about ignoring a return value. Hm! What is the return value? How can we find out?- The manual page!
- The kernel is protecting itself. The kernel must be very careful about
its inputs; it must carefully verify that the arguments passed in system
calls are valid—for instance, that they point to valid memory. If the
arguments are invalid, the behavior of the
writesystem call is that the system call returns -1 and an error indicator,errno, is set to a code defining the kind of error (here,EFAULT).- This also happens if you pass a random number for the string argument.
- Validate that the return value is -1, using GDB or an assertion.
- Remove the
Protection in WeensyOS
- Change back to
s03-weensyos/p-quotes.ccand passnullptrtosys_write. What happens?- A panic! This is a kind of error that indicates a serious problem with the kernel—the kernel is giving up. In a real operating system, it might then reboot.
- Why?
- Look at the error message!
- The kernel is dereferencing a pointer to memory that does not exist. That’s really bad, and the hardware freaks out.
- Show
log_printf(uncomment the instance at the beginning ofsyscallinkernel.cc) and explain what things likereg_ripdo.
- It’s bad to panic when a user process provides a bad argument. But we
control the kernel so we can make things better!
- What do you think we should do?
- We could check the argument in the implementation of
SYSCALL_WRITEin thesyscallfunction! - Or we could modify the
console_putsfunction that is called there! - Should we kill the process if it gives a bad pointer? Well, we can!
- Look at
kernel.hhand, specifically, theproc::statemember.
- Look at
Virtual memory
Virtual memory is the hardware mechanism that allows a kernel—which needs complete privilege over all operations of the machine, and must be protected at all costs—to run without inappropriate interference from user-level processes—which have no privilege and might have bugs.
- Where are a kernel’s instructions and data stored?
- Primary memory—and there’s only one.
- We need some way to partition primary memory so that some parts of it are inaccessible to unprivileged processes.
- Different operating systems have different memory layouts. For concreteness, let’s look at a specific layout, based on the one from WeensyOS. Here’s how “physical memory” might be laid out:
+-------------------------------------------------------------------------------+
| | Kernel data | | Unprivileged data | |
+-------------------------------------------------------------------------------+
^ ^
0x40000 0x100000- Brainstorm about how the kernel’s data can be protected from access by
unprivileged data. If this is too abstract, consider a specific instruction
for context, such as
movb (%rax), %bl. - One natural solution: segmentation.
- We add two secret, special-purpose registers to the machine, called segment base and segment size.
- A memory access is allowed only if the destination addresses a all between SEGBASE and SEGBASE + SEGSIZE: SEGBASE ≤ a < SEGBASE+SEGSIZE.
- Unprivileged user processes run with SEGBASE and SEGSIZE set to limit their access to their range.
- What happens when a system call occurs?
- The hardware must change the segment registers as part of the system call. This must be part of the processor’s defined behavior. This is because the first instruction that executes after the system call is in kernel memory—memory that’s not accessible to the process.
- Can unprivileged processes change their segment registers?
- This had better be illegal—or else processes could escape their jails at any time.
- It is safe, though, for a process to restrict its own privileges further. (How would this look?)
What are the problems with segmentation?
It’s inflexible. For example, a process may not be able to get more memory. Say, for example, that process
U1wants to allocate more heap memory from the operating system. If this is the current memory map:+-------------------------------------------------------------------------------+ |..........| K |..................| U1 |......................| +-------------------------------------------------------------------------------+ ^ ^ 0x40000 0x100000where the dots are free, then it’s safe to make U1 bigger and raise its SEGSIZE:
+-------------------------------------------------------------------------------+ |..........| K |..................| U1 |.................| +-------------------------------------------------------------------------------+ ^ ^ 0x40000 0x100000But what if another program, U2, was allocated close by?
+-------------------------------------------------------------------------------+ |..........| K |..................| U1 |..| U2 |........| +-------------------------------------------------------------------------------+ ^ ^ 0x40000 0x100000U1 and U2 have different segment register values when they run—U2’s data should be inaccessible to U1, and vice versa. Unfortunately, now U1’s ability to grow is limited by the nearby placement of U2. You’d think U1 could use other free memory, but we’ve assumed that only one segment exists per process, so a process’s memory must be contiguous!
