
Networking
We all use Internet, a type of networking in modern computer systems.
Networking is the OS abstraction for computers to communicate with one another.
It's difficult to think about computer networks without thinking about the underlying infrastructure powering them. In the old days of telephony networks, engineers and telephone operators relied on circuit switching to manage connections for telephone calls, meaning that each telephone connection occupies a physical dedicated phone line. Circuit switching was widely used over a long period of time, even during early days of modern digital computing. Circuit switching significantly underutilized resources in that an idle connection (e.g. periods in a phone conversation when neither party was actively saying anything) must also keep a phone line occupied. Extremely complex circuit switching systems were built as telephone systems expanded, but circuit switching itself is inherently not scalable.
Modern computer networks use packet switching such that computers do not rely on dedicated direct connections to communicate. The physical connections between computers are shared, and the network carries individual packets, instead of full connections. The concept of a connection now becomes an abstraction, implemented by layers of software protocols responsible for transmitting/processing packets and presented to the application software as a stream connection by the operating system. Instead of having direct, dedicated connections to computers over the network you want to talk to, modern computer networks look more like the following, where a lot of the physical infrastructure is widely shared among tens of millions of other computers making up the Internet:
Thanks to packet switching and the extensive sharing of the physical infrastructure it enables, Internet becomes cheap enough to be ubiquitous in our lives today.
Packets
A packet is a unit of data sent or received over the network. Computers communicate to one another over the network by sending and receiving packets. Packets have a maximum size, so if a computer wants to send data that does not fit in a single packet, it will have to split the data to multiple packets and send them separately. Each packet contains:
- Addresses (source and destination)
- Checksum
- to detect data corruption during transmission
- Ports (source and destination)
- to distinguish logical connections to the same machines
- Actual payload data
Networking system calls
A networking program uses a set of system calls to send and receive
information over the network. The first and foremost system call is called
socket().
socket(): Analogous topipe(), it creates a networking socket and returns a file descriptor to the socket.
The returned file descriptor is non-connected -- it has just been initialized
but it is neither connected to the network nor backed up by any files or
pipes. You can think of socket() as merely reserving kernel state for a
future network connection.
Recall how we connect two processes using pipes. There is a parent process
which is responsible for setting everything up (calling pipe(), fork(),
dup2(), close(), etc.) before the child process gets to run a new program
by calling execvp(). This approach clearly doesn't work here, because there
is no equivalent of such "parent process" when it comes to completely
different computers trying to communicate with one another. Therefore a
connection must be set up using a different process with different
abstractions.
In network connections, we introduce another pair of abstractions: a client and a server.
The client is the active endpoint of a connection: It actively creates a connection to a specified server. Example: When you visit
google.com, your browser functions as a client. It knows which server to connect to!The server is the passive endpoint of a connection: It waits to accept connections from what are usually unspecified clients. Example:
google.comservers serve all clients visiting Google.
Client- and server-sides use different networking system calls.
Client-side system call -- connect
connect(fd, addr, len) -> int: Establish a connection.fd: socket file descriptor returned bysocket()addrandlen: C struct containing server address information (including port) and length of the struct- Returns 0 on success and a negative value on failure.
Server-side system calls
On the server side things get a bit more complicated. There are 3 system calls:
bind(fd, ...) -> int: Picks a port and associate it with the socketfd.listen(fd) -> int: Set the state of socketfdto indicate that it can accept incoming connections.accept(fd) -> cfd: Wait for a client connection, and returns a new socket file descriptorcfdafter establishing a new incoming connection from the client.cfdcorrespond to the active connection with the client.
The server is not ready to accept incoming connections until after calling
listen(). It means that before the server calls listen() all incoming
connection requests from the clients will fail.
Among all these system calls mentioned above, only connect() and accept()
involves actual communication over the network, all other calls simply
manipulate local state. So only connect() and accept() system calls
can block.
One interesting distinction between pipes are sockets is that pipes are one way, but sockets are two-way: one can only read from the read end of the pipe and write to the write end of the pipe, but one are free to both read and write from a socket. Unlike regular file descriptors for files opened in Read/Write mode, writing to a socket sends data to the network, and reading from the same socket will receive data from the network. Sockets hence represents a two-way connection between the client and the server, they only need to establish one connect to communicate back and forth.
