
Exercises that seem less appropriate this year, or which cover topics that we haven’t covered in class, should be marked with ⚠️. However, we may have missed some.
SYNCH-1. Threads
The following code performs a matrix multiplication, c = ab, where
a, b, and c are all square matrices of dimension sz. It uses the
cache-friendly ikj index ordering.
struct square_matrix {
size_t sz;
double* v; // array of `sz * sz` doubles, row-major order
double& elt(size_t i, size_t j) {
assert(i < this->sz && j < this->sz);
return this->v[i * this->sz + j];
}
};
void matrix_multiply(square_matrix& c, square_matrix& a, square_matrix& b) {
assert(a.sz == b.sz && b.sz == c.sz);
for (size_t x = 0; x != c.sz * c.sz; ++x) {
c.v[x] = 0.0;
}
for (size_t i = 0; i != c.sz; ++i) {
for (size_t k = 0; k != c.sz; ++k) {
for (size_t j = 0; j != c.sz; ++j) {
c.elt(i, j) += a.elt(i, k) * b.elt(k, j);
}
}
}
}
But matrix multiplication is a naturally parallelizable problem.
QUESTION SYNCH-1A. Complete this code, which should perform the
multiplication using c.sz parallel threads, one per row of c.
void matrix_multiply_thread(square_matrix& c, square_matrix& a, square_matrix& b,
size_t i) {
/* YOUR CODE HERE */
}
void matrix_multiply_p(square_matrix& c, square_matrix& a, square_matrix& b) {
assert(a.sz == b.sz && b.sz == c.sz);
for (size_t x = 0; x != c.sz * c.sz; ++x) {
c.v[x] = 0.0;
}
std::vector<std::thread> ts;
for (size_t i = 0; i != c.sz; ++i) {
ts.push_back(std::thread(matrix_multiply_thread, std::ref(c), std::ref(a), std::ref(b), i));
}
for (size_t i = 0; i != c.sz; ++i) {
ts[i].join();
}
}
void matrix_multiply_thread(square_matrix& c, square_matrix& a, square_matrix& b, size_t i) { for (size_t k = 0; k != c.sz; ++k) { for (size_t j = 0; j != c.sz; ++j) { c.elt(i, j) += a.elt(i, k) * b.elt(k, j); } } }
For the next two parts, consider this alternate code for parallel
matrix_multiply, and assume a correct matrix_multiply_thread
implementation.
void matrix_multiply_alt(square_matrix& c, square_matrix& a, square_matrix& b) {
assert(a.sz == b.sz && b.sz == c.sz);
for (size_t x = 0; x != c.sz * c.sz; ++x) {
c.v[x] = 0.0;
}
std::vector<std::thread> ts;
for (size_t i = 0; i != c.sz; ++i) {
ts.push_back(std::thread(matrix_multiply_thread, std::ref(c), std::ref(a), std::ref(b), i));
ts[i].join();
}
}
QUESTION SYNCH-1B. True or false? matrix_multiply_alt produces correct results.
True.
QUESTION SYNCH-1C. How does matrix_multiply_alt differ from matrix_multiply_p?
matrix_multiply_altdoes not run threads for different rows in parallel.
QUESTION SYNCH-1D. On single-core machines, the kij order performs
almost as fast as the ikj order. Describe the changes that would be required
to make matrix_multiply_p and matrix_multiply_thread use kij order (and
produce correct results).
For incorrect results, a simple change suffices:
void matrix_multiply_thread(square_matrix& c, square_matrix& a, square_matrix& b, size_t k) { for (size_t i = 0; i != c.sz; ++i) { for (size_t j = 0; j != c.sz; ++j) { c.elt(i, j) += a.elt(i, k) * b.elt(k, j); } } }But this isn’t right because multiple threads can access
c.elt(i, j)at the same time using reads and writes, violating the fundamental law of synchronization. Atomic operations or locking would be required to make this correct.
SYNCH-2. Synchronization and concurrency
Most synchronization objects have at least two operations. Mutual-exclusion locks support lock and unlock; condition variables support wait and signal. One of the earliest synchronization objects invented, the semaphore, supports P and V.
In this problem, you’ll work with a synchronization object with only one operation, which we call a hemiphore. Hemiphores behave like the following; it is very important that you understand this pseudocode.
struct hemiphore {
int value = 0;
// Block until the hemiphore has `this->value >= bound`, then ATOMICALLY
// increment its value by `delta`.
void H(int bound, int delta) {
// This is pseudocode; a real hemiphore implementation would block, not spin, and would
// ensure that the test and the increment happen in one atomic step.
// You may assume that `this->value` never overflows.
while (this->value < bound) {
sched_yield();
}
this->value += delta;
}
};
Application code should access the hemiphore only through the H operation.
QUESTION SYNCH-2A. Use hemiphores to implement mutual-exclusion locks.