Can you brainstorm a better idea?
- We need another layer of indirection.
- That layer of indirection is called virtual memory. (Though strictly speaking segmentation is a kind of primitive virtual memory.)
- The purpose of that layer is to divorce the addresses visible to process instructions from the addresses in physical memory. A flexible mapping between addresses visible to processes and physical memory chips will avoid problems like requiring processes to have contiguous memory.
- How might this look? On x86-64, virtual memory is implemented with an interesting tree data structure you’ll see in class; but at a high level, how would you make it work?
We want a flexible mapping between the addresses visible to processes, which we’ll call virtual addresses, and the addresses corresponding to physical memory chips. Let's implement that mapping by allowing different ranges of virtual memory to map to different ranges of physical memory.
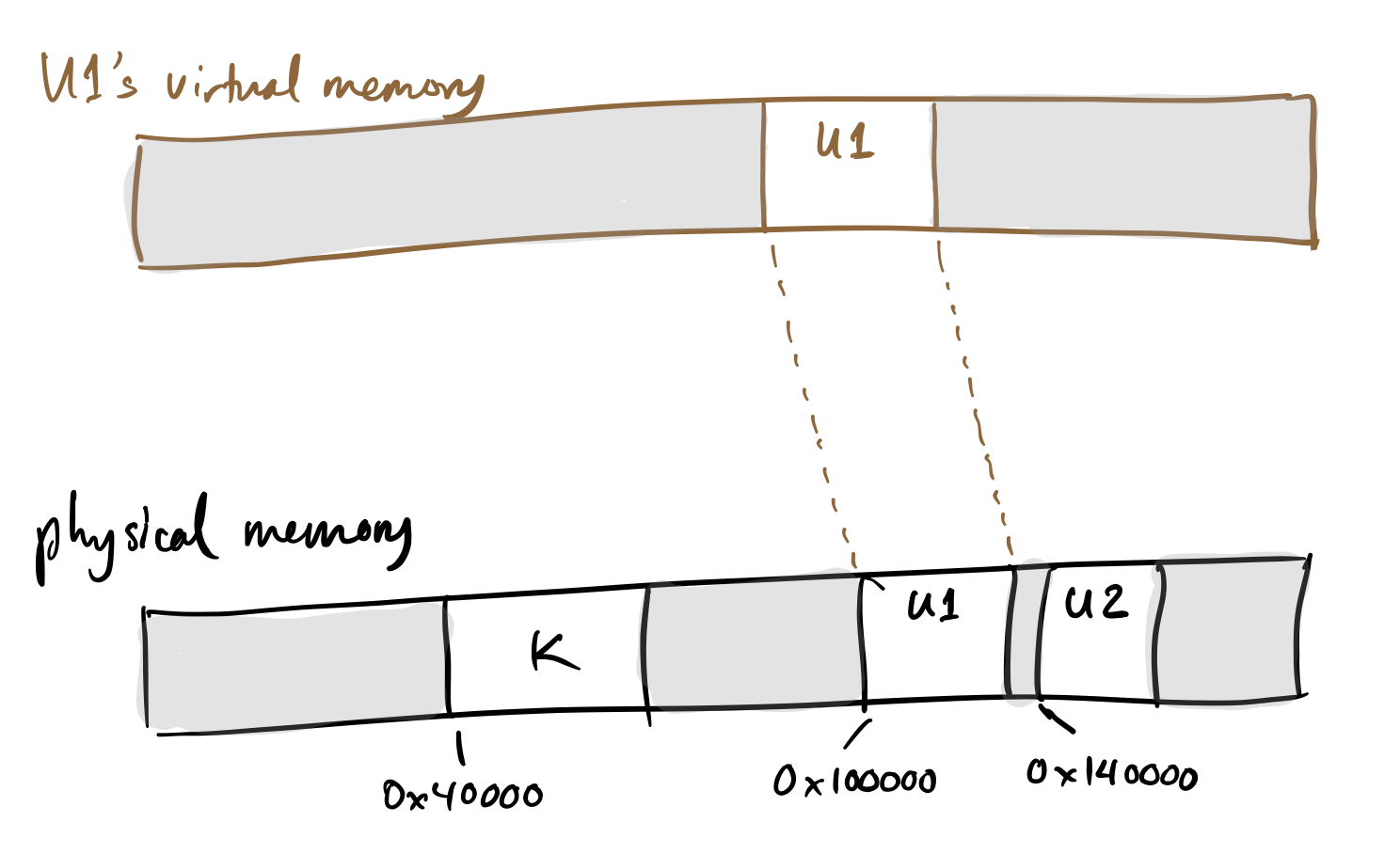
Since different processes have different permissions to access memory, they must have different virtual address spaces. For example, here’s a view of memory with two processes:
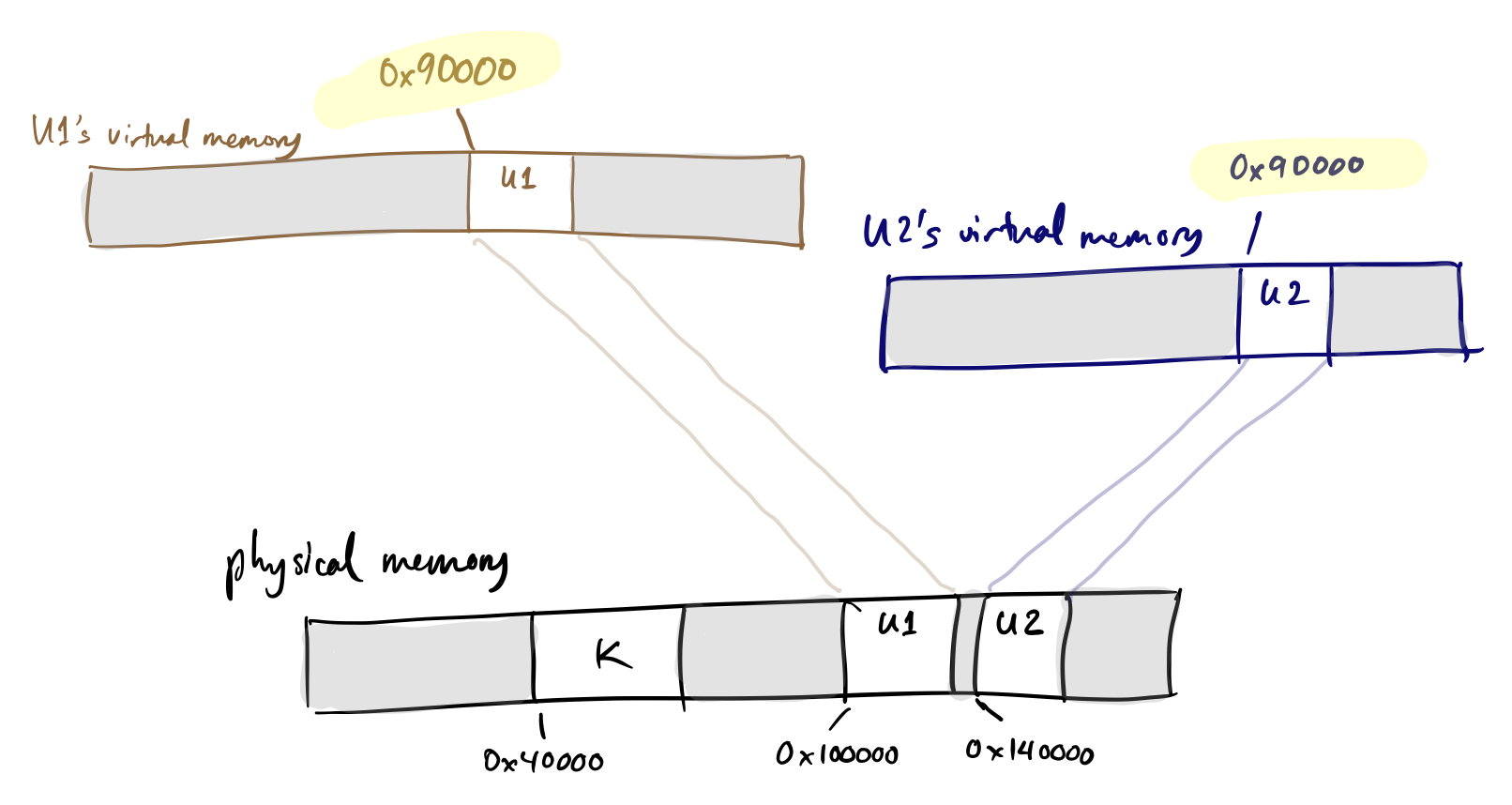
Note that the addresses in these different address spaces can differ from physical addresses, and in fact, the same virtual address, when accessed in different processes, can refer to different physical memory!
