
Deadlock
Deadlock is a situation in a multi-threaded process where each thread is waiting (forever) for a resource that is held by another thread.
It is necessary to have a cycle in a resource ownership-wait diagram to have a deadlock. The following diagram illustrates a deadlock where two threads are waiting for some resources held by each other and are therefore unable to ever make progress.
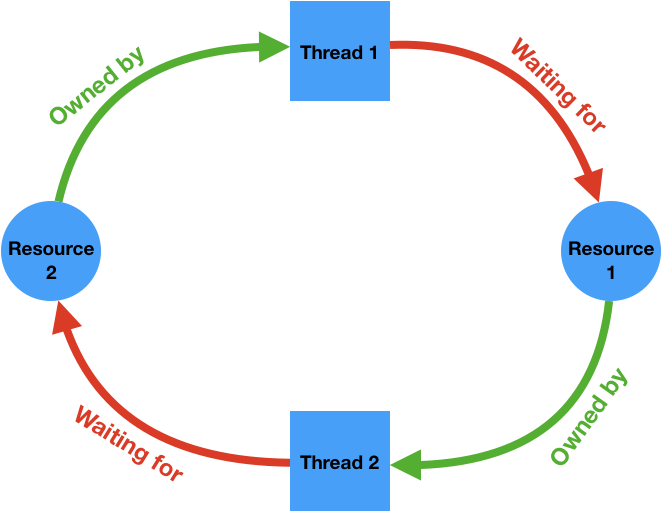
Cycles like this can potentially be detected by the runtime system and it can intervene to break the deadlock, for example by forcing one of the threads to release the resources it owns. The C++ runtime does not perform these checks for performance reasons, therefore it's the programmer's responsibility to make sure the program is free of deadlocks.
There are many ways to lead to a deadlock, even with just a single mutex and a single thread. Consider the following code:
std::mutex m;
void f() {
std::scoped_lock guard(m);
g();
}
void g() {
std::scoped_lock guard(m);
// Do something else
}
This code will not make any progress because the lock acquisition
scoped_lock in g() is waiting for the scoped_lock in f() to go out of
scope, which it never will.
Also, the resources that are involved in a ownership-wait cycle don't have to be mutexes. Recall the extra credit in the stdio problem set (problem set 4). The two resources are two pipe buffers. Let's say the two processes are following the procedure below:
Process 1:
writes 3 requests to the pipe, 33000 bytes each
reads 3 responses from the pipe, 66000 bytes each
Process 2:
while (true) {
reads a request from the pipe
writes a response to the pipe
}Process 1 should successfully write two requests to the pipe, as Process 2 consumes one request so there is space in the pipe to hold the second request. The third request write will however be blocked because there is not enough space in the pipe buffer (assuming pipe buffers are 65536 bytes). Process 2 can not consume another request because it is also blocked while writing the large response for the first request, which does not fit in the pipe buffer. A cycle occurs and no process can make progress.
WeensyDB's exch command
Our simple networked database, WeensyDB, from the last lecture now supports a
new "exchange" (or exch) command, which swaps the values associated with two
keys. The relevant code enabling this command is in synch4/weensydb-06.cc#L112:L137,
which is also shown below:
} else if (sscanf(buf, "exch %s %s ", key, key2) == 2) {
// find item
auto b1 = string_hash(key) % NBUCKETS;
auto b2 = string_hash(key2) % NBUCKETS;
hash_mutex[b1].lock();
hash_mutex[b2].lock();
auto it1 = hfind(hash[b1], key);
auto it2 = hfind(hash[b2], key2);
// exchange items
if (it1 != hash[b1].end() && it2 != hash[b2].end()) {
std::swap(it1->value, it2->value);
fprintf(f, "EXCHANGED %p %p\r\n", &*it1, &*it2);
} else {
fprintf(f, "NOT_FOUND\r\n");
}
fflush(f);
hash_mutex[b1].unlock();
hash_mutex[b2].unlock();
} else if (remove_trailing_whitespace(buf)) {
fprintf(f, "ERROR\r\n");
fflush(f);
}
}
The two lines
hash_mutex[b1].lock();
hash_mutex[b2].lock();
smells deadlock. This code deadlocks if the two keys simply hash to the same bucket.
Changes were made in synch4/weensydb-07.cc to address this issue. The two
lines above are now replaced by the following (albeit slightly more complex)
code:
hash_mutex[b1].lock();
if (b1 != b2) {
hash_mutex[b2].lock();
}
There is still risk of deadlock as we are not locking the mutexes in a fixed
global order. In many cases we can handily represent this global order by
something we already keep track of in our code. In this example the bucket
numbers b1 and b2 are natural indicators of such a global order. Another
commonly used order is based on the memory address values of the mutex objects
themselves. synch4/weensydb-08.cc shows a locking order based on hash bucket
numbers:
if (b1 > b2) {
hash_mutex[b2].lock();
hash_mutex[b1].lock();
} else if (b1 == b2) {
hash_mutex[b1].lock();
} else {
hash_mutex[b1].lock();
hash_mutex[b2].lock();
}
Servers and the "C10K" problem
"C10K" stands for handling 10,000 connections at a time. Back at the time when the Internet just came into being this is considered a "large-scale" problem. In today's scale the problem is more like "C10M" or "C10B" -- building servers or server architectures that can handle tens of millions (or even billions) of connections at the same time.
Early server software spawns a thread for each incoming connection. This means
to handle 10,000 connections at once, the server must run 10,000 threads at
the same time. Every thread has its own set of registers (stored in the kernel)
and its own stack (takes up user-space memory). Each thread also has a control
block (called a task struct in Linux) managed by the kernel. These resources
add up to some very significant per-thread space overhead:
- Socket buffers: ~ 32KB each
- Stack: ~ 8MB
- Task struct + kernel thread stack: ~ 8KB
10,000 thread stacks alone add up to ~ 80GB of memory! It is clearly not scalable. Is it possible to handle 10,000 connections with just one thread?