Fill out the code below. (You may not need to fill in every empty slot. You
may use standard C constants; for example, INT_MIN is the smallest possible
value for a variable of type int, which on an x86-64 machine is
−2147483648.)
struct mutex {
hemiphore h;
// YOUR CODE HERE (if necessary)
// Initialize the mutex.
mutex() {
// YOUR CODE HERE (if necessary)
}
// Lock the mutex.
void lock() {
// YOUR CODE HERE
}
// Unlock the mutex, which must be locked.
void unlock() {
// YOUR CODE HERE
}
};
No additional members are necessary. However, we don’t want to use a positive number to represent the locked state. The
Hoperation blocks if the value is too small. The locked state should cause blocking, so the locked state should have a smaller value than the unlocked state.struct mutex { hemiphore h; void lock() { this->h.H(0, -1); } void unlock() { this->h.H(-1, 1); } };
QUESTION SYNCH-2B. Use hemiphores to implement condition variables. Fill
out the code below. You may assume that the implementation of mutex is your
hemiphore-based implementation from above (so, for instance, wait may access
the hemiphore m.h). See the Hints at the end of the question.
struct condition_variable {
mutex internal;
hemiphore h;
// YOUR CODE HERE (if necessary)
// Initialize the condition variable.
condition_variable() {
// YOUR CODE HERE (if necessary)
}
// Wake up one thread waiting on the condition variable (if any are waiting).
void notify_one() {
// YOUR CODE HERE
}
// Block until the condition variable is signaled. The mutex argument `m` must be locked by
// the current thread; it is unlocked before the wait begins and re-locked after the wait ends.
// There must be no sleep-wakeup race conditions: if thread 1 has `m` locked and executes
// `cv.wait(m)`, no other thread is waiting on `cv`, and thread 2 executes `m.lock();
// cv.notify_one(); m.unlock()`, then thread 1 will always receive the signal (i.e., wake up).
void wait(mutex& m) {
// A true C++ condition_variable would take a `std::unique_lock`—we elide that here.
// YOUR CODE HERE
}
};
Hints. For full credit:
- If no thread is waiting on condition variable
cv, thencv.notify_all()should have no effect. - Assume N threads are waiting on condition variable
cv. Then N calls tocond_signal(c)are both necessary and sufficient to wake them all up. - Your solution must not add new sleep-wakeup race conditions to the user’s code. (That is, no sleep-wakeup race conditions unless the user uses mutexes incorrectly.)
Some care is required to avoid sleep–wakeup races. A solution involves counting the number of waiting threads, using a number protected by the
internalmutex.struct condition_variable { mutex internal; hemiphore h; int nwaiting = 0; void notify_one() { this->internal.lock(); if (this->nwaiting > 0) { this->h.H(INT_MIN, 1); this->nwaiting -= 1; } this->internal.unlock(); } void wait(mutex& m) { this->internal.lock(); this->nwaiting += 1; this->internal.unlock(); m.unlock(); // note: Must unlock AFTER incrementing `nwaiting` this->h.H(1, -1); m.lock(); } };
QUESTION SYNCH-2C. Use C++ standard mutexes and condition variables to implement hemiphores. Fill out the code below; see the hints after the question.
struct hemiphore {
std::mutex m;
std::condition_variable_any cv;
int value = 0;
// YOUR CODE HERE (if needed)
// Initialize the hemiphore.
hemiphore() {
// YOUR CODE HERE (if needed)
}
// Block until the hemiphore has `this->value >= bound`, then ATOMICALLY
// increment its value by `delta`.
void H(int bound, int delta) {
// YOUR CODE HERE
}
};
struct hemiphore { std::mutex m; std::condition_variable_any cv; int value = 0; void H(int bound, int delta) { this->m.lock(); while (this->value < bound) { this->cv.wait(this->m); } this->value += delta; if (delta > 0) { this->cv.notify_all(); } this->m.unlock(); } };
QUESTION SYNCH-2D. Consider the following two threads, which use a
shared hemiphore h with initial value 0.
Thread 1 Thread 2
h.H(1000, 1); while (1) {
printf("Thread 1 done\n"); h.H(0, 1);
h.H(0, -1);
}Thread 2 will never block, and the hemiphore’s value will alternate
between 1 and 0. Thread 1 will never reach the printf, because the
hemiphore’s value never reaches 1000. However, in most people’s first
implementation of hemiphores using standard mutexes and condition
variables, Thread 1 will not block. Every call to h.H in Thread 2 will
effectively wake up Thread 1. Though Thread 1 will then check the
hemiphore’s value and immediately go back to sleep, doing so wastes CPU
time.
Design an implementation of hemiphores using pthread mutexes and condition variables that solves this problem. In your revised implementation, Thread 1 above should block forever. For full credit, write C++ code (without worrying too much about C++ syntax). For partial credit, write pseudocode or English describing your design.
