
Blocking pipe
We've mentioned in the previous lecture that I/O operations on pipe file descriptors have blocking semantics when the operation cannot be immediately satisfied. This can occur when the buffer for the pipe is full (when writing), or when there is no data ready to be read from the pipe (when reading). If any of these situations occur, the corresponding I/O operation will block and the current process will be suspended until the I/O operation can be satisfied or encounters an error.
The blocking semantics is useful in that it simplify congestion control within the pipe channel. If two processes at the two ends of the pipe generate and consume data at different rates, the faster process will automatically block (suspend) to wait for the slower process to catch up, and the application does not need to program such waiting explicitly. It provides an illusion of a reliable stream channel between two processes in that no data can ever be lost in the pipe due to a full buffer.
The Linux kernel implements fixed-size buffers for pipes. It is merely an
implementation choice and a different kernel (or even a different flavor of
the Linux kernel) can have different implementations. We can find out the size
of these pipe buffers using the blocking behavior of pipe file descriptors: we
create a new pipe, and simply keep writing to it one byte at a time. Every
time we successfully wrote one byte, we know it has been placed in the buffer
because there is no one reading from this pipe. We print the number of bytes
written so far every time to wrote one byte to the pipe successfully. The
program will eventually stop printing numbers to the screen (because write()
blocks once there is no more space in the buffer), and the last number printed
to the screen should indicate the size of the pipe buffer. The program in
pipesizer.cc does exactly this:
int main() {
int pipefd[2];
int r = pipe(pipefd);
assert(r >= 0);
size_t x = 0;
while (1) {
ssize_t nw = write(pipefd[1], "!", 1);
assert(nw == 1);
++x;
printf("%zu\n", x);
}
}
It will show that in our Ubuntu VM the size of a pipe buffer is 65536 bytes (64 KB).
Sieve of Eratosthenes and pipes
The sieve of Eratosthenes is an ancient algorithm for finding all prime numbers up to an arbitrary limit. The algorithm outputs prime numbers by filtering out, in multiple stages, multiples of known prime numbers. The algorithm works as follows:
- Start with a sequence of integers from 2 up to the given limit;
- Take the first number off sequence and outputs it as a prime p;
- