
Threads reference
We've talked about the concept of threads plenty in lecture, so we're going to start off with just a brief review of thread syntax.
Threads in C++
std::thread's constructor takes the name of the function to run on the new
thread and any arguments, like std::thread t(func, param1, ...).
Given a thread t, t.join() blocks the current thread until the thread
being joined exits. (This is roughly analogous to waitpid.) t.detach() sets
the t thread free. Each thread object must be detached or joined before it
goes out of scope (is destroyed).
An example of how we might combine these is:
#include <thread>
void foo(...) {
...
}
void bar(...) {
...
}
int main() {
{
std::thread t1(foo, ...);
t1.detach();
}
{
std::thread t2(bar, ...);
t2.join();
}
}
Exercise: What can this code print?
int main() {
for (int i = 0; i != 3; ++i) {
std::thread t(printf, "%d\n", i + 1);
t.join();
}
}
1\n2\n3\n
Exercise: What can this code print?
int main() {
for (int i = 0; i != 3; ++i) {
std::thread t(printf, "%d\n", i + 1);
t.detach();
}
}
123, in any order, and with any number of those lines left out—because when the main thread exits (by returning frommain) all other threads are killed too!
Exercise: What can this code print?
int main() {
for (int i = 0; i != 3; ++i) {
std::thread t(printf, "%d\n", i + 1);
}
}
Literally anything. This is not C++ code: when the
tthread goes out of scope without having been joined or detached, it invokes undefined behavior.
Threads in C
C doesn't have built-in threads or synchronization, but a common library is pthread (POSIX
threads). Since we're using C++ threads in this class we won't talk about
details here, but be aware that it exists in case you're ever working in C.
(On Linux, standard C++ threads are implemented using the pthread library.)
Synchronization reference
Recall the high-level definition of a mutex: we want some way to synchronize access to data that is accessed simultaneously by multiple threads to avoid race conditions. Mutexes (also known as locks) achieve this by providing mutual exclusion, meaning that only one thread can be running in a particular critical section at any time.
The abstract interface for a mutex or lock is:
lock: takes hold of the lock in a blocking fashiontry lock: takes hold of the lock in a polling fashion; returns a boolean indicating whether the lock attempt succeededunlock: instantly lets go of the lock
Note that it is disallowed to lock a lock that you already hold or unlock a lock that you do not hold. Depending on the implementation or language you're using, these actions might explicitly fail or—even worse—silently fail, and cause deadlock or incorrect synchronization.
If you've ever had the pleasure of participating in an icebreaker, you can think of a single lock as the object that is passed around to allow people to speak. You have to acquire the object before you can speak, and you release it so that another person can use it once you're done. Because there's one object and only one person can hold it at once, only one person can speak at a time, achieving mutual exclusion.
For multiple mutexes, a better analogy is the locks on a set of bathroom stalls.
When you enter a stall (the critical section) you lock the lock associated with
that stall. Then, you perform whatever operation needs to be synchronized inside
the stall. Finally, once you're done, you unlock the stall and go on your merry
way. This system ensures that each stall can only have one person in it at a
time. Here the difference between lock and try lock is better motivated: if
one particular stall is full, we might want to check to see if other stalls are
available instead of waiting for someone to leave that one.
Synchronization in C++
At some point in the next few weeks you might want to synchronize something in C++. Here are some of the tools you can use to do that (and here is some even more comprehensive documentation).
Mutexes
C++ has a few different kinds of locks built in.
std::mutex is the basic mutex we all know and love. Once we declare and
construct a std::mutex m, we can call:
m.lock()m.try_lock()m.unlock()
which correspond exactly to the abstract lock operations defined above. A typical use might look like this, though later we're going to talk about an easier way to get the same behavior:
#include <mutex>
int i;
std::mutex m; // protects write access to i
void increase() {
m.lock();
i++;
m.unlock();
}
...
std::recursive_mutex is like a normal mutex, but a thread that holds a lock
may recursively acquire it again (as long as they recursively release it the
same number of times). This might be useful if you need to acquire several
locks, and sometimes some of those locks might actually be the same lock: with
recursive locks, you don't need to keep track of which ones you already hold,
to avoid acquiring the same lock twice.
std::shared_lock is an instantiation of a different kind of lock altogether:
a readers-writer lock, or a shared-exclusive lock. The idea behind this kind of
lock is that rather than just have one level of access--mutual exclusion--there
are two levels of access: shared access and exclusive access. When a thread
holds the lock with shared access, that guarantees that all other threads that
hold the lock have shared access. When a thread holds the lock with exclusive
access, that guarantees that it is the only thread to have any kind of access.