Hint. One working implementation uses a vector of “waiter” objects, where each waiter object is on a different thread’s stack, as initially sketched below. You can use such objects or not as you please.
struct hemiphore_waiter {
// YOUR CODE HERE (if necessary)
};
struct hemiphore {
std::mutex m;
int value = 0;
std::vector<hemiphore_waiter*> waiters;
// YOUR CODE HERE (if necessary)
hemiphore() {
// YOUR CODE HERE (if necessary)
}
void H(int bound, int delta) {
hemiphore_waiter hw;
// YOUR CODE HERE
}
};
This is a bit of a tough one. The key idea is to introduce a condition variable per waiting thread.
struct hemiphore_waiter { int bound; std::condition_variable_any cv; }; struct hemiphore { std::mutex m; int value = 0; std::vector<hemiphore_waiter*> waiters; void H(int bound, int delta) { hemiphore_waiter hw; hw.bound = bound; this->m.lock(); while (this->value < bound) { this->waiters.push_back(&hw); hw.cv.wait(this->m); } this->value += delta; // Wake up *only* those threads that should be woken. // This loop is written using iterators; there are many other styles. for (auto it = this->waiters.begin(); it != this->waiters.end(); ) { if (this->value >= it->bound) { it->cv.notify_all(); it = this->waiters.erase(it); } else { ++it; } } this->m.unlock(); } };
SYNCH-3. Pipes and synchronization
In the following questions, you will implement a mutex using a pipe, and a limited type of pipe using a mutex.
QUESTION SYNCH-3A. In this question, you are to implement mutex
functionality using a pipe. Fill in the definitions of the mutex operations.
You may assume that no errors occur.
struct pipe_mutex {
int fd[2];
// YOUR CODE HERE (if necessary)
pipe_mutex() {
int r = pipe(this->fd);
assert(r == 0);
// YOUR CODE HERE (if necessary)
}
void lock() {
// YOUR CODE HERE
}
void unlock() {
// YOUR CODE HERE
}
};
The most natural way to implement this is to use
readas the blocking operation, which requires an unlocked pipe mutex’s pipe contain a byte (so thatreadon such a pipe doesn’t block).struct pipe_mutex { int fd[2]; // YOUR CODE HERE (if necessary) pipe_mutex() { int r = pipe(this->fd); assert(r == 0); ssize_t n = write(this->fd, "!", 1); assert(n == 1); } void lock() { char ch; while (read(this->fd, &ch, 1) != 1) { } } void unlock() { ssize_t n = write(this->fd, "!", 1); assert(n == 1); } };
In the next questions, you will help implement pipe functionality using an in-memory buffer and a mutex. This “mutex pipe” will only work between threads of the same process (in contrast to a regular pipe, which also works between processes). An initial implementation of mutex pipes is as follows; you will note that it contains no mutexes.
struct mutex_pipe {
/* 1*/ char bbuf_[BUFSIZ];
/* 2*/ size_t bpos_;
/* 3*/ size_t blen_;
mutex_pipe() {
/* 4*/ this->bpos_ = this->blen_ = 0;
/* 5*/ memset(this->bbuf_, 0, BUFSIZ);
}
// Read up to `sz` bytes from this mutex_pipe into `buf` and return the number of bytes
// read. If no bytes are available, wait until at least one byte can be read.
ssize_t read(char* buf, size_t sz) {
/* 6*/ size_t pos = 0;
/* 7*/ while (pos < sz && (pos == 0 || this->blen_ != 0)) {
/* 8*/ if (this->blen_ != 0) {
/* 9*/ buf[pos] = this->bbuf_[this->bpos_];
/*10*/ ++this->bpos_;
/*11*/ this->bpos_ = this->bpos_ % BUFSIZ;
/*12*/ --this->blen_;
/*13*/ ++pos;
/*14*/ }
/*15*/ }
/*16*/ return pos;
}
// Write up to `sz` bytes from `buf` into this mutex_pipe and return the number of bytes
// written. If no space is available, wait until at least one byte can be written.
ssize_t write(const char* buf, size_t sz) {
/*17*/ size_t pos = 0;
/*18*/ while (pos < sz && (pos == 0 || this->blen_ < BUFSIZ)) {
/*19*/ if (this->blen_ != BUFSIZ) {
/*20*/ size_t bindex = this->bpos_ + this->blen_;
/*21*/ bindex = bindex % BUFSIZ;
/*22*/ this->bbuf_[bindex] = buf[pos];
/*23*/ ++this->blen_;
/*24*/ ++pos;
/*25*/ }
/*26*/ }
/*27*/ return pos;
}
};
QUESTION SYNCH-3B. What’s another name for this data structure?
This is a bounded buffer.
It would be wise to work through an example. For example, assume
BUFSIZ == 4, and figure out how the following calls would behave.mutex_pipe mp; mp.write("Hi", 2); mp.read(buf, 4); mp.write("Test", 4); mp.read(buf, 3);
First let’s reason about this code in the absence of threads.
QUESTION SYNCH-3C. Which of the following changes could, if made in isolation, result in undefined behavior when a mutex pipe was used? Circle all that apply.
- Removing line 4
- Removing line 5
- Removing “
|| this->blen_ < BUFSIZ” from line 18 - Removing line 21
- Removing lines 23 and 24
Removing line 4 or line 21 will cause undefined behavior. The others will create correct, but not undefined, behavior.
QUESTION SYNCH-3D. Which of the following changes could, if made in
isolation, cause a mutex_pipe::read to return incorrect data (that is,
the byte sequence produced by read will not equal the byte sequence
passed to write)? Circle all that apply.