Connections
A connection is an abstraction built on top of raw network packets. It presents an illusion of a reliable data stream between two endpoints of the connection. Connections are set up in phases, again by sending packets.
Here we are describing the Transmission Control Protocol (TCP). There are other networking protocols that do not use the notion of a connection and deals with packets directly. Google "User Datagram Protocol" or simply "UDP" for more information.
A connection is established by what is known as a three-way handshake process. The client initiates the connection request using a network packet, and then the server and the client exchange one round of acknowledgment packets to establish the connection. This process is illustrated below.
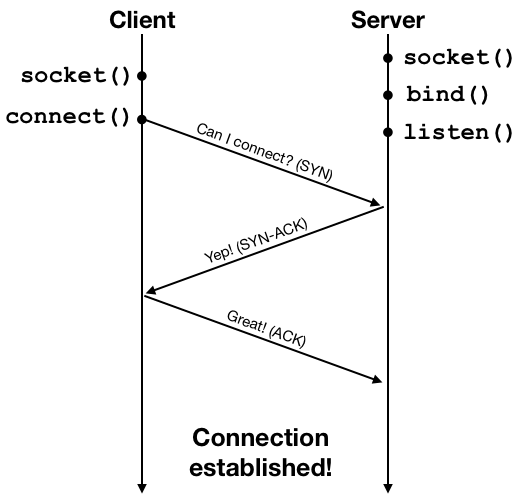
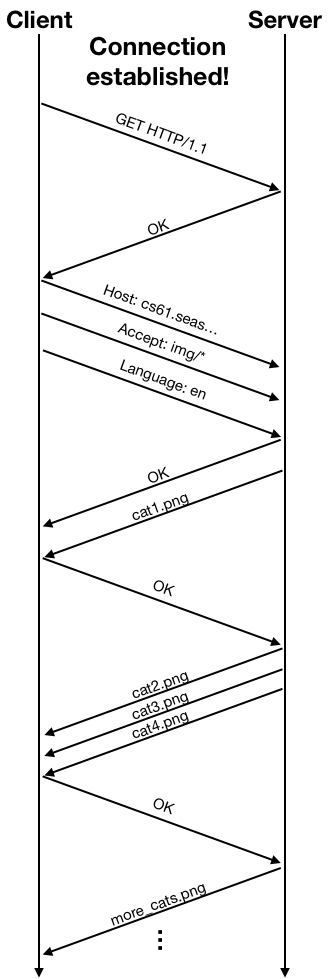
Once the connection is established, the client and the server can exchange data using the connection. The connection provides an abstraction of a reliable data stream, but at a lower level data are still sent in packets. The networking protocol also performs congestion control: the client would send some data, wait for an acknowledgment from the server, and then send more data, and wait for another acknowledgment. The acknowledgment packets are used by the protocol as indicators of the condition of the network. The the network suffers from high packet loss rate or high delay due to heavy traffic, the protocol will lower the rate at which data are sent to alleviate congestion. The following diagram shows an example of the packet exchange between the client and the server using HTTP over an established connection.
WeensyDB
We now look at a simple network database, WeensyDB, to see how networking and synchronization are integrated in the same program. A database is a program that stores data. In our case the WeensyDB application has a server side and a client side. The server side is where data is actually stored, and the client simply queries the database over the network and retrieves data from the server.
Version 1: Single-threaded server
The first version of the server-side database is in synch4/weensydb-01.cc.
We use a simple hash table to represent our database. The hash table has
1024 buckets, and each bucket is a list of elements to handle collisions.
The handle_connection() function performs most of the server-side logic
given a established connection from a client. It reads from the network and
parses the command sent by the client. It then processes the command by
accessing the database (hash table), and then writes the result of the command
back to the network connection so the client can receive it.
We can run this database application by running both the server and the client. Note that merely starting the server does not generate any packets over the network -- it's a purely local operation that simply prepares the listening socket and put it into the appropriate state. After we start the client and type in a command, we do see packets being sent over the network, as a result an active connection being established and data being exchanged.
