
Open up a new terminal window on your computer. Congratulations, you’ve opened up a UNIX Shell (unless you opened Command Prompt)! So far, you’ve used this wonderful utility to run around your filesystem, possibly open some code, build your pset, and/or play around with Git. Isn’t it magical? Its builders must’ve been geniuses.
Fortunately, you too are a genius, because you will be implementing a (slightly simpler) shell for pset 5. That is, you’ll learn The Inner Life of a Shell. The UNIX shell is an interesting work of art, but deep down, it just parses the input you type, forks subprocesses to run the resulting commands, waits for some of those processes to finish, and subsequently execute the next commands. In pset 5, you will be given the rudimentary tools to parse the command line input and some shell code to get you started. You will:
- Use
fork()to create subprocesses, useexec()to load the program’s code, and examine the output ofexit()to determine the “success” of the execution. - Interpret command line syntax to emulate more complex behavior, e.g.
a && bwill only runbifais successful. - Use pipes to direct input to and output from a program.
This section helps you get familiar with shells by writing short shell
programs. It also introduces you to BNF grammars, a notation technique
used to precisely describe languages, such as valid command lines; and
describes some implementation choices your shell will face. The shell
exercises are in the s07 directory of the cs61-sections repository. Refer
to the shell descriptions at the bottom of these section notes to
complete these exercises.
Warmup exercise
Exercise A: Use only shell commands to print the contents
of file1.txt and file2.txt into the console, in
that order.
cat file1.txt file2.txt
Process I/O and redirections
As you saw in pset 4, I/O is very important, and UNIX implements I/O using
file descriptors. By convention, file descriptor 0 is
used for programs’ standard input (STDIN or std::cin), 1 for standard
output (STDOUT or std::cout), and 2 for standard error (STDERR or
std::cerr). Of these, 0 is often open only for reading, while 1 and 2 are
often open only for writing. (Although when you run a program at a terminal
prompt, all three file descriptors often point at the same stream file, the
“keyboard/console”.)
How, then, are the standard input, output, and error created, handled, and
used? Remember that they’re simply file descriptors, so the strace output
you looked at in pset 4, including the read and write syscalls, can be
used for this purpose.
The standard input, output, and error file descriptors are typically set up for a process before the process begins. That is, these file descriptors form part of the process’s initial environment. Once a process starts running, its environment is primarily under its control—for instance, a process can close its own standard input if it wants to. But it’s possible to set up a process’s initial environment before the process begins.
Shell redirections change a process’s initial environment by associating
its standard input, output, and/or error with files, rather than the console.
For example, these two commands execute identical write system calls:
echo hello kitty
echo hello kitty > cs61.txtBut in the first case, hello kitty is printed to the terminal, and in the
second, hello kitty is saved to a file named cs61.txt in the current
directory. (You can verify this with ls and less cs61.txt.)
Exercise: Use strace to verify that the write system calls are in fact
identical.
Example
stracecommand lines:strace -o s1.out echo hello kitty strace -o s2.out echo hello kitty > cs61.txtBoth commands execute
write(1, "hello kitty\n", 12), and neither output mentions the filecs61.txtby name.
Exercise B: What effects do these two commands have? Which file descriptors are read and written in both cases?
echo hello kitty > cs61.txt
cat < cs61.txtThe first line writes
hello kittytocs61.txt. The second line readscs61.txtand writes its contents to the console.
Exercise: Which file descriptors are read and written in both cases?
echoreads nothing and writes standard output, whilecatreads standard input and writes standard output. (If you verify this withstrace, you’ll see that both programs read other file descriptors corresponding to the process initialization procedure, such as/etc/ld.so.cacheand/usr/lib/locale/locale-archive.)
Exercise: Which file descriptor does the < operator redirect?
Standard input.
Exercise: Will the following commands produce different output than those in Exercise B? Will they access different file descriptors?
echo hello kitty > cs61.txt
cat cs61.txtThey will produce the same output, but in the second example,
catwill explicitly open thecs61.txtfile. It reads file descriptor 3, which corresponds tocs61.txt, and does not read standard input.
Kinds of redirection
<redirects standard input and>redirects standard output.
>will truncate the file if it already exists (this means it initially sets the file to zero length).>>is like>, but will append to the file if it already exists.
2> sometxtmeans “redirect file descriptor 2 to sometxt for writing.” Note that there is no space between2and>.
2>&1means “make file descriptor 2 point to the same file structure as file descriptor 1.” This causes writes to standard error to be redirected to standard output. Again, note that there is no space between>and&.
The purpose of
2>&1The
2>&1idiom can be very useful for commands that generate a ton of errors. For example, considermanyerrors.sh, which generates output for both standard output and standard error. Then compare how the following commands behave (use Control-C to quit if things seem out of hand).sh manyerrors.sh sh manyerrors.sh | less sh manyerrors.sh 2>&1 | less
Exercise: Repeat Exercise A, but store the result in a file called
cs61.txt.
cat file1.txt file2.txt > cs61.txt
Exercise: Do it again, but with a different sequence of commands.
cat file1.txt > cs61.txt cat file2.txt >> cs61.txtThere’s an infinite number of possibilities.
Exercise C: Write a sequence of commands that
prints the names of the two files in the current directory that come last in
alphabetical order. For example, in a directory with files named
a through z, you should print
z
yUse redirections, not use pipes (pipes show up in the next section).
ls > a1.txt sort -r < a1.txt > a2.txt head -n 2 < a2.txt
BNF grammars
The input language for sh61 command lines is described in terms of a BNF
grammar, where BNF stands for Backus–Naur Form, or Backus Normal Form.
BNF is a declarative notation for describing a language, where a language
is a set of strings. (Specifically, BNF can describe any context-free
language.) BNF notation consists of three pieces:
- Terminals, such as
"x", are strings of characters that must exactly match characters in the input. - Nonterminals (or symbols for short), such as
lettera, represent sets of strings. One of the nonterminals is called the root or start symbol of the grammar. By convention, the root is the first nonterminal mentioned in the grammar. - Rules, such as
lettera ::= "a"orword ::= letter word, define how nonterminals and strings relate.
A string is in the language if it can be obtained by following the rules of the grammar starting from a single instance of the root symbol.
Here’s an example grammar that can recognize exactly two sentences, namely
"cs61 is awesome" and "cs61 is terrible":
cs61 ::= "cs61 is " emotionword
emotionword ::= "awesome" | "terrible"It’s useful to be able to read BNF grammars because they’re ubiquitous in computer science and programming. Many specification documents use BNF to define languages, whether programming languages or even languages of network packet formats.
We’ll describe the features of BNF grammars using simple examples. Peek at some answers and then try to answer the questions on your own.
Exercise: Define a grammar for the empty language, which is a language containing no strings. (There is no valid sentence in the empty language.)
shutup ::=This grammar has one nonterminal, the root symbol
shutup. The::=notation has nothing on the right, indicating that no string will matchshutup.
Exercise: Define a grammar for the children language (because children should be “not heard”). The empty string is the only valid sentence in this language.
children ::= ""Note the difference between
childrenandshutup. Theshutuplanguage contains no sentences: no string is valid in this language, not even the empty string. Thechildrenlanguage contains one sentence: the empty string""is valid.
Exercise: Define a grammar for the letter language. A letter is a
lower-case Latin letter between a and z.
letter ::= "a" | "b" | "c" | "d" | ... | "z"The
|symbol indicates alternate choices for the rule’s definition. It’s actually shorthand for multiple rules for the same nonterminal:letter ::= "a" letter ::= "b" letter ::= "c" letter ::= "d" ... letter ::= "z"
Exercise: Define a grammar for the word language. A word is a sequence
of one or more letters. You may refer to the letter nonterminal defined
above.
word ::= letter | word letterThis grammar features a recursive rule! Why is
"butt"a valid sentence in this language? Well:
"b"is aword(a sentence in the word language) because it is aletter. (This uses the first alternative,word ::= letter.)"bu"is awordbecause"b"is a word (see above) and"u"is a letter. (This uses this second alternative,word ::= word letter.)"but"is awordbecause"bu"is a word and"t"is a letter."butt"is awordbecause"but"is a word and"t"is a letter.