- Removing line 4
- Removing line 5
- Removing “
|| this->blen_ < BUFSIZ” from line 18 - Removing line 21
- Removing lines 23 and 24
#1, #3, and #4 could cause a
readto return incorrect data. #2 (removing line 5) has no effect. #5 will not causereadto return incorrect data, as you’ll see in the next question.
QUESTION SYNCH-3E. Which of the following changes could, if made in
isolation, cause a call to mutex_pipe::write to never return (when a
correct implementation would return)? Circle all that apply.
- Removing line 4
- Removing line 5
- Removing “
|| this->blen_ < BUFSIZ” from line 18 - Removing line 21
- Removing lines 23 and 24
The obvious one is that removing lines 23–24 will cause
posandthis->blen_to never increment, which will cause thewritewhileloop to spin forever. #1 and #4 cause undefined behavior, which could have any effect, including an infinite loop in a laterwrite.
QUESTION SYNCH-3F. Write an invariant for a mutex_pipe’s blen_ member.
An invariant is a statement about the value of blen_ that is always true.
Write your invariant in the form of an assertion; for full credit give the
most specific true invariant you can. (“blen_ is a unsigned integer” is
unspecific, but true; “blen_ == 4” is specific, but false.)
assert(this->blen_ < BUFSIZ)
QUESTION SYNCH-3G. Write an invariant for bpos_. For full credit
give the most specific true invariant you can.
assert(this->bpos_ < BUFSIZ)
In the remaining questions, you will add synchronization objects and operations to make your mutex pipe work in a multithreaded program.
QUESTION SYNCH-3H. Add a std::mutex to the mutex_pipe and use it to
protect the mutex pipe from race condition bugs. For full credit, your
solution must not deadlock—if one thread is reading from a pipe and another
thread is writing to the pipe, then both threads must eventually make
progress. Describe all changes required, with reference to specific line numbers.
It’s important to lock the mutex before accessing any shared state. It’s also important not to spin in a
whileloop while holding a mutex; we therefore have an initial loop that spins until data is available forread(or space is available forwrite).
Add
std::mutex mtopipe_mutex.Add
this->m.lock()after lines 6 and 17.Add
this->m.unlock()after lines 15 and 26.Add the following loop after the
m.lock()inread:while (this->blen_ == 0 && sz != 0) { this->m.unlock(); sched_yield(); // give other threads a chance to run (not necessary) this->m.lock(); }Add a similar loop after the
m.lock()inwrite:while (this->blen_ == BUFSIZ && sz != 0) { this->m.unlock(); sched_yield(); // give other threads a chance to run (not necessary) this->m.lock(); }
QUESTION SYNCH-3I. Your solution to the last question likely has poor
utilization. For instance, a thread that calls mutex_pipe on an
empty mutex pipe will spin forever, rather than block. Introduce one or
more condition variables so that read will block until data
is available. Write one or more snippets of C code and give line numbers
after which the snippets should appear.
Add
std::condition_variable nonemptytostruct mutex_pipe.Instead of the loop suggested above in
read, use:while (this->blen_ == 0 && sz != 0) { this->nonempty.wait(this->m); }Add the following code to the end of
write, anywhere before thereturn:this->nonempty.notify_all();
SYNCH-4. Race conditions
Most operating systems support process priority levels, where the kernel runs higher-priority processes more frequently than lower-priority processes. A hypothetical Unix-like operating system called “Boonix” has two priority levels, normal and batch. A Boonix parent process changes the priority level of one of its children with this system call:
int setbatch(pid_t p)
Sets processpto have batch priority. All future children ofpwill also have batch priority. Returns 0 on success, –1 on error. Errors includeESRCH, ifpis not a child of the calling process.
Note that a process cannot change its own batch status.
You’re writing a Boonix shell that can run commands with batch priority.
If c->isbatch is nonzero, then c should run with batch priority, as
should its children. Your command::make_child function looks like this:
void command::make_child() {
/* 1*/ ... // maybe create a pipe
/* 2*/ this->pid = fork();
/* 3*/ if (this->pid == 0) {
/* 4*/ ... // handle pipes and redirections
/* 5*/ (void) execvp(...);
/* 6*/ perror("execvp");
/* 7*/ _exit(EXIT_FAILURE);
/* 8*/ }
/* 9*/ assert(this->pid > 0);
/*10*/ if (this->isbatch) {
/*11*/ setbatch(this->pid);
/*12*/ }
/*13*/ ... // clean up pipes and such
}
This shell has two race conditions, one more serious.
QUESTION SYNCH-4A. In some cases, a child command will change to batch priority after it starts running. Briefly describe how this can occur.
The child’s
execvpmight complete, and its new program start running, before the parent shell callssetbatch.
QUESTION SYNCH-4B. In some cases, a child command, or one of its own forked children, could run forever with normal priority. Briefly describe how this can occur.
As in part A, the child might
execvpand run before the parent callssetbatch. If the child itself forks, then the resulting grandchild will have normal priority; thesetbatchsystem call will not catch it.
