fork() recap
Let's do a quick exercise to remind us of what fork() does. Especially after
creating a "copy" of a process, what's copied and what's not copied. Take a
look at shell3/fork3.cc:
int main() {
printf("Hello from initial pid %d\n", getpid());
pid_t p1 = fork();
assert(p1 >= 0);
pid_t p2 = fork();
assert(p2 >= 0);
printf("Hello from final pid %d\n", getpid());
}
Question: How many lines of output would you expect to see when you run the program?
5 lines. The first
printf()prints one line, only in the parent, and then the secondprintf()will run four times, one in each process (parent + 2 children + 1 grand child).
Question: How many lines of output would you expect if we run the program
and redirect its output to a file (using ./fork3 > f)?
We actually see 8 lines of output in the file. What's going on??
Note that we are using
printf(), which is a stdio library function and not a system call. So there is caching going on. After the firstprintf()is called, the output only gets written to a buffer but not the actual file descriptor. The buffer is in user-space memory and will get duplicated afterfork()is invoked. Therefore every child process has two lines of output in its stdio buffer by the end of its execution, and a total of 8 lines get written to the file in the end.Recall that this buffering only occurs when
stdoutis being redirected to a file. When operating on the console, stdio flushes the buffer after each new line character, making it behaving like a system call. That's why we don't see this effect when running the program in the console without I/O redirection.We can avoid this behavior by calling
flush(stdout)after the firstprintf()call.
Running a new program
The UNIX way: fork-and-exec style
There is a family of system calls in UNIX that executes a new program. The system
call we will discuss here is execv(). At some point you may want to use other
system calls in the exec syscall family. You can use man exec to find more
information about them.
The execv system call (and all system calls in the exec family) performs the
following:
- Blow away the current process's virtual address space
- Begin executing the specified program in the current process
Note that execv does not "spawn" a process. It destroys the current
process. Therefore it's common to use execv in conjunction with fork: we
first use fork() to create a child process, and then use execv() to run a
new program inside the child.
Let's look at the program in shell3/myecho.cc:
int main(int argc, char* argv[]) {
fprintf(stderr, "Myecho running in pid %d\n", getpid());
for (int i = 0; i != argc; ++i) {
fprintf(stderr, "Arg %d: \"%s\"\n", i, argv[i]);
}
}
It's a simple program that prints out its pid and content in its argv[].
We will now run this program using the execv() system call. The "launcher"
program where we call execv is in forkmyecho.cc:
int main() {
const char* args[] = {
"./myecho", // argv[0] is the string used to execute the program
"Hello!",
"Myecho should print these",
"arguments.",
nullptr
};
pid_t p = fork();
if (p == 0) {
fprintf(stderr, "About to exec myecho from pid %d\n", getpid());
int r = execv("./myecho", (char**) args);
fprintf(stderr, "Finished execing myecho from pid %d; status %d\n",
getpid(), r);
} else {
fprintf(stderr, "Child pid %d should exec myecho\n", p);
}
}
The goal of the launcher program is to run myecho with the arguments shown
in the args[] array. We need to pass these arguments to the execv system
call. In the child process created by fork() we call execv to run the
myecho program.
execvandexecvpsystem calls take an array of C strings as the second parameter, which are arguments to run the specified program with. Note that everything here is in C: the array is a C array, and the strings are C strings. The array must be terminated by anullptras a C array contains no length information. You will need to set up this data structure yourself (converting from the C++ counterparts provided in the handout code) in the shell problem set.
Running forkecho gives us outputs like the following:
Child pid 78462 should exec myecho
About to exec myecho from pid 78462
<shell prompt> $ Myecho running in pid 78462
Arg 0: "./myecho"
Arg 1: "Hello!"
Arg 2: "Myecho should print these"
Arg 3: "arguments."We notice that the line "Finished execing myecho from pid..." never gets
printed. The fprintf call printing this message takes place after the
execv system call. If the execv call is successful, the process's address
space at the time of the call gets blown way so anything after execv won't
execute at all. Another way to think about it is that if the execv system
call succeeds, then the system call never returns.