We call this a readers-writer lock because the two levels of access often
correspond to multiple reader threads, which require the shared data not to
change while they're accessing it, but don't modify it themselves; and a single
writer thread, which needs to be the only thread with access to the data it's
modifying. You do not need the functionality of std::shared_lock for the
problem set, and in fact it is not particularly helpful for this particular
application.
The only mutex you need for the problem set is std::mutex, though
std::recursive_mutex may simplify some logic for simpong61.
Mutex Management
C++ also defines some handy tools to acquire locks while avoiding deadlock.
Instead of calling .lock() on the mutex itself, you can pass several mutexes
as arguments to the function std::lock, which uses C++ magic to acquire the
locks in an order that automatically avoids deadlock.
Here's an example of how this works:
#include <mutex>
std::mutex a;
std::mutex b;
void worker1() {
std::lock(a, b);
...
a.unlock(); // the order of these doesn't matter,
b.unlock(); // since unlocking can't cause deadlock
}
void worker2() {
std::lock(b, a); // look ma, no deadlock!
...
b.unlock();
a.unlock();
}
...
If it's too much of a burden to manually unlock all your locks, or if you don't
trust yourself to remember to do so (we humans are quite careless), then std::scoped_lock is your best bet.
This works the same as std::lock, except it automatically unlocks the mutexes
when it leaves scope (leave the level of curly braces in which the scoped_lock
occurs). This is an instance of an idiom called Resource acquisition is
initialization (RAII), which is the idea that an object's resources are
automatically acquired and released by its constructor and destructor, which are
triggered by scope. This means that std::scoped_lock constructs an object
that acquires all the locks passed to it, and releases them when destructed,
whereas std::lock is just a function that acquires the locks. Here's how it
would simplify the code above:
#include <mutex>
std::mutex a;
std::mutex b;
void worker1() {
std::scoped_lock guard(a,b);
...
}
void worker2() {
std::scoped_lock guard(b,a);
...
}
...
Condition Variables
Suppose you have several threads waiting for some event to happen, which doesn't neatly correspond to a single unlock event. (For example, to go back to the bathroom example, we might want people lining up to wait for any stall to open, not some particular stall door to be unlocked.) We could achieve this behavior naively by polling, but we've seen that this is wasteful. Condition variables are a synchronization primitive built on top of mutexes that allows us to form a queue of threads, which wait in line for a wake up call. (Note that condition variables usually do not actually guarantee that they function as FIFO queues; an arbitrary thread may be the head of the queue.)
The abstract interface for a condition variable is:
wait: go to sleep on the condition variable and a held lock until signalednotify oneorsignal: wake up one thread waiting on the CVnotify allorbroadcast: wake up all threads waiting on the CV
Once we create a condition variable std::condition_variable cv in C++, we can
call:
cv.wait(std::unique_lock<std::mutex>& lock)cv.notify_one()cv.notify_all()
You probably noticed that cv.wait takes something we haven't seen before as
a parameter: a std::unique_lock<std::mutex>&. Rather than use std::lock or
std::scoped_lock, you must use std::unique_lock for condition
variables. For other purposes, there is no meaningful difference between
std::unique_lock and std::scoped_lock, but for condition variables the
types must match up. The lock must be locked when calling wait(). wait()
unlocks the associated mutex while waiting, and re-locks the mutex before it returns.
Condition variables are almost always used in loops that look like this:
std::unique_lock<std::mutex> lock;
...
while (!CONDITION) {
cv.wait(lock);
}
In this code:
CONDITIONis some expression, such asphase != 1.- The
CONDITIONcan safely be evaluated whenlockis locked. cvis associated withCONDITIONin the following way: Any code that might change the truth value ofCONDITIONwill callcv.notify_all().
The loop is important because in most cases, a condition variable wait can
wake up spuriously—in other words, by the time the wait operation returns,
the condition has gone back to false.
If you want to use a condition variable with something other than a
std::mutex, you'll have to usestd::condition_variable_anyinstead.
Synchronization: Counting to three
Here is some code.