In the remaining questions, you will fix these race conditions in three different ways. The first uses a new system call:
int isbatch()
Returns 1 if the calling process has batch priority, 0 if it has normal priority.
QUESTION SYNCH-4C. Use isbatch to prevent both race conditions.
Write a snippet of C code and give the line number after which it should
appear. You should need one code snippet.
Add this in the child, before
execvp(after line 3 or 4):while (this->isbatch && !isbatch()) { }
QUESTION SYNCH-4D. Use the pipe system call and friends to prevent
both race conditions. Write snippets of C code and give the line numbers
after which they should appear. You should need several snippets. Make
sure you clean up any extraneous file descriptors before running the
command or returning from command::make_child.
In the parent, before
fork(after line 1):int bpipe[2]; if (this->isbatch) { int r = pipe(bpipe); assert(r == 0); }In the child, before
execvp(after line 3 or 4):char ch; while (this->isbatch && read(bpipe[0], &ch, 1) != 1) { } close(bpipe[0]); close(bpipe[1]);In the parent, after calling
isbatchand before exiting:if (this->isbatch) { ssize_t n = write(bpipe[1], "!", 1); assert(n == 1); close(bpipe[0]); close(bpipe[1]); }Other solutions are possible too.
QUESTION SYNCH-4E. Why should the pipe solution be preferred to
the isbatch solution? A sentence, or the right single word, will
suffice.
It blocks! Which improves utilization relative to the
isbatchpolling-based solution.
QUESTION SYNCH-4F. Suggest a change to the setbatch system call’s
behavior that could fix both race conditions, and say how to use this
new setbatch in start_command. Write one or more snippets of C code
and give the line numbers after which they should
appear.
A very simple change would be to allow a process to set its own batchness. Then get rid of the call in the parent. In the child, before
execvp:if (c->isbatch) { setbatch(getpid()); }
SYNCH-5. Minimal minimal minimal synchronization synchronization synchronization
Minimalist composer Philip Glass, who prefers everything minimal,
proposes the following implementation of condition variables based on
mutexes. He’s only implementing wait and notify_one at
first.
struct pg_condition_variable {
std::mutex cvm;
pg_condition_variable() {
// start the mutex in LOCKED state!
this->cvm.lock();
}
void wait(std::mutex& m) {
m.unlock();
this->cvm.lock(); // will block until a thread calls `notify_one`
m.lock();
}
void notify_one() {
this->cvm.unlock();
}
};
Philip wants to use his condition variables to build a bank, where accounts support these operations:
void pg_acct::deposit(unsigned amt)
Addsamttothis->balance.void pg_acct::withdraw(unsigned amt)
Blocks untilthis->balance >= amt; then deductsamtfromthis->balanceand returns.
Here’s Philip’s code.
struct pg_acct {
unsigned long balance;
std::mutex m;
pg_condition_variable cv;
void deposit(unsigned amt) {
/*D1*/ this->m.lock();
/*D2*/ this->balance += amt;
/*D2*/ this->cv.notify_one();
/*D2*/ this->m.unlock();
}
void withdraw(unsigned amt) {
/*W1*/ this->m.lock();
/*W2*/ while (this->balance < amt) {
/*W3*/ this->cv.wait(this->m);
/*W4*/ }
/*W5*/ this->balance -= amt;
/*W6*/ this->m.unlock();
}
};
Philip’s friend Pauline Oliveros just shakes her head. “You got serious problems,” she says, pointing at this section of the C++ standard:
The expression
m.unlock()shall…have the following semantics:Requires: The calling thread shall own the mutex.
This means that the when m.unlock() is called, the calling thread must have
previously locked the mutex, with no intervening unlocks. The penalty for
deviance is undefined behavior.
QUESTION SYNCH-5A. Briefly explain how Philip’s code can trigger undefined behavior.
There are so many bad undefined behaviors here. For instance, two sequential calls to
depositwill callcv.notify_one()twice, which callscv.cvm.unlock()twice.
To fix this problem, Philip changes his condition variable and account to use
a new type, fast_mutex, instead of std::mutex. This type is inspired by
Linux’s “fast” mutexes. It’s OK to unlock a fast_mutex more than once,
and it’s OK to unlock a fast_mutex on a different thread than the
thread that locked it.
A fast_mutex has one important member, value, which can be 0 (unlocked) or
1 (locked).
Below, we've begun to write out an execution where Philip’s code is
called by two threads. We write the line numbers each thread executes
and the values in a after each line. We’ve left lines blank for you
to fill in if you need to.
| T1 | T2 | a.balance |
a.m.value |
a.cv.cvm.value |
|---|---|---|---|---|
| Initial state: | 5 | 0 | 1 | |
a.deposit(10)… |
a.withdraw(12)… |
|||
| after W1 | 5 | 1 | 1 | |
| after D1 | 5 | 1 | 1 | |
(T1 blocks on a.m) |
||||
QUESTION SYNCH-5B. Assuming T2’s call to withdraw eventually completes,
what are the final values for a.balance, a.m.value, and a.cv.cvm.value?
The execution will complete as follows:
T1 T2 a.balancea.m.valuea.cv.cvm.valueInitial state: 5 0 1 a.deposit(10)…a.withdraw(12)…after W1 5 1 1 after D1 5 1 1 (T1 blocks on a.m)W2 5 1 1 W3 5 0 1 (T2 blocks on a.cv.cvm)5 0 1 (T1 unblocks) 5 1 1 D2 15 1 1 D3 15 1 0 D4 15 0 0 (T2 unblocks) 15 1 1 W2 15 1 1 W5 3 1 1 W6 3 0 1 The values are 3, 0, and 1, respectively.
QUESTION SYNCH-5C. In such an execution, which line of code (W1–5) unblocks Thread T1?
Line W3, which calls
pg_condition_variable::wait, which unlocksa.m.
QUESTION SYNCH-5D. In such an execution, which, if any, line(s) of
code (D1–4 and/or W1–5) set a->cv.cvm.value to zero?
Line D3, which calls
pg_condition_variable::notify_one.
QUESTION SYNCH-5E. For any collection of deposit and withdraw calls,
Philip’s code will always ensure that the balance is valid. (There are other
problems—a withdraw call might block forever when it shouldn’t—but the
balance will be OK.) Why? List all that apply.
- Access to
balanceis protected by a condition variable. - Access to
balanceis protected by a mutex. - Arithmetic expressions like
this->balance += amt;have atomic effect.
#2.
SYNCH-6. Weensy threads
Betsy Ross is changing her WeensyOS to support threads. There are many
ways to implement threads, but Betsy wants to implement threads using
the ptable array. “After all,” she says, “a thread is just like a
process, except it shares the address space of some other process!”
Betsy has defined a new system call, sys_create_thread, that starts a new
thread running a given thread function, with a given argument, and a given
initial stack pointer:
typedef void* (*thread_function)(void*);
pid_t sys_create_thread(thread_function f, void* arg, void* stack_ptr);
The system call’s return value is the ID of the new thread, which Betsy thinks should use the process ID space.
Betsy’s kernel contains the following code:
// in syscall()
case SYSCALL_FORK:
return handle_fork(current);
case SYSCALL_CREATE_THREAD:
return handle_create_thread(current);
uint64_t handle_fork(proc* p) {
// Find a free process; return `nullptr` if all out
proc* np = find_free_process();
if (!np) {
return -1;
}
// Copy the input page table and allocate new pages using `vmiter`
np->pagetable = copy_pagetable(p->pagetable);
if (!np->pagetable) {
return -1;
}
// Finish up
np->regs = p->regs;
np->regs.reg_rax = 0;
np->state = P_RUNNABLE;
return np->pid;
}
uint64_t handle_create_thread(proc* p) {
// Whoops! Got a revolution to run, back later
return -1;
}
QUESTION SYNCH-6A. Complete her handle_create_thread implementation.
Assume for now that the thread function never exits, and don’t worry about
reference counting issues (for page tables, for instance). You may use the helper
functions shown above, including find_free_process and copy_pagetable, if
you need them; or you may use any functions or objects from the WeensyOS
handout code, including vmiter and kalloc.
Recall that system call arguments are passed according to the x86-64
calling convention: first argument in %rdi, second in %rsi,
third in %rdx, etc.
The code is a lot like
fork, except that (1) the new thread shares the same page table as the callingproc, (2) the new thread’s registers are populated from the calling threads’s arguments.uint64_t handle_create_thread(proc* p) { proc* np = find_unused_process(); if (!np) { return -1; } np->pagetable = p->pagetable; np->regs = p->regs; np->regs.reg_rip = p->regs.reg_rdi; np->regs.reg_rdi = p->regs.reg_rsi; np->regs.reg_rsp = p->regs.reg_rdx; np->state = P_RUNNABLE; return np->pid; }
QUESTION SYNCH-6B. Betsy’s friend Prince Dimitri Galitzin thinks Betsy
should give processes even more flexibility. He suggests that the
sys_create_thread system call should take a full set of registers (as
x86_64_registers*), rather than just a new instruction pointer and a new
stack pointer. That way, the creating thread can supply all registers to the
new thread. But Betsy points out that this design would allow a thread to
violate kernel isolation by providing carefully-planned register values for
x86_64_registers.
Which x86-64 registers could be used in Dimitri’s design to violate kernel isolation? List all that apply.
reg_rax, which contains the thread’s%raxregister.reg_rip, which contains the thread’s instruction pointer.reg_cs, which contains the thread’s privilege level, which is 3 for unprivileged.reg_rflags, which contains theEFLAGS_IFflag, which indicates that the thread runs with interrupts enabled.reg_rsp, which contains the thread’s stack pointer.
On WeensyOS, only #3 and #4 can cause violations of kernel isolation. Carefully-chosen #2 and #5 might cause the thread to crash, but that doesn’t violate kernel isolation. Changes to #1 will have little if any effect.