Alternative interface: posix_spawn
Calling fork() and execv() in succession to run a process may appear
counter-intuitive and even inefficient. Imagine a complex program with
gigabytes of virtual address space mapped and it wants to creates a new
process. What's the point of copying the big virtual address space of the
current program if all we are going to do is just to throw everything away and
start anew?
These are valid concerns regarding the UNIX style of process management.
Modern Linux systems provide an alternative system call, called
posix_spawn(), which creates a new process without copying the address space
or destroying the current process. A new program gets "spawned" in a new
process and the pid of the new process is returned via one of the
passed-by-reference arguments. Non-UNIX operating systems like Windows also
uses this style of process creation.
The program in spawnmyecho.cc shows how to use the alternative
interface to run a new program:
int main() {
const char* args[] = {
"./myecho", // argv[0] is the string used to execute the program
"Hello!",
"Myecho should print these",
"arguments.",
nullptr
};
fprintf(stderr, "About to spawn myecho from pid %d\n", getpid());
pid_t p;
int r = posix_spawn(&p, "./myecho", nullptr, nullptr,
(char**) args, nullptr);
assert(r == 0);
fprintf(stderr, "Child pid %d should run myecho\n", p);
}
Note that posix_spawn() takes many more arguments than execv(). This has
something to do with the managing the environment within which the new
process to be run.
In the fork-and-exec style of process creation, fork() copies the current
process's environment, and execv() preserves the environment. The explicit
gap between fork() and execv() provides us a natural window where we can
set up and tweak the environment for the child process as needed, using the
parent process's environment as a starting point.
With an interface like posix_spawn(), however, this aforementioned window no
longer exists and we need to supply more information directly to the system
call itself. We can take a look at posix_spawn's manual page to find out
what these extra nullptr arguments are about, and they are quite
complicated. This teaches an interesting lesson in API design: performance and
usability of an API, in many cases, are a pair of trade-offs. It can take some
very careful studies and several rounds of retrogressions to settle on an
interface design that's both efficient and user-friendly.
The debate of which style of process creation is better has never settled. Modern UNIX operating systems inherited the fork-and-exec style from the original UNIX, where
fork()turned out extremely easy to implement. Modern UNIX systems can executefork()very efficiently without actually performing any substantial copying (using copy-on-write optimization) until necessary. For these reasons, in practice, the performance of the fork-and-exec style is not a common concern.
Running execv() without fork()
Finally let's take a look at runmyecho.cc:
int main() {
const char* args[] = {
"./myecho", // argv[0] is the string used to execute the program
"Hello!",
"Myecho should print these",
"arguments.",
nullptr
};
fprintf(stderr, "About to exec myecho from pid %d\n", getpid());
int r = execv("./myecho", (char**) args);
fprintf(stderr, "Finished execing myecho from pid %d; status %d\n",
getpid(), r);
}
This program now invokes execv() directly, without fork-ing a child first.
The new program (myecho) will print out the same pid as the original
program. execv() blows away the old program, but it does not change the
pid, because no new processes gets created. The new program runs inside the
same process after the old program gets destroyed.
Note on a common mistake
It's sometimes tempting to write the following code when using the fork-and-exec style of process creation:
... // set up
pid_t p = fork();
if (p == 0) {
... // set up environment
execv(...);
}
... // do things are parent
Note that the code executes assuming it's the parent is outside of the if
block. It appears correct because a successful execution of execv blows away
the current program, so the unconditional code following the if block with
execv in the child will never execute. It is, however, not okay to assume
that execv will always succeed (the same can be said with any system call).
If the execv() call failed, the rest of the program will continue execute in
the child, and the child can mistake itself as the parent and run into some
serious logic errors. It is therefore always recommended to explicitly
terminate the child (e.g. by calling exit()) if execv returns an error.
Interprocess communication
Processes operates in isolated address spaces. What if you want processes to talk to each other? After all the entire UNIX programming paradigm relies on programs being able to easily pass along information among themselves.
One way processes can communication with each other is through the file system. Two processes can agree on a file (by name) which they will use for communication. One process then can write to the file, and another process reads from the file. It is possible, but file systems are not exactly built for this purpose. UNIX provides a plethora of specific mechanisms for interprocess communication (IPC).
Simplest form of IPC: exit detection
It's useful for a parent to detect whether/when the child process has exited.