#include <thread>
#include <mutex>
#include <condition_variable>
#include <cstdio>
/* G1 */
void a() {
/* A1 */
printf("1\n");
/* A2 */
}
void b() {
/* B1 */
printf("2\n");
/* B2 */
}
void c() {
/* C1 */
printf("3\n");
/* C2 */
}
int main() {
/* M1 */
std::thread at(a);
std::thread bt(b);
std::thread ct(c);
/* M2 */
ct.join();
bt.join();
at.join();
}
Exercise: What are the possible outputs of this program as is?
1,2, and3, on separate lines, in any order. (printfis thread-safe, so no two calls toprintfwill interleave characters.)
Exercise: The program will never exit with the output 1\n2\n. Why not?
The
ct.join()line means that threadct, which is runningc(), must exit before the main program exits.
Exercise: Add code to this program so that the program only prints
1\n2\n3\n. Your code must only use atomics, and you can only change the
locations marked with comments.
G1: std::atomic<int> phase; A2: phase.store(1); B1: while (phase.load() != 1) {} B2: phase.store(2); C1: while (phase.load() != 2) {}
Exercise: Does your atomics-based code wait using blocking or polling?
Polling
Exercise: Add code to this program so that the program only prints
1\n2\n3\n. Your code must only use std::mutex and/or
std::condition_variable, and you must not ever unlock a mutex in a thread
different from the thread that locked the mutex. Again, only change the
locations marked with comments.
G1: int phase = 0; std::mutex mutex; std::condition_variable cv; A2: std::unique_lock<std::mutex> lock(mutex); phase = 1; cv.notify_all(); B1: std::unique_lock<std::mutex> lock(mutex); while (phase != 1) { cv.wait(lock); } B2: phase = 2; cv.notify_all(); C1: std::unique_lock<std::mutex> lock(mutex); while (phase != 2) { cv.wait(lock); }
Deadlock
A deadlock is a situation in which two or more threads block forever, because each thread is waiting for a resource that’s held by another thread.
Deadlock in multithreaded programming commonly involves mutual exclusion
locks. For instance, thread 1 might have mutex m1 locked while it tries to
acquire mutex m2, while thread 2 has m2 locked while it tries to acquire
m1. Neither thread will ever make progress because each is waiting for the
other.
There are simple ways to avoid deadlock in practice. One is to lock at most
one mutex at a time: no deadlock! Another is to have a fixed order in which
mutexes are locked, called a lock order. For instance, given lock order
m1, m2, then thread 2 above cannot happen (it’s acquiring locks against
the lock order).
Deadlocks can also occur with other resources, such as space in pipe buffers (remember the extra credit in pset 3?) and even pavement.

Bathroom synchronization
Ah, the bathroom. Does anything deserve more careful consideration? Is anything more suitable for poop jokes?
Bathroom 1: Stall privacy
In this exercise, the setting is a bathroom with K stalls numbered 0 through K–1. A number of users enter the bathroom; each has a preferred stall. Each user can be modeled as an independent thread running the following code:
void user(int preferred_stall) {
poop_into(preferred_stall);
}
Two users should never poop_into the same stall at the same time.
You probably can intuitively smell that this bathroom model has a synchronization problem. Answer the following questions without referring to the solutions first.
Question: What synchronization property is missing?
Mutual exclusion (two users can poop into the same stall at the same time).
Question: Provide synchronization using a single mutex, i.e., using
coarse-grained locking. Your solution should be correct (it should avoid
gross conditions [which are race conditions in the context of a
bathroom-themed synchronization problem]), but it need not be efficient.
Your solution will consist of (1) a definition for the mutex, which must be a
global variable, and (2) new code for user(). You don’t need to sweat the
syntax.
std::mutex bmutex; void user(int preferred_stall) { std::scoped_lock guard(bmutex); poop_into(preferred_stall); }
Question: Provide synchronization using fine-grained locking. Your
solution should be more efficient than the previous solution.
Specifically, it should allow the bathroom to achieve full
utilization: it should be possible for all K stalls to be in use at the
same time. You will need to change both the global mutex—there will be
more than one global mutex—and the code for user().
std::mutex stall[K]; void user(int preferred_stall) { std::scoped_lock guard(stall[preferred_stall]); poop_into(preferred_stall); }
Bathroom 2: Stall indifference
The setting is the same, except that now users have no predetermined preferred stall:
void user() {
int preferred_stall = random() % K;
poop_into(preferred_stall);
}
It should be pretty easy to adapt your synchronization solution to this setting, by locking the preferred stall once it’s determined by random choice. But that can leave stalls unused: a user will wait indefinitely if they pick an occupied stall randomly, no matter how many other stalls are available.
