
Cost of storage
We think a lot in computer science about costs: time cost, space cost, memory efficiency. And these costs fundamentally shape the kinds of solutions we build. But financial costs also shape the systems we build—in some ways more fundamentally—and the costs of storage technologies have changed at least as dramatically as their capacities and speeds.
This table gives the price per megabyte of different storage technology, in price per megabyte (2010 dollars), up to 2018.
| Year | Memory (DRAM) | Flash/SSD | Hard disk |
|---|---|---|---|
| ~1955 | $411,000,000 | $6,230 | |
| 1970 | $734,000.00 | $260.00 | |
| 1990 | $148.20 | $5.45 | |
| 2003 | $0.09 | $0.305 | $0.00132 |
| 2010 | $0.019 | $0.00244 | $0.000073 |
| 2018 | $0.0059 | $0.00015 | $0.000020 |
The same costs relative to the cost of a hard disk in ~2018:
| Year | Memory | Flash/SSD | Hard disk |
|---|---|---|---|
| ~1955 | 20,500,000,000,000 | 312,000,000 | |
| 1970 | 36,700,000,000 | 13,000,000 | |
| 1990 | 7,400,000 | 270,000 | |
| 2003 | 4,100 | 15,200 | 6.6 |
| 2010 | 950 | 122 | 3.6 |
| 2018 | 29.5 | 7.5 | 1 |
These are initial purchase costs and don’t include maintenance or power. DRAM uses more energy than hard disks, which use more than flash/SSD. (Prices from here and here. $1.00 in 1955 had “the same purchasing power” as $9.45 in 2018 dollars.)
There are many things to notice in this table, including the relative changes in prices over time. When flash memory was initially introduced, it was 2300x more expensive per megabyte than hard disks. That has dropped substantially; and that drop explains why large amounts of fast SSD memory is so ubiquitous on laptops and phones.
Performance metrics
Latency measures the time it takes to complete a request. Latency is bad: lower numbers are better.
Throughput (also called bandwidth) measures the number of operations that can be completed per unit of time. Throughput is good: higher numbers are better.
In storage, latency is typically measured in seconds and throughput in operations per second, or in bytes per second or megabytes per second (assuming the operations transfer different numbers of bytes).
The best storage media have low latency and high throughput: it takes very little time to complete a request, and many units of data can be transferred per second.
Latency and throughput are not simple inverses: a system can have high latency and high throughput. A classic example of this is “101Net,” a high-bandwidth, high-latency network that has many advantages over the internet. Rather than send terabytes of data over the network, which is expensive and can take forever, just put some disk drives in a car and drive it down the freeway to the destination data center. The high information density of disk drives makes this high-latency, high-throughput channel hard to beat in terms of throughput and expense for very large data transfers. Amazon Web Services offers physical-disk transport; you can mail them a disk using the Snowball service, or if you have around 100 petabytes of storage (that’s roughly 1017 bytes!!?!?!?!?!) you can send them a shipping container of disks on a truck. Look, here it is.

“Successful startups, given the way they collect data, have exabytes of data,” says the man introducing the truck, so the truck is filled with 1017 bytes of tracking data about how long it took you to favorite your friend’s Pokemon fashions or whatever and we are not not living in hell.
(101Net is a San Francisco version of the generic term sneakernet. XKCD took it on.)
Stable and volatile storage
Computer storage technologies can be either stable or volatile.
Stable storage is robust to power outages. If the power is cut to a stable storage device, the stored data doesn’t change.
Volatile storage is not robust to power outages. If the power is cut to a volatile storage device, the stored data is corrupted and usually considered totally lost.
Registers, SRAM (static random-access memory—the kind of memory used for processor caches), and DRAM (dynamic random-access memory—the kind of memory used for primary memory) are volatile. Disk drives, including hard disks, SSDs, and other related media are stable.
Aside: Stable DRAM?
However, even DRAM is more stable than one might guess. If someone wants to steal information off your laptop’s memory, they might grab the laptop, cool the memory chips to a low temperature, break open the laptop and transplant the chips to another machine, and read the data there.