Exercise: Define two different grammars for the word language.
word1 ::= letter | word1 letter word2 ::= letter | letter word2 word3 ::= letter | word3 word3Each of these grammars recognizes the same language: every string that matches the
word1nonterminal matchesword2andword3, and every string that doesn’t matchword1doesn’t matchword2orword3either.It is possible to prove that these simple grammars recognize the same language, but in general, testing whether two context-free grammars recognize the same language is undecidable! There is no algorithm that can reliably report whether two grammars are effectively the same. If this blows your mind (and it should), take CS121.
Exercise: Define a grammar for the parenthesis language, where all sentences in the parenthesis language consist of balanced pairs of left and right parentheses. Some examples:
| Valid | Invalid |
|---|---|
() |
())( |
(()) |
( |
()() |
)( |
(((()())()())) |
))))))))))( |
An important question is, is the empty string a valid sentence in this language? Let’s say yes. Then this works:
parens ::= "(" parens ")" | parens parens | ""Note that the following subset grammar accepts no finite strings:
parens2 ::= "(" parens2 ")"This is because this recursion has no base case. (You could argue that the infinite string consisting of an infinite number of
(s, followed by an infinite number of)s, would match the grammar, but also you could argue that it would not, because infinity is weird.)The balanced parenthesis language is context-free, but not regular. In practical terms, this means that no regular expression can recognize the language. Regular expressions are too limited to remember a nesting depth.
The shell grammar
This is the BNF grammar for sh61, as found in problem set 5. (Note that this
grammar doesn’t define words, and doesn’t define where whitespace is
required. That kind of looseness is typical in systems grammars; in your
case helpers.cc already implements the necessary rules.)
commandline ::= list | list ";" | list "&" list ::= conditional | list ";" conditional | list "&" conditional conditional ::= pipeline | conditional "&&" pipeline | conditional "||" pipeline pipeline ::= command | pipeline "|" command command ::= word | redirection | command word | command redirection redirection ::= redirectionop filename redirectionop ::= "<" | ">" | "2>"
The recursive definitions allow for lists or trees of terms to be chained
together. Taking list as an example:
list ::= conditional | list ";" conditional | list "&" conditional
This reads “a list is a conditional, or a list followed by a semicolon and
then a conditional, or a list followed by an ampersand and then a
conditional.” But this means that the list is just a bunch of
conditionals, linked by semicolons or ampersands! Notice that the other
recursive definitions in sh61’s grammar also follow this pattern. In other
words:
- A
listis a series ofconditionals, concatenated by;or&. - A
conditionalis a series ofpipelines, concatenated by&&or||. - A
pipelineis a series ofcommands, concatenated by|. - A
redirectionis one of<,>, or2>, followed by afilename.
We’ve explicitly written out the definition of command, but it would be
common to see this written in shorthand such as
command ::= [word or redirection]...So a command is a series of words representing the program name and its arguments, interspersed with redirection commands.
Command line representation
The shell grammar makes the underlying hierarchical structure of command lines explicit and clear. The overall structure of a line, as described by the grammar, is:
- A
listis composed ofconditionals joined by;or&(and the lastcommandin thelistmight or might not end with&). - A
conditionalis composed ofpipelines joined by&&or||. - A
pipelineis composed ofcommands joined by|. - A
commandis composed ofwords andredirections.
So lists are comprised of conditionals, which are comprised of
pipelines, which are comprised of commands. But must this structure be
reflected in your implementation?
There are two common ways to represent our parsed command line in a data structure appropriate for our shell, a tree representation and a list representation. Students often are biased toward the tree representation, which precisely represents the structure of the grammar, but the list representation can be easier to handle! The tradeoff is simplicity vs. execution time: the list representation requires more work to answer some questions about commands, but command lines are small enough in practice that the extra work doesn’t matter.
Tree representation
The following tree-formatted data structure precisely represents this grammar structure.
- A
commandcontains its executable, arguments, and any redirections. - A
pipelineis a linked list ofcommands, all of which are joined by|. - A
conditionalis a linked list ofpipelines. But since adjacentconditionals can be connected by either&&or||, we need to store whether the link is&&or||. - A
listis a linked list ofconditionals, each flagged as foreground (i.e., joined by;) or background (i.e., joined by&). Note that while theconditionallink type doesn’t matter for the last pipeline in aconditional, the background flag does matter for the lastconditionalin alist, since the lastconditionalin alistmight be run in the foreground or background.