Now, if U1 wants to grow, it doesn’t matter that U2 is restricting its growth in contiguous physical memory. The kernel can allocate U1 new physical memory from anywhere, but make it appear contiguous to U1 by arranging mappings carefully.
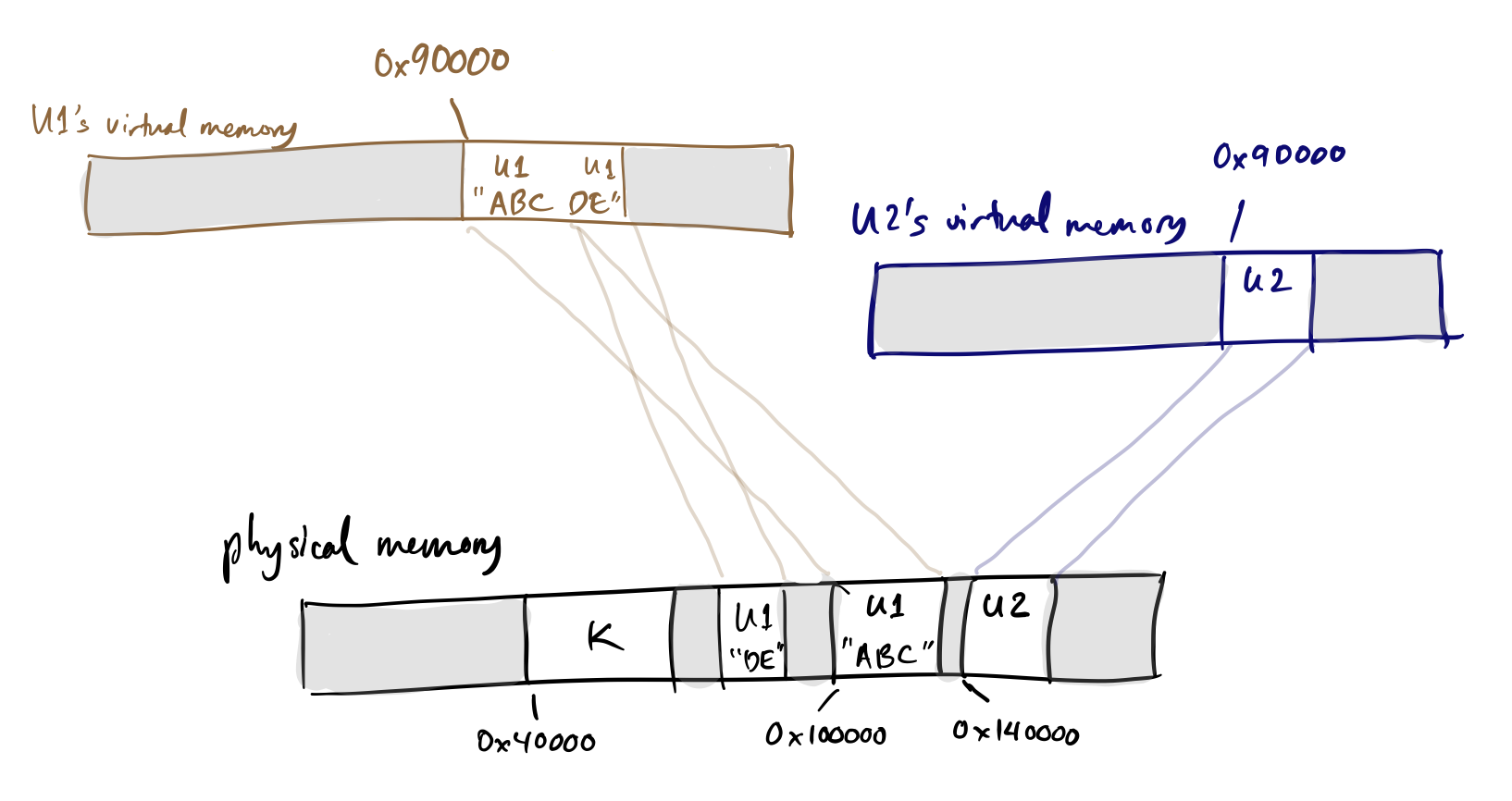
In practice, the kernel also accesses memory using virtual memory, but in WeensyOS it uses identity mappings to do so, meaning that virtual address A using the kernel’s page table always maps to physical address A.