Now Betsy wants to handle thread exit. She introduces two new system
calls, sys_exit_thread and sys_join_thread:
void sys_exit_thread(void* exit_value);
void* sys_join_thread(pid_t thread);
sys_exit_thread causes the calling thread to exit with the given exit value.
sys_join_thread behaves like pthread_join or waitpid. If thread
corresponds is a thread of the same process, and thread has exited,
sys_join_thread cleans up the thread and returns its exit value; otherwise,
sys_join_thread returns (void*) -1.
(The exit_value feature differs from C++ threads, which don’t have exit
values.)
QUESTION SYNCH-6C. Is the sys_join_thread specification
blocking or polling?
Polling.
Betsy makes the following changes to WeensyOS internal structures to support thread exit.
- She adds a
void* p_exit_valuemember tostruct proc. - She adds a new process state,
P_EXITED, that corresponds to exited threads.
QUESTION SYNCH-6D. Complete the case for SYSCALL_EXIT_THREAD. (Don’t
worry about the last thread in a process; you may assume it always calls
sys_exit rather than sys_exit_thread.)
case SYSCALL_EXIT_THREAD:
current->state = P_EXITED; current->exit_value = current->regs.reg_rdi; schedule();
QUESTION SYNCH-6E. Complete the following helper function.
// Test whether `test_pid` is the PID of a thread in the same process as `p`.
// Return 1 if it is; return 0 if `test_pid` is an illegal PID, it corresponds to
// a freed process, or it corresponds to a thread in a different process.
int is_thread_in(pid_t test_pid, proc* p) {
The key thing to note is that threads in the same process will share
pagetable, and threads in different processes will always have differentpagetables.return test_pid >= 0 && test_pid < NPROC && ptable[test_pid]->pagetable == p->pagetable;
QUESTION SYNCH-6F. Complete the case for SYSCALL_JOIN_THREAD
in syscall(). Remember that a thread may be successfully joined at
most once: after it is joined, its PID is made available for
reallocation.
case SYSCALL_JOIN_THREAD:pid_t t = current->regs.reg_rdi; if (is_thread_in(t, current) && ptable[t].state == P_EXITED) { ptable[t].state = P_FREE; return ptable[t].exit_value; } else { return -1; }
QUESTION SYNCH-6G. Advanced extra credit. In Weensy threads, if a
thread returns from its thread function, it will execute random code,
depending on what random garbage was stored in its initial stack in the return
address position. But Betsy thinks she can implement better behavior entirely
at user level, where the value returned from the thread function will
automatically be passed to sys_thread_exit. She wants to make two changes:
- She’ll write a two- or three-instruction function called
thread_exit_vector. - Her
create_threadlibrary function will write a single 8-byte value to the thread’s new stack before callingsys_create_thread.
Explain how this will work. What instructions will
thread_exit_vector contain? What 8-byte value will
create_thread write to the thread’s new stack? And where will that
value be written relative to sys_create_thread’s stack_ptr
argument?
thread_exit_vector: movq %rax, %rdi jmp sys_exit_threadOr:
movq %rax, %rdi movq $SYSCALL_EXIT_THREAD, %rax syscallThe 8-byte value will equal the address of
thread_exit_vector, and it will be placed in the return address slot of the thread’s new stack. So it will be written starting at addressstack_top.
SYNCH-7. Fair synchronization
C++ standard mutexes are unfair: some threads might succeed in locking the mutex more often than others. For example, a simple experiment on Linux shows that if threads repeatedly try to lock the same mutex, some threads lock the mutex 1.13x more often than others. (Other kinds of lock are even less fair: some threads can lock a spinlock 3.91x more often than others!)
QUESTION SYNCH-7A. What is the name of the problem that would occur if one particular thread never locked the mutex, even though other threads locked and unlocked the mutex infinitely often?
Starvation.
To avoid unfairness, threads must take turns. One fair mutex implementation is called a ticket lock; this (incorrect, unsynchronized) code shows the basic idea.
struct ticket_mutex {
unsigned now = 0; // “now serving”
unsigned next = 0; // “next ticket”
void lock() {
unsigned t = this->next; // mark this thread’s place in line
++this->next; // next thread gets new place
while (this->now != t) { // wait for my turn
}
}
void unlock() {
++this->now;
}
};
QUESTION SYNCH-7B. Describe an instance of undefined behavior that could
occur if multiple threads called ticket_mutex::lock on the same ticket
mutex at the same time.
Both threads might execute
++this->nextat the same time, violating the Fundamental Law of Synchronization.
QUESTION SYNCH-7C. Fix lock and unlock using C++ atomics. Alternately,
for partial credit, say which regions of code must be executed atomically.
It’s important to combine the assignment to
unsigned twith the increment, like this for instance:struct ticket_mutex { std::atomic<unsigned> now = 0; // “now serving” std::atomic<unsigned> next = 0; // “next ticket” void lock() { unsigned t = this->next.fetch_add(1); while (this->now != t) { } } void unlock() { ++this->now; } };
The ticket lock implementation above uses polling. That will perform well if critical sections are short, but blocking is preferable if critical sections are long. Here’s a different ticket lock implementation:
struct ticket_mutex {
/*T1*/ unsigned now;
/*T2*/ unsigned next;
/*T3*/ std::mutex m;
void lock() {
/*L1*/ this->m.lock();
/*L2*/ unsigned t = this->next++;
/*L3*/ while (this->now != t) {
/*L4*/ this->m.unlock();
/*L5*/ sched_yield();
/*L6*/ this->m.lock();
/*L7*/ }
/*L8*/ this->m.unlock();
}
void unlock() {
/*U1*/ this->m.lock();
/*U2*/ ++this->now;
/*U3*/ this->m.unlock();
}
};
This ticket lock implementation uses std::mutex, which
blocks, but the implementation itself uses polling.