Here’s a video showing DRAM degrading after a power cut, using the Mona Lisa as a source image.
Storage performance
This table lists the storage technologies in a typical computer, starting from the smallest and fastest and ending at the largest and slowest.
| Storage type | Capacity | Latency | Throughput (random access) | Throughput (sequential) |
|---|---|---|---|---|
| Registers | ~30 (1KB) | 0.5 ns | 16 GB/sec (2x109 accesses/sec) | |
| SRAM (processor caches) | 9MB | 4 ns | 1.6 GB/sec (2x108 accesses/sec) | |
| DRAM (main memory) | 8GB | 70 ns | 100 GB/sec | |
| SSD (stable storage) | 512GB | 60 µs | 550 MB/sec | |
| Hard disk | 2–5TB | 4–13 ms | 1 MB/sec | 200 MB/sec |
The performance characteristics of hard disks are particularly interesting. Hard disks can access data in sequential access patterns much faster than in random access patterns. (More on access patterns) This is due to the costs associated with moving the mechanical “head” of the disk to the correct position on the spinning platter. There are two such costs: the seek time is the time it takes to move the head to the distance from the center of the disk, and the rotational latency is the time it takes for the desired data to spin to underneath the head. Hard disks have much higher sequential throughput because once the head is in the right position, neither of these costs apply: sequential regions of the disk can be read as the disk spins. This is just like how a record player plays continuous sound as the record spins underneath the needle. A typical recent disk might rotate at 7200 RPM and have ~9ms average seek time, ~4ms average rotational latency, and 210MB/s maximum sustained transfer rate. (CS:APP3e)
These technologies are frequently called the storage hierarchy, and shown this way:
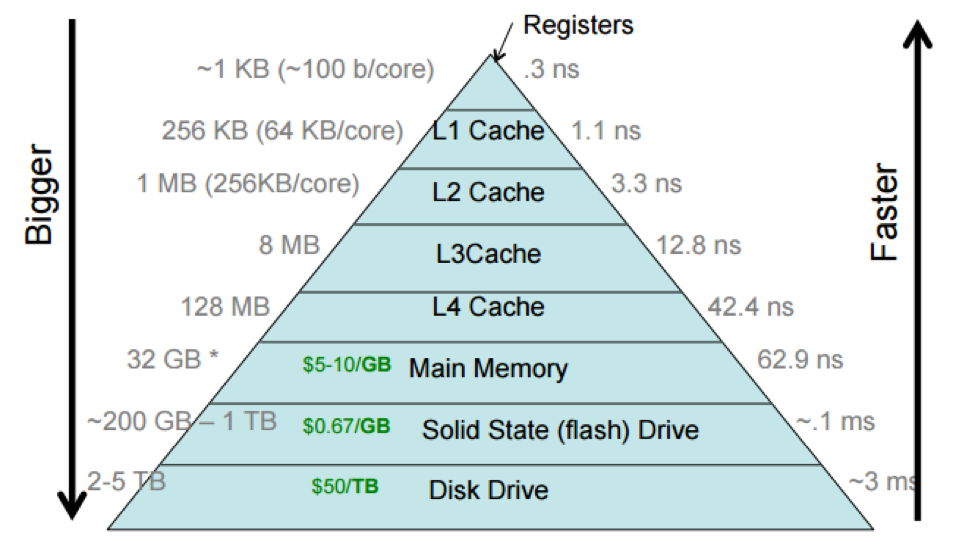
The storage hierarchy shows the processor caches divided into multiple levels, with the L1 cache (sometimes pronounced “level-one cache”) closer to the processor than the L4 cache. This reflects how processor caches are actually laid out, but we often think of a processor cache as a single unit.
Different computers have different sizes and access costs for these hierarchy levels; the ones above are typical, but here are some more, based on those for my desktop iMac, which has four cores (i.e., four independent processors): ~1KB of registers; ~9MB of processor cache; 8GB primary memory; 512GB SSD; and 2TB hard disk. The processor cache divides into three levels. There are 128KB of L1 cache, divided into four 32KB components; each L1 cache is accessed only by a single core, which makes accessing it faster, since there’s no need to arbitrate between cores. There are 512KB of L2 cache, divided into two 256KB components (one per “socket”, or pair of cores). And there are 8MB of L3 cache shared by all cores.