The system call to detect a process exit is called waitpid. Let's look at
waitdemo.cc for an example.
int main() {
fprintf(stderr, "Hello from parent pid %d\n", getpid());
// Start a child
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
usleep(500000);
fprintf(stderr, "Goodbye from child pid %d\n", getpid());
exit(0);
}
double start_time = tstamp();
// Wait for the child and print its status
int status;
pid_t exited_pid = waitpid(p1, &status, 0);
assert(exited_pid == p1);
if (WIFEXITED(status)) {
fprintf(stderr, "Child exited with status %d after %g sec\n",
WEXITSTATUS(status), tstamp() - start_time);
} else {
fprintf(stderr, "Child exited abnormally [%x]\n", status);
}
}
The program does the following:
- Creates a child.
- The child sleeps for half a second, prints out a message, and exits.
- The parent waits for the child to finish, and prints out a message based on the child's exit status.
See section notes for on exit status.
The interesting line in the program is the call to waitpid() in the parent.
Note the last argument to waitpid(), 0, which tells the system call to
block until the child exits. This makes the parent not runnable after
calling waitpid() until the child exists. Blocking, as opposed to polling,
can be a more efficient way to programmatically "wait for things to happen".
It is a paradigm we will see over again in the course.
The effect of the waitpid() system call is that the parent will not print
out the "Child exited..." message until after the child exits. The two
processes are effectively synchronized in this way.
Exit detection communicates very little information between processes. It essentially only communicates the exit status of the program exiting. The fact that it can only deliver the communication after one program has already exited further restricts the types of actions the listening process can take after hearing from the communication. Clearly we would like a richer communication mechanism between processes. If only we can create some sort of channel between two processes which allows them to exchange arbitrary data.
Stream communication: pipes
UNIX operating systems provide a stream communication mechanism called
"pipes". Pipes can be created using the pipe() system call. Each pipe has 2
user-facing file descriptors, corresponding to the read end and the write
end of the pipe.
The signature of the pipe() system call looks like this:
int pipe(int pfd[2]);
A successful call creates 2 file descriptors, placed in array pfd:
pfd[0]: read end of the pipepfd[1]: write end of the pipe
Useful mnemonic to remember which one is the read end:
- 0 is the value of
STDIN_FILENO, 1 is the value ofSTDOUT_FILENO- Program reads from stdin and writes to stdout
pfd[0]is the read end (input end),pfd[1]is the write end (output end)
Data written to pfd[1] can be read from pfd[0]. Hence the name, pipe.
The read end of the pipe can't be written, and the write end of the pipe can't be read. Attempting to read/write to the wrong end of the pipe will result in a system call error (the
read()orwrite()call will return -1).
Let's look at a concrete example in selfpipe.cc:
int main() {
int pfd[2];
int r = pipe(pfd);
assert(r == 0);
char wbuf[BUFSIZ];
sprintf(wbuf, "Hello from pid %d\n", getpid());
ssize_t n = write(pfd[1], wbuf, strlen(wbuf));
assert(n == (ssize_t) strlen(wbuf));
char rbuf[BUFSIZ];
n = read(pfd[0], rbuf, BUFSIZ);
assert(n >= 0);
rbuf[n] = 0;
assert(strcmp(wbuf, rbuf) == 0);
printf("Wrote %s", wbuf);
printf("Read %s", rbuf);
}
In this program we create a pipe, write to the pipe, and then read from the pipe. We then assert that the string we get out of the pipe is the same string we wrote into the pipe. We do everything all within the same process.
Question: Where does the data go after the write but before the read from the pipe?
The data doesn't live in the process's address space! It actually goes into the buffer cache, which is in the kernel address space.
The read() system call blocks when reading from a stream file descriptor
that doesn't have any data to be read. Pipe file descriptors are stream file
descriptors, so reading from an empty pipe will block. write() calls to a
pipe when the buffer is full (because reader the not consuming quickly enough)
will also block. A read() from a pipe returns EOF if all write ends of a
pipe is closed. A pipe can have multiple read ends and write ends, as we will
show below.
So far we've only seen pipe functioning within the same process. Since the
pipe lives in the kernel, it can also be used to pass data between processes.