QUESTION SYNCH-7D. Which line or lines of code mark this implementation as using polling?
Line L5, which calls
sched_yield().
QUESTION SYNCH-7E. Change the implementation to truly block. Include line numbers indicating where your code will go.
As with most block-on-condition requirements, this calls for a condition variable.
After line T3, add
std::condition_variable_any cv.
Instead of L4–L6, putthis->cv.wait(this->m);.
After line U2, putthis->cv.notify_all();.
QUESTION SYNCH-7F. Most solutions to part E wake up blocked threads more than is strictly necessary. The ideal number of blocking calls is one: each thread should block at most once and wake up only when its turn comes. But the simplest correct solution will wake up each blocked thread a number of times proportional to the number of blocked threads.
Change your solution so that when there are 4 or fewer threads, every thread wakes up only when its turn comes. (Your solution must, of course, work correctly for any number of threads.) If your solution already works this way, you need not do anything here.
A simple solution is to have 4 conditions, each corresponding to “a ticket equal to this condition’s index (mod 4) is available.”
After line T3, add
std::condition_variable_any cv[4].
Instead of L4–L6, putthis->cv[t % 4].wait(this->m);.
Replace line U2 withauto t = ++this->now;. (It’s important to remember the actual new value ofnow.)
After line U2, putthis->cv[t % 4].notify_all().
NET-1. Networking
QUESTION NET-1A. Which of the following system calls should a programmer expect to sometimes block (i.e., to return after significant delay)? Circle all that apply.
socketreadacceptlistenconnectwriteusleep- None of these
#2
read, #3accept, #5connect, #6write, #7usleep.
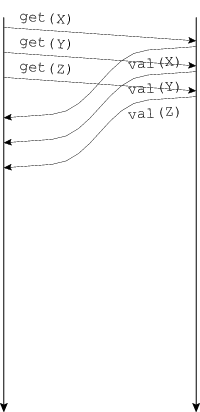
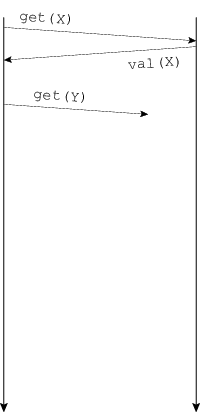
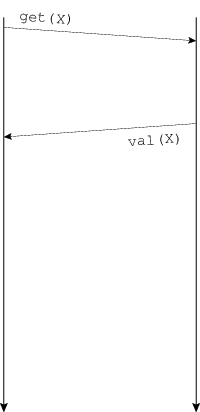
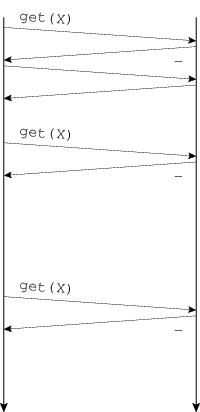
QUESTION NET-1B. ⚠️ Below are seven message sequence diagrams demonstrating the operation of a client–server RPC protocol. A request such as “get(X)” means “fetch the value of the object named X”; the response contains that value. Match each network property or programming strategy below with the diagram with which it best corresponds. You will use every diagram once.
- Loss
- Delay
- Reordering
- Duplication
- Batching
- Prefetching
- Exponential backoff
 |
 |
 |
 |
| A | B | C | D |
 |
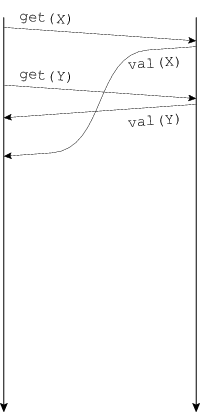 |
 |
| E | F | G |
#1—B, #2—C, #3—F, #4—D, #5—G, #6—A, #7—E
(A—#6, B—#1, C—#2, D—#4, E—#7, F—#3, G—#5)While G could also represent prefetching, A definitely does not represent batching at the RPC level—each RPC contains one request—so under the rule that each diagram is used once, we must say G is batching and A is prefetching.
QUESTION NET-1C. List some resources that a DoS attack on a network server might exhaust.
At least: file descriptors, memory (stack), processes/threads. There’re a lot of correct answers, though! You can run out of virtual memory or even physical memory.
QUESTION NET-1D. A server sets up a socket to listen on a connection. When a client wants to establish a connection, how does the server manage the multiple clients? In your answer indicate what system call or calls are used and what they do.
The server calls
accepton a listening file descriptor. This creates a new file descriptor that is particular to the connection with a particular client, giving the server uses a different fd for each client.