For instance, consider this tree structure for a command line (the words and
redirections that are there, but not being shown for the sake of simplifying
the image somewhat):
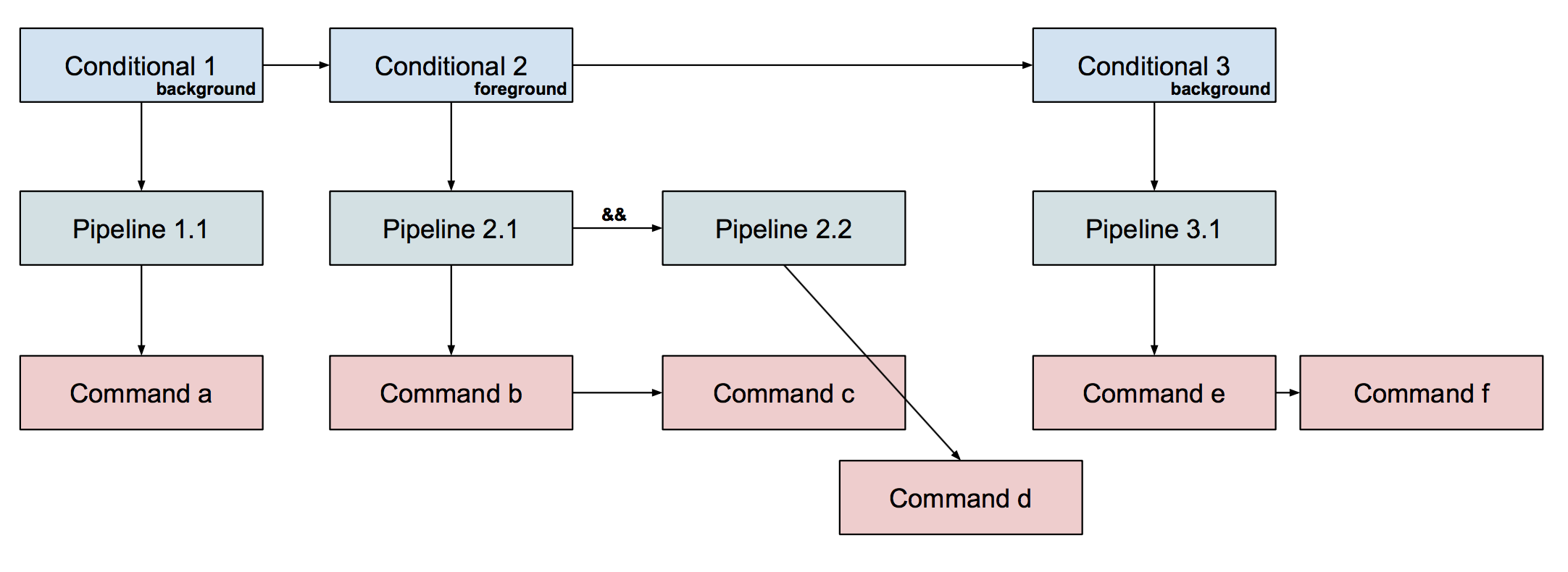
Exercise: Assuming that a, b, c, d, e, and f are distinct
commands, what could be a command line that would produce this tree structure?
a & b | c && d ; e | f &
Exercise: Sketch a set of C++ structures corresponding to this design.
Here’s one:
struct command { std::vector<std::string> args; command* command_sibling = nullptr; }; struct pipeline { command* command_child = nullptr; pipeline* pipeline_sibling = nullptr; bool is_or = false; }; struct conditional { pipeline* pipeline_child = nullptr; conditional* conditional_sibling = nullptr; bool is_background = false; };There are many other solutions. Logically, we need a struct for conditional chains that indicates whether the chain should be run in the foreground or background; a struct for pipelines; and a struct for commands. Each struct needs to hold the necessary pointers to form a linked list of siblings. Furthermore, conditionals and pipleines need a pointer to the first item of their sublists.