Let's take a look at childpipe.cc as an example:
int main() {
int pipefd[2];
int r = pipe(pipefd);
assert(r == 0);
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
const char* message = "Hello, mama!\n";
ssize_t nw = write(pipefd[1], message, strlen(message));
assert(nw == (ssize_t) strlen(message));
exit(0);
}
FILE* f = fdopen(pipefd[0], "r");
while (!feof(f)) {
char buf[BUFSIZ];
if (fgets(buf, BUFSIZ, f) != nullptr) {
printf("I got a message! It was “%s”\n", buf);
}
}
printf("No more messages :(\n");
fclose(f);
}
Again we use fork() to create a child process, but before that we created a
pipe first. The fork() duplicates the two pipe file descriptors in the
child, but note that the pipe itself is not duplicated (because the pipe
doesn't live in the process's address space). The child then writes a message
to the pipe, and the same message can be read from the parent. Interprocess
communication!
Note that in the scenario above we have 4 file descriptors associated with
the pipe, because fork() duplicates the file descriptors corresponding to
two ends of a pipe. The pipe in this case has 2 read ends and 2 write ends.
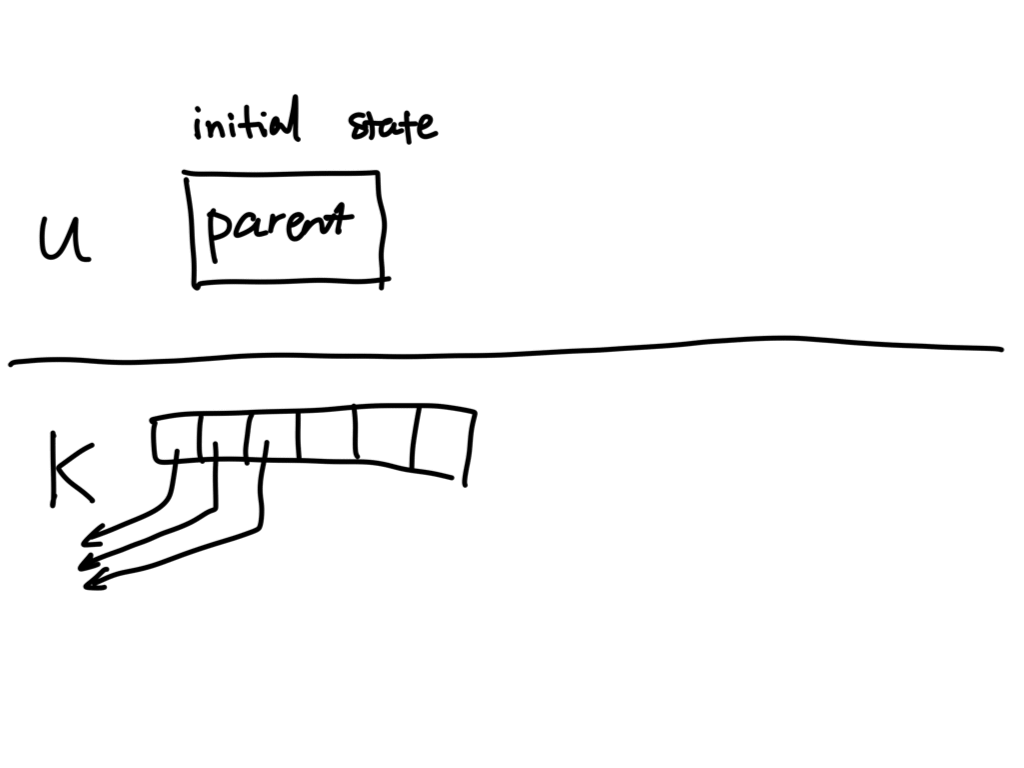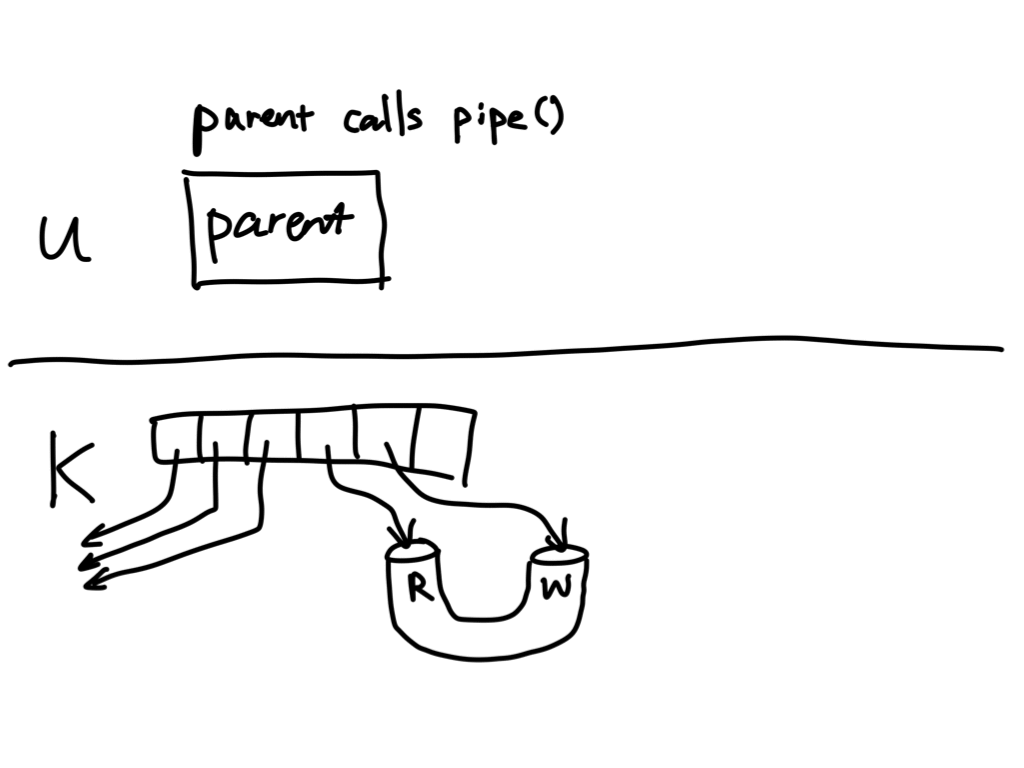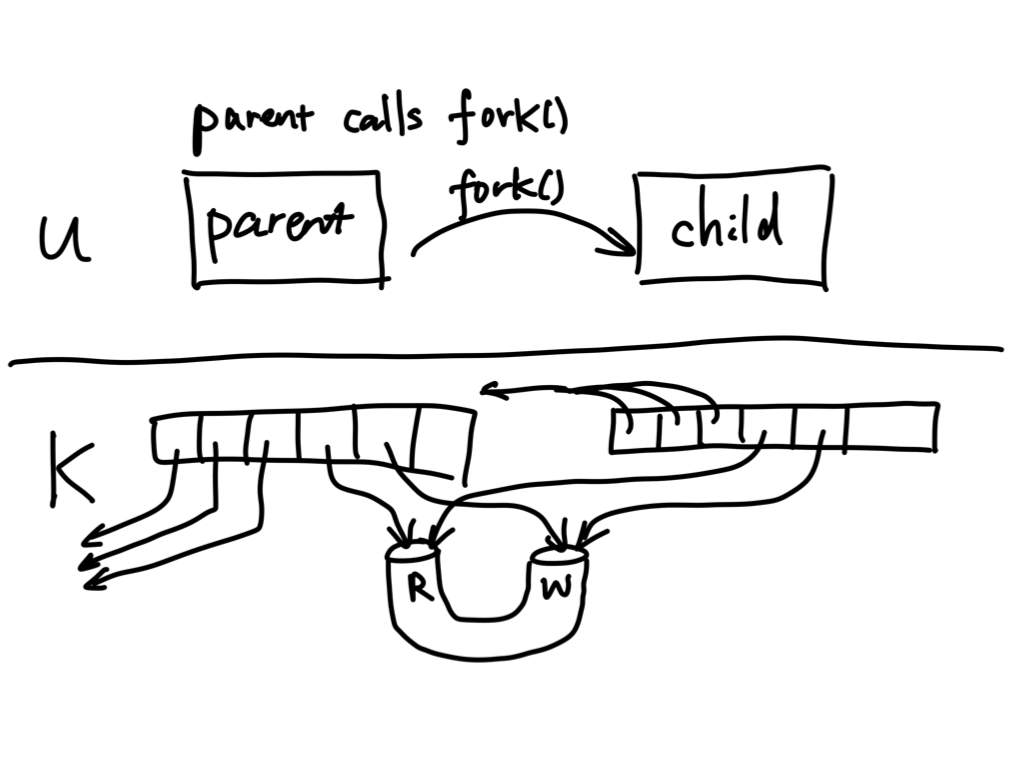
The program doesn't exactly behave as expected, because the parent never receives an end of file (EOF) while reading, so it hangs after printing out the message from the child. This is because there always exists a write end of the pipe in the parent itself that never gets closed.