The example we showed in the lecture had both the client and the server running on the same computer. The packets were exchanged through the local loop-back network interface and nothing gets actually sent over the wire (or WiFi). For understanding you can just imagine that the two programs are running on distinct machines. In fact the two programs do not use anything other than the network to communicate, so it is very much like they operate from different physical machines.
The database server should serve any many clients as possible, without one client being able to interfere with other clients' connections. This is like the process isolation properties provided by the OS kernel. Our first version of WeensyDB doesn't actually provide this property. As we see in its implementation -- it is a single-threaded server. It simply can't handle two client connections concurrently, the clients must wait to be served one by one.
This opens up door for possible attacks. A malicious client who never closes
its connection to the server will block all other clients from making
progress. synch4/wdbclientloop.cc contains such a bad behaving client, and
when we use it with our first version of WeensyDB we observe this effect.
Version 2: Handle connection in a new thread
The next version of the WeensyDB server tries to solve this problem using
multi-threading. The program is in synch4/weensydb-02.cc. It's very
similar to the previous version, except that it handles a client connection
in a new thread. Relevant code is shown below:
int main(int argc, char** argv) {
...
while (true) {
// Accept connection on listening socket
int cfd = accept(fd, nullptr, nullptr);
if (cfd < 0) {
perror("accept");
exit(1);
}
// Handle connection
std::thread t(handle_connection, cfd);
t.detach();
}
}
This code no longer blocks the main thread while a client connection is being handled, so concurrent client connections can proceed in parallel. Great! Does that really work though?
Now look at how we actually handle the client connection, in the while loop
handle_connection() function:
void handle_connection(int cfd) {
...
while (fgets(buf, BUFSIZ, fin)) {
if ... {
...
} else if (sscanf(buf, "set %s %zu ", key, &sz) == 2) {
// find item; insert if missing
auto b = string_hash(key) % NBUCKETS;
auto it = hfind(hash[b], key);
if (it == hash[b].end()) {
it = hash[b].insert(it, hash_item(key));
}
// set value
it->value = std::string(sz, '\0');
fread(it->value.data(), 1, sz, fin);
fprintf(f, "STORED %p\r\n", &*it);
fflush(f);
} else if ...
}
...
}
We see that while handling a set operation, we modify the underlying hash
table, which is shared among all threads created by parallel client
connections. And these modifications are not synchronized at all! Indeed if we
turn on thread sanitizer we see a lot of complaints indicating serious race
conditions in our code when clients issue set commands in parallel.
We have been through this before when dealing with bounded buffers, so we know
we need to fix this using a mutex. But we can't just simply protect the
entire while loop in question using a scoped lock, as we did for the bounded
buffer. If we did that, the program would be properly synchronized, but it
loses parallelism -- the mutex ensures that only one connection can be handled
at a time, and we fall back to the single-threaded version which is subject to
attack by the bad client.
The key to using mutex in a networked program is to realize the danger of holding the mutex while blocking on network system calls. Blocking can happen when sending/receiving data on the network, so during network communications the mutex must never be locked by the server thread.
One way to re-organize the program to avoid these issues is to make sure the
mutex is only locked after a complete request has been received from the
client, and is unlocked before sending the response. In the weensydb-02.cc
code it is equivalent to put one scoped lock within each if/else if/else
block in the while loop in handle_connection().
Version 3: Fine-grained locking
By this point we are still doing coarse-grained locking in that the entire
hash table is protected by one mutex. In a hash table, it's natural to assign
a mutex to each hash table bucket to achieve fine-grained locking, because
different hash table buckets are guaranteed to contain different keys.
synch4/weensydb-05.cc implements this version.
Version 4: Exchange
Now consider we are to add a new feature to the database: an exchange
command that swaps the values of two keys. We still follow the previous fine-
grained locking design, but this time we will need to lock up to 2 buckets for
every operations. When we lock multiple mutexes in a program we should always
be wary of the possibility of deadlocks. We will have more discussions about
deadlocks the next time!