It is possible to handle 10,000 mostly idle connections with just one thread. What we need to make sure is that whenever a message comes through in one of these connections, it is timely handled.
Conventional system calls like read() and write() block, so they prevent
us from using a single thread to handle concurrent connections, because our
single thread will just be blocked on an idle connection. The solution to
this problem is to not use blocking: we need non-blocking I/O!
Non-blocking I/O: Handle more than 1 connection per thread
read() and write() system calls can in fact be configured to operate in
non-blocking mode. Where a normal read() or write() call would block, the
non-blocking version would simply return -1 with errno set to EAGAIN.
Let's see how we can use non-blocking I/O to implement a beefy thread that can
handle 10,000 connections at once:
int cfd[10000]; // 10K socket fds representing 10K connections
int main(...) {
...
while (true) {
for (int c : cfd) {
int r = read(c);
if (r < 0)
continue;
// handle message
...
r = write(c);
if (r < 0) {
// queue/buffer response
continue;
}
}
}
}
This style of programming using non-blocking I/O is also called event-driven
programming. Of course, in order to handle this many connections within one
thread, we will have to maintain more state in the user level to do
bookkeeping for each connection. For example, when we read from a connection
and it didn't return a message, we need to somehow mark that we are still
awaiting a message from this connection. Likewise, when a write() system
calls fails due to EAGAIN while sending a response, the server will need to
temporarily store the response message somewhere in memory and queue it for
delivery when the network becomes available. These states are not required
when we use blocking I/O because the server processes everything in order.
A non-blocking server can essentially handle connections out-of-order within
a single thread. Nevertheless these user-level overhead is much lower than
the overhead of maintaining thousands of threads.
The server program described above has one significant problem: it does
polling. Polling means high CPU utilization, which means the server runs hot
and consumes a lot of power! It would be ideal if we can block when there is
really no messages to be processes, but wake up as soon as something becomes
available. The select() system call allows us to do exactly that.
select(): Block on multiple fds to avoid polling
Recall the signature of the select() system call:
select(nfds, rfds, wfds, xfds, timeout)
^ read set
^ write set
^ exception setThe select() system call blocks until either the following occurs:
- The timeout elapses
- At least one of the fds in the read set
rfdsbecomes readable (includingEOF)
We can solve the problem of polling by calling select() after the inner
for loop in the server program above:
int cfd[10000]; // 10K socket fds representing 10K connections
int main(...) {
...
while (true) {
for (int c : cfd) {
...
}
select(...);
}
}
We need to add all fds in the cfd[] array to the read set passed to
select(). Now it should solve our problem!
But there is still a lot of overhead in this program. Imagine among the 10,000
connections that are established, most of them are idle and we only have one
connection that are active at a time. In order to find that one active
connection, the for loop has to search through the entire array. And that's
just the overhead in the user space. The select() system call itself has
O(N) performance, where N is the number of fds in its read set. For these
reasons, this code still results in high CPU usage even most connections are
idle. It would be nice if we don't have to do any of this extra work when we
just have a single interesting connection to handle.
Our problem here is that select() does work for each connection in its read
set on every call. We can solve this problem by maintaining a persistent read
set for connections in the kernel, and a blocking system call that returns
only active connections when waking up. This is in comparison to the
interface of select(), where the read set is passed in as a parameter, and
system call API itself is stateless. This API design is the reason why
select() must do O(N) work.
The Linux version of this system call is called epoll.
epoll: Maintaining a persistent read set in the kernel
There are three system calls in the epoll system call family:
epoll_create(): Returns a newepollfile descriptor representing the persistent read set in kernel.epoll_ctl(): Adds/Removes fds to/from the read set.epoll_wait(): The blocking system call. Returns information about active fds in the read set.
This is an example of improved performance by having an alternative design of the interface. By moving the read set to be persistently maintained in the kernel, the interface looks drastically different from
selectalbeit achieving the same functionalities. This enables much better per-call performance when the number of active fds is small but the read set itself is large. Thenginxweb server makes extensive use of theepollsystem calls to handle multiple connections per thread.
Here are some latency numbers on select() vs. epoll_wait(), based on 100K
calls to a server (in microseconds, lowers are better):
| number of fds | select() |
epoll_wait() |
|---|---|---|
| 10 | 0.73 | 0.41 |
| 100 | 3.0 | 0.42 |
| 10000 | 930 | 0.66 |
This O(N) vs. O(1) difference is achieved by an interface change. Identifying issues in interface designs and addressing them by proposing alternative interfaces is one of the goals of systems research.
Where to go next...
Congratulations! You have reached the end of the last lecture! If you become interested in topics introduced in this class and wonder where to go next, here are some suggestions.
If you are hooked with kernels and want to build a full-blown OS with multi- processor support and its own file systems, take CS161 next term with Eddie Kohler and James Mickens.
If you want to hear more about server-less computing, you can take CS260r by Eddie.
If you find the assembly unit most interesting to you in this class, you might want to check out the Computer Architecture course CS141 by David Brooks, where you will learn at a low and deep level of how modern processors work.
If you want to learn about cloud computing, take CS145 with Minlan Yu.
If you want to have the best teacher and learn about programming languages, go check out CS152/CS252 by Steve Chong.
Database classes like CS165/CS265 by Stratos Idreos are also great continuations of CS61, where you will see how topics you learned in this class are really important in designing efficient software.
Thank you all for your effort in this class, and wish everyone a good year!