In order for the program to work, we need to close the write end of the pipe in the parent, after the fork:
...
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
... // child code
}
close(pipefd[1]); // close the write end in the parent
FILE* f = fdopen(pipefd[0], "r");
...
Pipe in a shell
Recall how we connect programs into "pipelines" using a shell:
a | bThis syntax means we create a pipe between a and b, and then let a write
its stdout to the pipe, and let b read its stdin from the pipe. This gives
us the effect of a passing its output to be consumed by b as input.
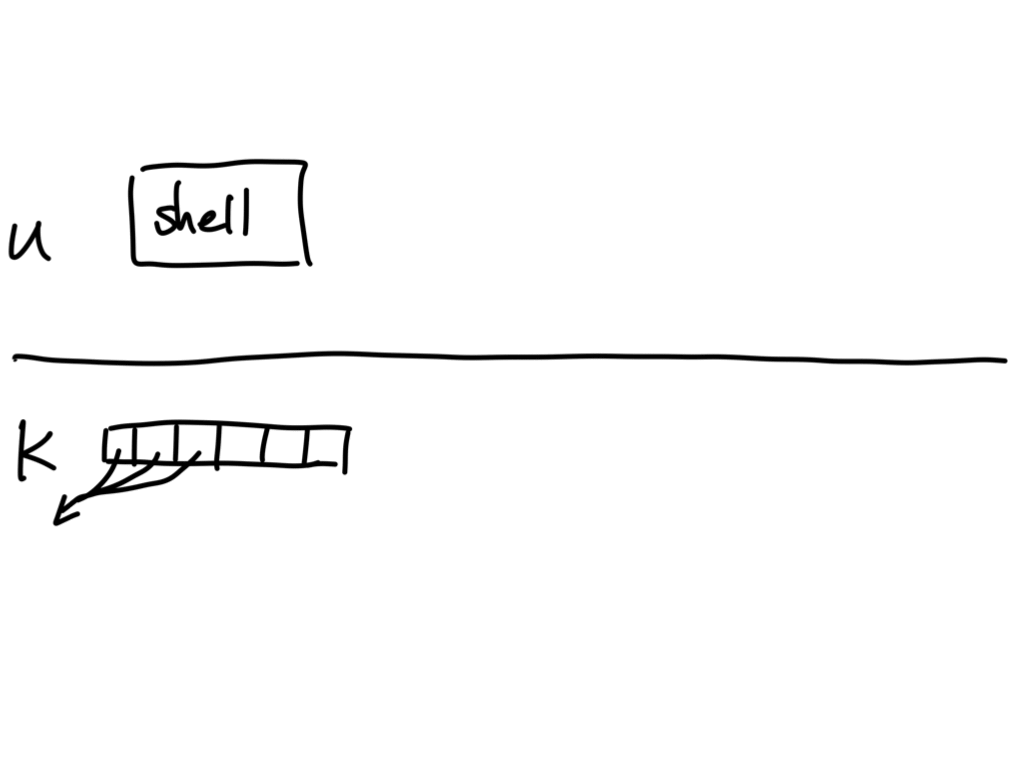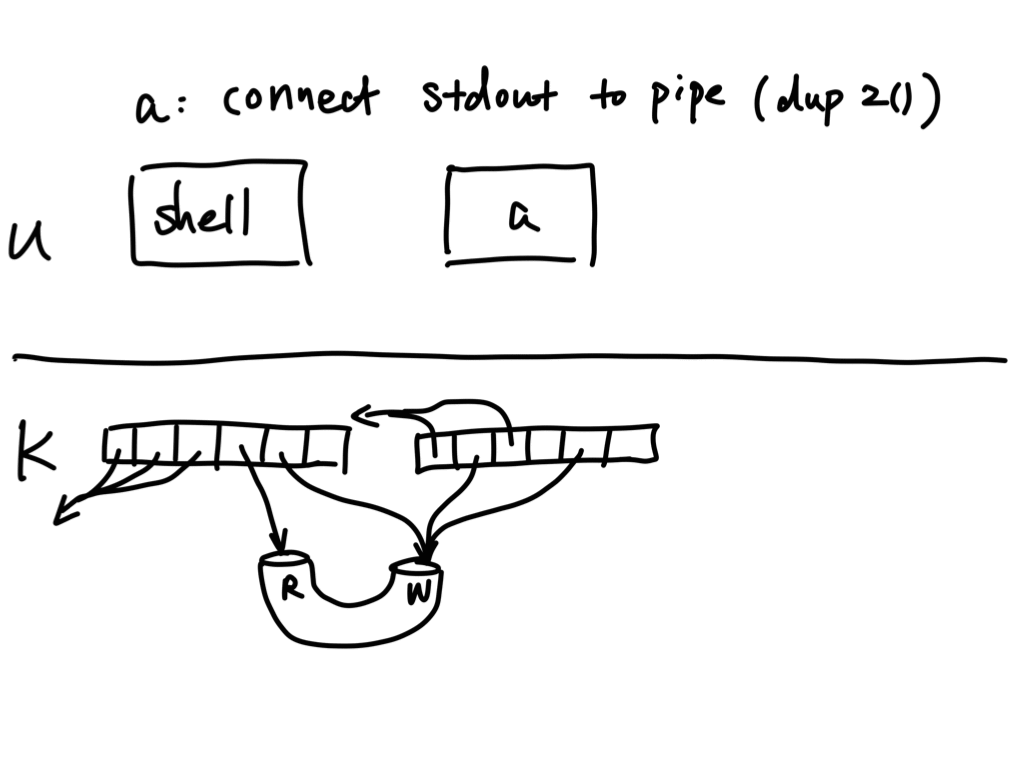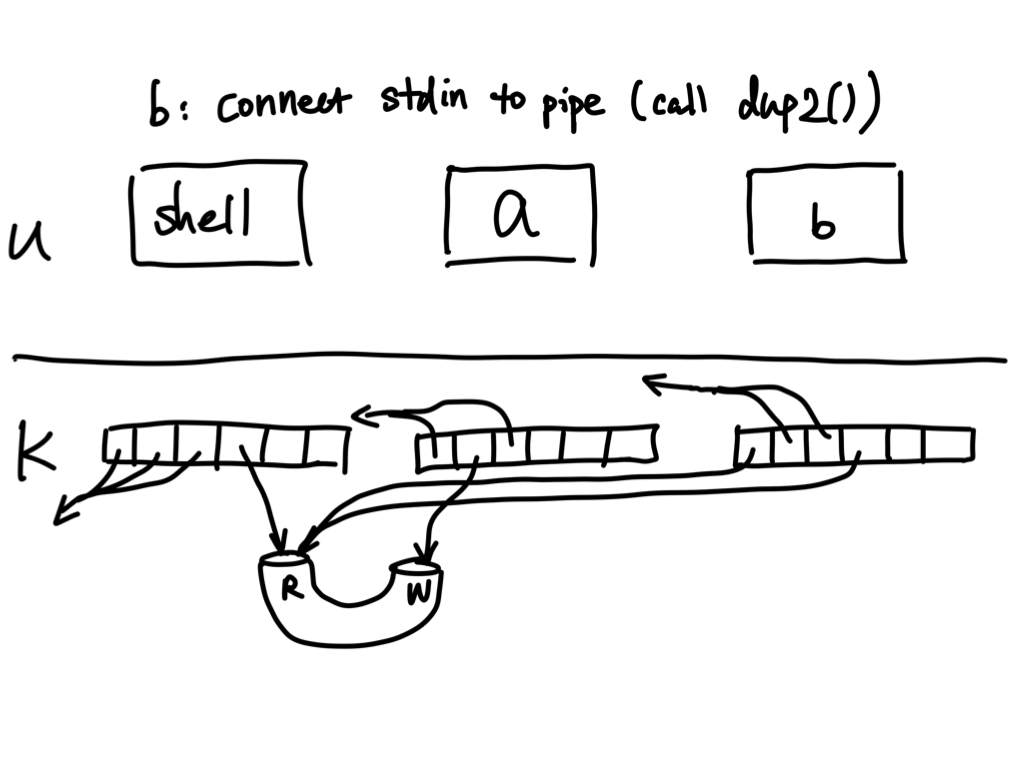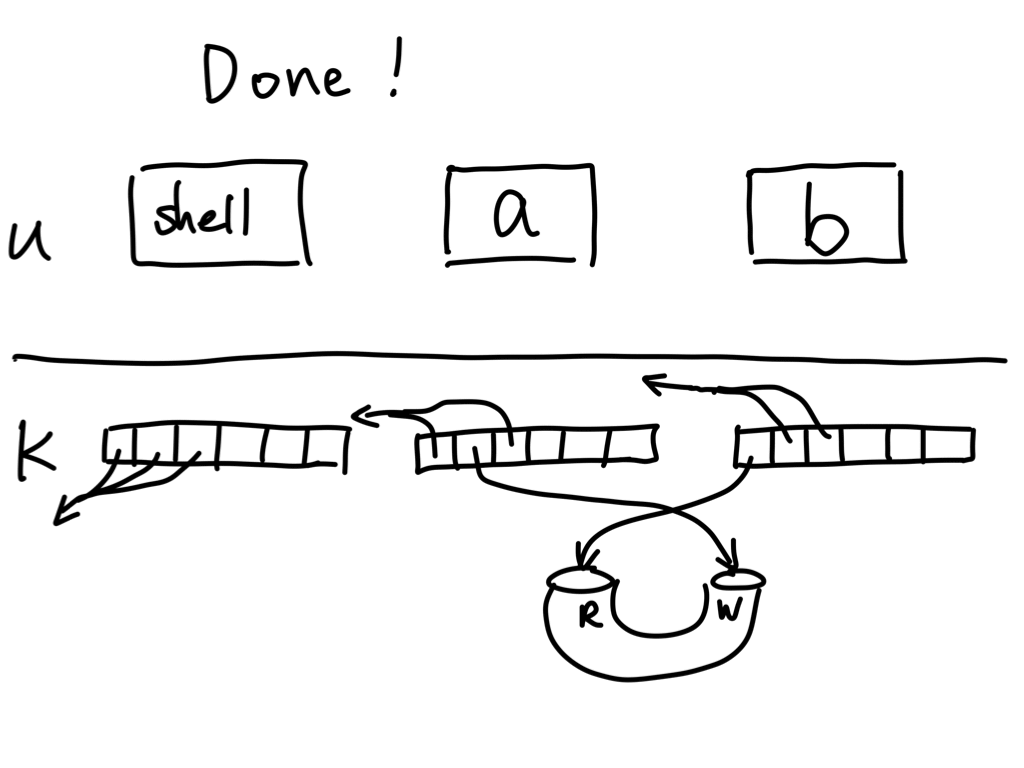
The shell can build up a pipeline as follows:
Start in the parent (shell) process
- Create a pipe using
pipe(); fork()off child process fora;
Now in the child process
- Close
pfd[0]in child process; - Connect
pfd[1]toSTDOUT_FILENOusingdup2(); - Close
pfd[1]; - Run
ausingexecv()in the child;
Now back in the parent
- Back in the parent (shell), close
pfd[1]; fork()off another child process forb;
Now in the child process
- Connect
pfd[0]toSTDIN_FILENOusingdup2(); - Close
pfd[0]; - Run
busingexecv()in the child;
Back in the parent
- Close
pfd[0]in the parent.
We can close the pipe file descriptor after
dup2()becausedup2()makes the two file descriptors point to the same kernel object. UNIX lacks a "rename" feature for file descriptors so we need to manually invokeclose()after thedup2()to achieve effective "rename" a file descriptor.