Question: Design a solution that solves this problem: each user chooses any available stall, or waits if none are available. Use a single mutex and a single condition variable. You’ll also need some subsidiary data.
std::mutex bmutex; std::condition_variable cv; bool stall_full[K]; int noccupied; void user() { std::unique_lock<std::mutex> lock(bmutex); while (noccupied == K) { cv.wait(lock); } ++noccupied; int stall = 0; while (stall_full[stall]) { ++stall; } stall_full[stall] = true; lock.unlock(); poop_into(stall); lock.lock(); --noccupied; stall_full[stall] = false; cv.notify_all(); lock.unlock(); }
Question: Another solution is possible that uses K mutexes and no
condition variables, and the std::mutex::try_lock() function. Design that
solution.
std::mutex stall[K]; void user() { for (int i = 0; true; i = (i + 1) % K) { if (stall[i].try_lock()) { poop_into(i); stall[i].unlock(); return; } } }
Bathroom 3: Pooping philosophers
To facilitate the communal philosophical life, Plato decreed that philosophy should be performed in a bathroom with K thrones and K curtains, arranged like so:
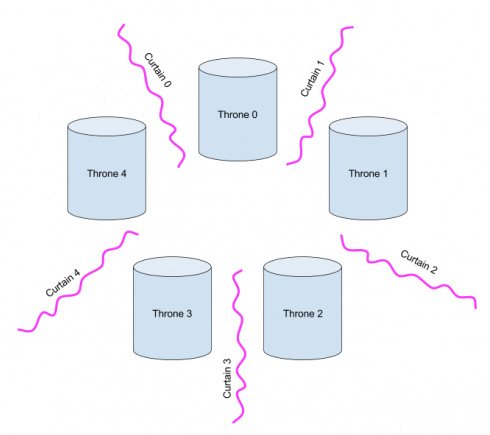
Each philosopher sits on a throne with two curtains, one on each side. The philosophers normally argue with one another. But sometimes a philosopher’s got to poop, and to poop one needs privacy. A pooping philosopher must first draw the curtains on either side; philosopher X will need curtains X and (X+1) mod K. For instance, here, philosophers 0 and 2 can poop simultaneously, but philosopher 4 cannot poop until philosopher 0 is done (because philosopher 4 needs curtain 0), and philosopher 1 cannot poop until philosophers 0 and 2 are both done:
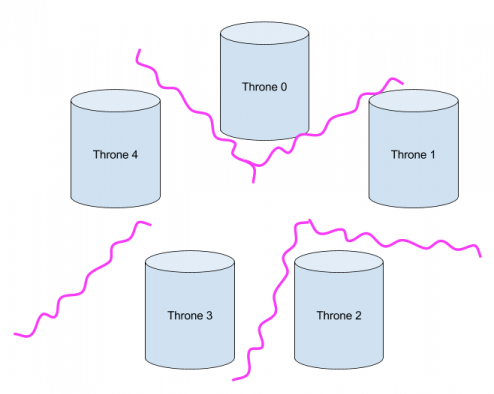
Question: In high-level terms, what is the mutual exclusion problem here—that is, what resources are subject to mutual exclusion?
Curtains. The mutual exclusion problem here is that each philosopher must have 2 curtains in order to poop, and a curtain can only be held by one philosopher at a time.
A philosopher could be described like this:
void philosopher(int x) {
while (true) {
argue();
draw curtains x and (x + 1) % K;
poop();
release curtains x and (x + 1) % K;
}
}
Question: Write a correctly-synchronized version of this philosopher. Your
solution should not suffer from deadlock, and philosophers should block (not
poll) while waiting to poop. First, use std::scoped_lock—which can (magically) lock
more than one mutex at a time while avoiding deadlock.
std::mutex curtains[K]; void philosopher(int x) { while (true) { argue(); std::scoped_lock guard(curtains[x], curtains[(x + 1) % K]); poop(); } }
Question: Can you do it without std::scoped_lock?