Exercise: Given a C++ structure corresponding to a conditional chain, explain how to tell whether that chain should be executed in the foreground or the background.
For our solution, that’s as simple as
c->is_background.
Exercise: Given a C++ structure corresponding to a command, how can one determine whether the command is on the left-hand side of a pipe?
For our solution, a command
cis on the left-hand side of a pipe iffc->command_sibling != nullptr.
Exercise (left to the reader): Given a C++ structure corresponding to a command, how can one determine whether the command is on the right-hand side of a pipe?
Linked list representation
Alternatively, we can create a single linked list of all of the commands. In
this case, we also store the connecting operator (one of & ; | && or
||). For our example command line above, the flat linked list structure might
look something like:
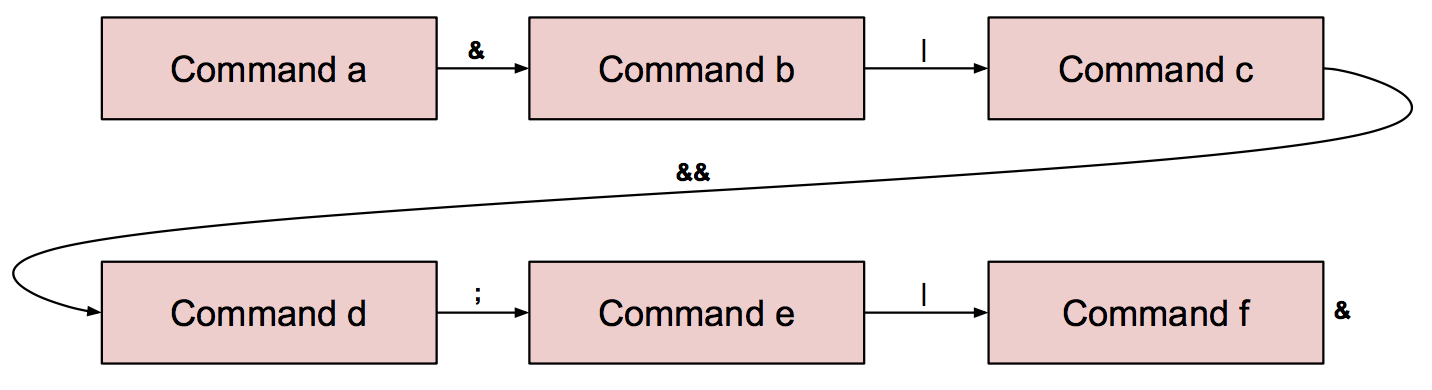
Again, this is the structure we recommend (we don’t require it). Traversing this structure is slightly more time-consuming than in the tree representation, but the structure is much easier to build, and the additional CPU time spent traversing it is in the noise given how short command lines typically are.
Exercise: Write a set of C++ structures corresponding to this design.
Here’s an example:
struct command { std::vector<std::string> args; command* next = nullptr; int link = TYPE_SEQUENCE; // Operator following this command. // Always TYPE_SEQUENCE or TYPE_BACKGROUND for last in list. };Much simpler!
Another good one, with fewer pointers and thus fewer opportunities for memory mistakes, but harder to traverse (you need C++ iterators):
struct command { std::vector<std::string> args; int op; // as above }; using command_list = std::list<command>;
Exercise: Given a C++ structure corresponding to a conditional chain, explain how to tell whether that chain should be executed in the foreground or the background.
bool chain_in_background(command* c) { while (c->op != TYPE_SEQUENCE && c->op != TYPE_BACKGROUND) { c = c->next; } return c->op == TYPE_BACKGROUND; }Things are slightly more complicated with a flat linked list. We are still executing commands sequentially, but some subsequences of commands may need to be executed in the foreground or the background. During parsing, we can skip ahead in the command line to find the end of our current list (i.e., our current chain of conditionals).
Exercise (left to the reader): Given a C++ structure corresponding to a command, how can one determine whether the command is on the left-hand side of a pipe?
Exercise (left to the reader): Given a C++ structure corresponding to a command, how can one determine whether the command is on the right-hand side of a pipe?
Exercise (left to the reader): Sketch out code for parsing a command line into these C structures.