- Real OSes, and more advanced teaching OSes like CS 161’s, will use virtual memory more extensively even in the kernel—kernel page tables don’t need to just contain identity mappings.
How would you implement this range mapping function in data structure terms? Brainstorm! What are some consequences of your different choices?
Memory iterators (advanced material)
We didn’t get to this material on Monday because we weren’t prepared for it in class.
The pset for this unit asks you to add to WeensyOS, an operating system that we’ll use in this course. WeensyOS has internal interfaces for dealing with virtual memory that we’ll now discuss.
vmiter and ptiter are iterators in WeensyOS for processing page tables.
Vmiter helps iterate through pages in virtual memory, and lets you check the
underlying physical pages for properties like permissions and physical
addresses. Ptiter helps you iterate through page table pages. Let’s walk
through the code:
Vmiter
The vmiter class represents an iterator over virtual memory mappings. Here
is its interface:
// `vmiter` walks over virtual address mappings.
// `pa()` and `perm()` read current addresses and permissions;
// `map()` installs new mappings.
class vmiter {
public:
// initialize a `vmiter` for `pt` pointing at `va`
inline vmiter(x86_64_pagetable* pt, uintptr_t va = 0);
inline vmiter(const proc* p, uintptr_t va = 0);
inline uintptr_t va() const; // current virtual address
inline uint64_t pa() const; // current physical address
inline void* kptr() const; // pointer to physical address
// The return value from `kptr()` can be dereferenced in the kernel.
// Call `kptr<int*>()` to get an `int*` pointer instead of `void*`.
inline uint64_t perm() const; // current permissions
inline bool present() const; // is va present?
inline bool writable() const; // is va writable?
inline bool user() const; // is va user-accessible (unprivileged)?
inline vmiter& find(uintptr_t va); // change virtual address to `va`
inline vmiter& operator+=(intptr_t delta); // advance `va` by `delta`
// map current va to `pa` with permissions `perm`
// Current va must be page-aligned. Calls kalloc() to allocate
// page table pages if necessary. Panics on failure.
void map(uintptr_t pa, int perm);
// like `map`, but returns 0 on success and -1 on failure
int try_map(uintptr_t pa, int perm);
};
This type parses x86-64 page tables and manages virtual-to-physical address
mappings. vmiter(pt, va) creates a vmiter object that’s examining virtual
address va in page table pt. Methods on this object can return the
corresponding physical address:
x86_64_pagetable* pt = ...;
uintptr_t pa = vmiter(pt, va).pa(); // returns uintptr_t(-1) if unmapped
Or the permissions:
if (vmiter(pt, va).writable()) {
// then `va` is present and writable (PTE_P | PTE_W) in `pt`
}
It’s also possible to use vmiter as a loop variable, calling methods
that query its state and methods that change its current virtual address. For
example, this loop prints all present mappings in the lower 64KiB of memory:
for (vmiter it(pt, 0); it.va() < 0x10000; it += PAGESIZE) {
if (it.present()) {
log_printf("%p maps to %p\n", it.va(), it.pa());
}
}
This loop goes one page at a time (the it += PAGESIZE expression increases
it.va() by PAGESIZE).