Sure; we just enforce our own lock order.
std::mutex curtains[K]; void philosopher(int x) { while (true) { argue(); int l1 = std::min(x, (x + 1) % K); int l2 = std::max(x, (x + 1) % K); std::unique_lock<std::mutex> guard1(curtains[l1]); std::unique_lock<std::mutex> guard2(curtains[l2]); poop(); } }
Designing synchronization
Recall the Fundamental Law of Synchronization: If two threads access the same object concurrently, and at least one of those accesses is a write, that invokes undefined behavior.
In the simpong61 part of the problem set, you’re given code that works
correctly as long as there’s only one thread, and you must synchronize it.
This is actually a very common situation: it’s much easier to start with
correct single-threaded code than to write correct multi-threaded code all at
once.
You can make progress on your synchronization strategy for the problem set by reasoning about which threads modify which objects. This will help you determine which accesses might run afoul of the Fundamental Law.
As is common, many objects in simpong61 are initialized to some value in
the main thread, before any other threads start running. Don’t worry about
those writes as you answer these questions: since no other threads have
started, there’s no problem.
Answer these questions by referring to the handout code.
Question: Which threads modify pong_board::width_ and height_?
None of them do. You can access those variables without synchronization.
Question: Which threads modify pong_cell::type_?
Again, none.
Question: Which threads modify pong_cell::ball_?
Any thread can modify these objects. However, the thread for a ball will only move that ball: it will set
pong_cell::ball_ = nullptrfor its own old position (which must have equaledthisbefore), and it will setpong_cell::ball_ = thisfor its own new position (which must have equalednullptrbefore).
Question: Which threads modify pong_ball::x_ and y_ for ball b? The answer is not
“any thread!”
Only the thread for ball
bmodifiesb->x_andb->y_. That means that the thread for ballbcan examine itsx_andy_without holding any locks! However, any other ball’s thread cannot accessb->x_andb->y_, unless you design some synchronization. Luckily, in our handout code, you’ll notice that each thread only accesses its own ball’sx_andy_.
Question: Which threads modify pong_ball::dx_ and dy_ for ball b?
Any ball’s thread can modify any other ball’s
dx_anddy_, including its own.
For the remaining questions, we are not providing solutions; but if you think
about the questions, you may be able to come up with a synchronization
strategy. Assume a pong board of size WxH with N balls.
Exercise: Design a synchronization strategy with W*H mutexes. How many
mutexes must pong_ball::move lock?
Exercise: Design a synchronization strategy with W mutexes.
Exercise: Design a synchronization strategy with W+2 mutexes. Why is this easier to program than the strategy with exactly W?
Networking reference
So far we've learned about how to communicate between threads with synchronized
variables and processes with inter-process communication like pipes, but how
do we communicate between logical computers? (This might mean between your VM
and host machine, host machine and local network, or even host machine and the
internet at large.) The physical resources that computers use to connect over
networks are network sockets, which, like all system resources, are managed by
the operating system. Our use of sockets is therefore mediated by the socket
family of system calls.
Sockets have two sets of behavior: client and server. The server socket is set up ahead of time and waits for incoming connections, then the client later sets up its own socket and connects to the waiting server socket. Once the client and server are connected, each of their file descriptors works as a bidirectional stream.
In both the client and server cases, you use the socket() system call to
create a new, not-yet-connected network file descriptor.
int socket(int domain, int type, int protocol)
In the server case, we next have to perform the following system calls:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
bind()assigns a particular address to the socket file descriptor created withsocket(). This is non-blocking.
int listen(int sockfd, int backlog)
listen()starts listening for incoming connection requests, and allows a queue of lengthbacklogof unattended requests to form. This is non-blocking.
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen)
accept()blocks until there is a connection request in the queue, removes the connection from the backlog, and returns a new file descriptor for the new connection. This new file descriptor works as a bidirectional stream of communication with the client, wherever they may be.accept()does not change the underlying socket.
In the client case, we only have to perform one additional system call:
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
connect()connects to the server socket specified byaddr, and blocks until its request is fulfilled by the server callingaccept(). Once this happens, the socket file descriptor passed toconnect()becomes a bidirectional stream for communication with the server.
When you're done with a socket or connection as either a client or a server,
make sure to close() it: it's ultimately just another kind of file.
Question: How are sockets different from pipes?
Sockets have two different modes of use, client and server, which require different system calls to set up, while pipes have only one. Sockets can be used across machines with protocols like UDP or TCP, while pipes connect processes on the same logical machine. Each file descriptor associated with a socket is also bidirectional, while a pipe has two unidirectional file descriptors: one for reading and the other for writing.