Pipes
Having covered grammars and the different representation choices available for command lines, we return to examples of shell programlets.
Exercise: The following command line contains one pipe. What does it do?
ls | head -n 2It prints the first two items listed in the output of
ls.
Exercise: Repeat Exercise C using pipes.
ls | sort -r | head -n 2Much nicer than redirecting to and from files, and it leaves less garbage around.
Pipes take information from one process and spit it into another. Pipes also
have another distinct advantage: in command1 | command2, command2 can
start working on the output of command1 before command1 has fully
completed!
Question: How many pipes can be chained together in one line? Can you find a limit?
Technically, there’s no fixed limit, but in practice operating systems impose limits on the total number of file descriptors allowed, shells impose limits on the length of command lines, and there are RAM and CPU limits.
A sequence of one or more processes, connected by pipes, is called a pipeline. (A single process is a trivial pipeline.)
Use only shell commands to complete the following tasks. Refer to the the shell descriptions to help you find and use the proper shell utilities.
Exercise: Count the number of lines in the file words (and print the count).
wc -l words
Exercise: Print every unique line in the file words exactly once.
sort -u words
Exercise: Count the number of unique lines in the file words (and print the count).
sort -u words | wc -l
Exercise: Write a command that could help you discover whether a shell really executes the two sides of a pipeline in parallel. Describe the result if (1) the shell executed the left side to completion first (and buffered the output for the right side to read), (2) the shell executed the sides in parallel.
Any number of solutions, but
sleep 10 | echo foois a classic one. If the pipeline is executed left-to-right with intermediate buffering, we’d see nothing printed for 10 seconds while thesleepcounted down, then we might seefooprinted afterward. If the pipeline is indeed executed in parallel, then we’d seefooprinted immediately instead.
Putting commands together
Pipes aren’t the only way to put commands together! Shells also allow us to run commands in sequences called command lists. And some of those ways let us detect and respond to failures.
First, the ; operator says “run this, then run that.” The semicolon waits for the left-hand
command to complete. Then it executes the right-hand command.
Exercise: Write a single shell command list that repeats Exercise A, but runs two separate commands in a single command list.
cat file1.txt > cs61.txt ; cat file2.txt >> cs61.txt
Now, shell commands, and processes in general, can either succeed or fail. A process indicates
its status when it exits by passing an integer (between 0 and 255) to the exit() library function. By convention,
the zero status indicates success, and all non-zero statuses indicate failure. That is, successful
processes are all alike; every failing process fails in its own way.
The
exitlibrary function is a wrapper around the_exitsystem call. Most programs will callexit, which takes care of important cleanup tasks such as flushing standard I/O buffers. In your shell, however, you will call_exit.
To test different statuses, we often use the true and false programs.
true just exits with successful status: exit(0). false just exits with
the unsuccessful status 1: exit(1). If you’re feeling verbose, you can say
exit(EXIT_SUCCESS) and exit(EXIT_FAILURE) instead.
Exercise: Write C++ code that compiles to a program equivalent to true.
#include <cstdlib> int main() { exit(0); }
Exercise: Write C++ code that compiles to a program equivalent to false, but don’t call exit explicitly.
int main() { return 1; }
In well-written programs, errors that cause the program to exit should cause a failing exit status. For instance,
cat will fail if it is passed a nonexistent file.
Exit status is commonly checked by the shell && and || operators. These are like ;—they execute the left-hand
command first, then turn to the right-hand command—but unlike ;, they check the status of the left-hand
command, and only run the right-hand command if the left-hand command has an expected status.
Exercise: Use true, false, and echo to figure out what statuses && and || expect.
The
&&operator executes the right-hand command if the left-hand command succeeds. The||operator executes the right-hand command if the left-hand command fails. We might figure that out with commands like this:true && echo left side succeeded 1 false && echo left side failed 2 true || echo left side succeeded 3 false || echo left side failed 4That will print:
left side succeeded 1 left side failed 4
In command lists with multiple conditionals, the conditionals run left to right.
Exercise: What status does false && echo foo return? Use more conditionals to figure it out.
It returns the status of
false, which is 1.false && echo foo || echo barandfalse && echo foo && echo quuxwould help you figure out thatfalse && echo foohas a failing exit status; you’d have to use other features, such as$?, to figure out the exact status.