The vmiter.map() function is used to add mappings to a page table. This
maps physical page 0x3000 at virtual address 0x2000:
int r = vmiter(pt, 0x2000).map(0x3000, PTE_P | PTE_W | PTE_U);
// r == 0 on success, r < 0 on failure
Ptiter
class ptiter {
public:
// initialize a `ptiter` for `pt` pointing at `va`
inline ptiter(x86_64_pagetable* pt, uintptr_t va = 0);
inline ptiter(const proc* p, uintptr_t va = 0);
inline uintptr_t va() const; // current virtual address
inline uintptr_t last_va() const; // one past last va covered by ptp
inline bool active() const; // does va exist?
inline x86_64_pagetable* kptr() const; // current page table page
inline uintptr_t pa() const; // physical address of ptp
// move to next page table page in depth-first order
inline void next();
};
ptiter visits the individual page table pages in a multi-level page table,
in depth-first order (so all level-1 page tables under a level-2 page table
are visited before the level-2 is visited). A ptiter loop makes it easy to
find all the page table pages owned by a process, which is usually at least 4
page tables in x86-64 (one per level).
for (ptiter it(pt, 0); it.va() < MEMSIZE_VIRTUAL; it.next()) {
log_printf("[%p, %p): ptp at pa %p\n",
it.va(), it.last_va(), it.pa());
}
A WeensyOS process might print the following:
[0x0, 0x200000): ptp at pa 0xb000
[0x200000, 0x400000): ptp at pa 0xe000
[0x0, 0x40000000): ptp at pa 0xa000
[0x0, 0x8000000000): ptp at pa 0x9000Note the depth-first order: the level-1 page table pages are visited first,
then level-2, then level-3. Because of this order (and other implementation
choices), a ptiter loop may be used to free a page table—for instance, when
you’re implementing process exit later :)
ptiter never visits the top level-4 page table page, so that will need to be
freed independently of the ptiter loop.
Using iterators
On this problem set, you will implement some of the
system calls in WeensyOS. Two of the main system calls that you will
implement are fork() and exit().
The fork system call allows a process to spawn a child process that is essentially a copy of the parent process. The child process has a copy of the parent processes’ memory, and after the new child process created, both processes execute the next instruction after fork(). The registers and file descriptors are also copied.
The exit system call allows a process to stop its execution. All of the memory belonging to that process, including its page table pages, are returned to the kernel for reuse.
The Lifecycle of a Process
A process: the singular unit of life in an operating system. When a new process is born, it needs its own page table pages, which it gets from its parent. For processes not born from a
fork()call, this parent is the kernel, and thus, the process's page table pages will be a copy of the kernel's.During the normal execution of a process, it refers to memory addresses by their virtual memory addresses -- which means that, to actually access the underlying memory, those virtual memory addresses need to be translated into physical addresses. Fortunately, you have just learned about the basic mechanism behind this process. ;)
Once a process has completed its run, there is some cleanup to be done -- namely, the relinquishment of its virtual memory mappings. First, the process needs to disassociate itself from the kernel's page table pages -- an
exited process shouldn't need them anymore, anyway. Next, the process needs to tell the kernel that it is no longer using its page table pages -- this is not just the level-1 page table pages, but also the higher-level ones as well! Finally, the process can rest in peace. RIP.
QUESTION: Use vmiter to implement the following function.
void copy_mappings(x86_64_pagetable* dst, x86_64_pagetable* src) {
// Copy all virtual memory mappings from `src` into `dst`
// for addresses in the range [0, MEMSIZE_VIRTUAL).
// You may assume that `dst` starts out empty (has no mappings).
// After this function completes, for any va with
// 0 <= va < MEMSIZE_VIRTUAL, dst and src should map that va
// to the same pa with the same permissions.
}
QUESTION: Use vmiter and ptiter to implement the following function.
void free_everything(x86_64_pagetable* pt) {
// Free the following pages by passing their physical addresses
// to `kfree()`:
// 1. All memory accessible by unprivileged mappings in `pt`.
// 2. All page table pages that are part of `pt`.
}