And distributed systems have yet lower levels. For instance, Google and Facebook have petabytes or exabytes of data, distributed among many computers. You can think of this as another storage layer, networked storage, that is typically slower to access than HDDs.
Each layer in the storage hierarchy acts as a cache for the following layer.
Latency Numbers Every Programmer Should Know
Cache model
We describe a generic cache as follows.
Fast storage is divided into slots.
- Each slot is capable of holding data from slow storage.
- A slot is empty if it contains no data. It is full if it contains data from slow storage.
- Each slot has a name (for instance, we might refer to “the first slot” in a cache).
Slow storage is divided into blocks.
- Each block can fit in a slot.
- Each block has an address.
- If a cache slot (in fast storage) is full, meaning it holds data from a block (in slow storage), it must also know the address of that block.
There are some terms that are used in the contexts of specific levels in the hierarchy; for instance, a cache line is a slot in the processor cache (or, sometimes, a block in memory).
Read caches must respond to user requests for data at particular addresses. On each access, a cache typically checks whether the specified block is already loaded into a slot. If it is, the cache returns that data; otherwise, the cache first loads the block into some slot, then returns the data from the slot.
A cache access is called a hit if the data is already loaded into a cache slot, and a miss otherwise. Cache hits are good because they are cheap. Cache misses are bad: they incur both the cost of accessing the cache and the cost of accessing the slower storage. We want most accesses to hit. That is, we want a high hit rate, where the hit rate is the fraction of accesses that hit.
Eviction policies and reference strings
When a cache becomes full, we may need to evict data currently in the cache to accommodate newly required data. The policy the cache uses to decide which existing slot to vacate (or evict) is called the eviction policy.
We can reason about different eviction policies using sequences of addresses called reference strings. A reference string represents the sequence of blocks being accessed by the cache’s user. For instance, the reference string “1 2 3 4 5 6 7 8 9” represents nine sequential accesses.
For small numbers of slots, we can draw how a cache responds to a reference string for a given number of slots and eviction policy. Let’s take the reference string “1 2 3 4 1 2 5 1 2 3 4 5”, and an oracle eviction policy that makes the best possible eviction choice at every step. Here’s how that might look. The cache slots are labeled with Greek letters; the location of an access shows what slot was used to fill that access; and misses are circled.
| 1 | 2 | 3 | 4 | 1 | 2 | 5 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | ① | 1 | 1 | ③ | ||||||||
| β | ② | 2 | 2 | ④ | ||||||||
| γ | ③ | ④ | ⑤ | 5 |
Some notes on this diagram style: At a given point in time (a given column), read the cache contents by looking at the rightmost numbers in or before that column. The least-recently-used slot has the longest distance to the most recent reference before the column. And the least-recently-loaded slot has the longest distance to the most recent miss before the column (the most recent circled number).
The hit rate is 5/12.
What the oracle’s doing is the optimal cache eviction policy: Bélády’s optimal algorithm, named after its discoverer, László Bélády (the article). This algorithm selects for eviction a slot whose block is used farthest in the future (there might be multiple such slots). It is possible to prove that Bélády’s algorithm is optimal: no algorithm can do better.
Unfortunately, it is possible to use the optimal algorithm only when the complete sequence of future accesses is known. This is rarely possible, so operating systems use other algorithms instead.
LRU
The most common algorithms are variants of Least Recently Used (LRU) eviction, which selects for eviction a slot that was least recently used in the reference string. Here’s LRU working on our reference string and a three-slot cache.
| 1 | 2 | 3 | 4 | 1 | 2 | 5 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | ① | ④ | ⑤ | ③ | ||||||||
| β | ② | ① | 1 | ④ | ||||||||
| γ | ③ | ② | 2 | ⑤ |
LRU assumes locality of reference: if we see a reference, then it’s likely we will see another reference to the same location soon.
FIFO
Another simple-to-specify algorithm is First-In First-Out (FIFO) eviction, also called round-robin, which selects for eviction the slot that was least recently evicted. Here’s FIFO on our reference string.
| 1 | 2 | 3 | 4 | 1 | 2 | 5 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | ① | ④ | ⑤ | 5 | ||||||||
| β | ② | ① | 1 | ③ | ||||||||
| γ | ③ | ② | 2 | ④ |
Larger caches
We normally expect that bigger caches work better. If a cache has more slots, it should have a higher hit rate. And this is generally true—but not always! Here we raise the number of slots to 4 and evaluate all three algorithms.
| 1 | 2 | 3 | 4 | 1 | 2 | 5 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | ① | 1 | 1 | ④ | ||||||||
| β | ② | 2 | 2 | |||||||||
| γ | ③ | 3 | ||||||||||
| δ | ④ | ⑤ | 5 |
| 1 | 2 | 3 | 4 | 1 | 2 | 5 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | ① | 1 | 1 | ⑤ | ||||||||
| β | ② | 2 | 2 | |||||||||
| γ | ③ | ⑤ | ④ | |||||||||
| δ | ④ | ③ |
| 1 | 2 | 3 | 4 | 1 | 2 | 5 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | ① | 1 | ⑤ | ④ | ||||||||
| β | ② | 2 | ① | ⑤ | ||||||||
| γ | ③ | ② | ||||||||||
| δ | ④ | ③ |
The optimal and LRU algorithms’ hit rates improved, but FIFO’s hit rate dropped!
This is called Bélády’s anomaly (the same Bélády): for some eviction algorithms, hit rate can decrease with increasing numbers of slots. FIFO suffers from the anomaly. But even some simple algorithms do not: LRU is anomaly-proof.
The argument is pretty simple: Adding a slot to an LRU cache will never turn a hit into a miss, because if an N-slot LRU cache and an (N+1)-slot LRU cache process the same reference string, the contents of the N-slot cache are a subset of the contents of the (N+1)-slot cache at every step. This is because for all N, an LRU cache with N slots always contains the N most-recently-used blocks—and the N most-recently-used blocks are always a subset of the N+1 most-recently-used blocks.
Implementing eviction policies
The cheapest policy to implement is FIFO, because it doesn’t keep track of any facts about the reference string (the least-recently-evicted slot is independent of reference string). LRU requires the cache to remember when slots were accessed. This can be implemented precisely, by tracking every access, or imprecisely, with sampling procedures of various kinds. Bélády’s algorithm can only be implemented if the eviction policy knows future accesses, which requires additional machinery—either explicit information from cache users or some sort of profiling information.
Cache associativity
Let's a consider a cache with S total slots for B total blocks (of slow storage).
In a fully-associative cache, any block can fit in any slot.
In a set-associative cache, the block with address A can fit in a subset of the slots called C(A). For example, a cache might reserve even-numbered slots for blocks with even-numbered addresses.
In a direct-mapped cache, each block can fit in exactly one slot. For example, a cache might require that the block with address A go into slot number (A mod S).
Fully-associative and direct-mapped caches are actually special cases of set-associative caches. In a fully-associative cache, C(A) always equals the whole set of slots. In a direct-mapped cache, C(A) is always a singleton.
Another special case is a single-slot cache. In a single-slot cache, S = 1: there is only one slot. A single-slot cache is kind of both direct-mapped and fully-associative. The stdio cache is a single-slot cache.
Single-slot caches and unit size
You might think that single-slot caches are useless unless the input reference string has lots of repeated blocks. But this isn’t so because caches can also change the size of data requested. This effectively turns access patterns with few repeated accesses into access patterns with many repeated accesses, for example if the cache’s user requests one byte at a time but the cache’s single slot can contain 4,096 bytes. (More in section notes)
Consider reading, for example. If the user only requests 1 byte at a time, and the cache reads 4096 bytes at once, then every subsequent read for the next 4095 bytes from the application can be easily fulfilled from the cache, without reaching out to the file system.
On the other hand, if the user reads more than 4,096 bytes at once, then a naively-implemented stdio cache might have unfortunate performance. It might read 4,096 bytes at a time, rather than in a single go, thus making more system calls than necessary.