Exercise: Run and print the numerical exit status of true to the shell. (If you’re working
through on your own, read manual pages here, or look below at our documentation.)
true; echo $?
More exploration
In lecture, we discussed some of the shell utilities—if you’d like to discover more and have more practice with them, here are some exercises to help you along your way.
Use only shell commands to complete the following tasks.
Exercise: Run and print the exit status of false to the shell.
false; echo $?
Exercise: Print the exit status of curl http://ipinfo.io/ip to the shell.
curl http://ipinfo.io/ip; echo $?
Exercise: curl a URL and print Success if the download succeeds, or Failure if
the download fails.
curl lcdf.org && echo "Success" || echo "Failure"
Exercise: Do it again, but store the downloaded result in a file called ip.
curl lcdf.org > ip && echo "Success" || echo "Failure"
Documentation and References
Feel free to refer to these during section and as you work on pset 5.
Useful shell utilities
Here are some commonly-installed, commonly-used programs that you can call
directly from the shell. Documentation for these programs can be accessed via
the man page, e.g. man cat, or often also through a help switch, e.g.
cat --help.
| Shell Program | Description |
|---|---|
cat |
Write standard input to standard output. |
wc |
Count lines, words, and characters in standard input, write result to standard output. |
head -n N |
Print first N lines of standard input. |
tail -n N |
Print last N lines of standard input. |
echo ARG1 ARG2... |
Print arguments. |
printf FORMAT ARG... |
Print arguments with printf-style formatting. |
true |
Always succeed (exit with status 0). |
false |
Always fail (exit with status 1). |
sort |
Sort lines in input. |
uniq |
Drop duplicate lines in input (or print only duplicate lines). |
tr |
Change characters; e.g., tr a-z A-Z makes all letters uppercase. |
ps |
List processes. |
curl URL |
Download URL and write result to standard output. |
sleep N |
Pause for N seconds, then exit with status 0. |
cut |
Cut selected portions of each line of a file. |
sh61 shell subset
For pset 5, you will be expected to implement a subset of common UNIX shell features. Try a few of them now, and start thinking about how you might consider implementing them!
| Syntax | Description |
|---|---|
command1 ; command2 |
Sequencing. Run command1, and when it finishes, run command2. |
command1 & command2 |
Backgrounding. Start command1, but don’t wait for it to finish. Run command2 right away. |
command1 && command2 |
And conditional. Run command1; if it finishes by exiting with status 0, run command2. |
command1 || command2 |
Or conditional. Run command1; if it finishes by exiting with a status ≠ 0, then run command2. |
command1 | command2 |
Pipe. Run command1 and command2 in parallel. command1’s standard output is hooked up to command2’s standard input. Thus, command2 reads what command1 wrote. The exit status of the pipeline is the exit status of command2. |
command > file |
Standard output redirection. Run command with its standard output writing to file. The file is truncated before the command is run. |
command < file |
Standard input redirection. Run command with its standard input reading from file. |
command 2> file |
Standard error redirection. Run command with its standard error writing to file. The file is truncated before the command is run. |
Non-sh61 shell features
Here are some commonly-used features of a more fully-implemented shell (like the
one you generally use!), but won’t be part of the sh61 assignment. Take a
look, some of them are incredibly powerful!
| Syntax | Description |
|---|---|
var=value |
Sets a variable to a value. |
$var |
Variable reference. Replaced with the variable’s value. There are several special variables; for instance: |
$? |
The numeric exit status of the most recently executed foreground pipeline. |
$$ |
The shell’s own process ID. |
command >> file |
Run command with its standard output appending to file. The file is not truncated before the command is run. |
command 2>&1 |
Run command with its standard error redirected to go to the same place as standard output. |
command 1>&2 |
Run command with its standard output redirected to go to the same place as standard error. Thus, echo Error 1>&2 prints Error to standard error. |
(command1; command2) |
Parentheses group commands into a “subshell.” The entire subshell can have redirections, and can have its output put into a pipe. |
command1 $(command2) |
Command substitution. The shell runs command2, then passes its output as the first argument to command1. |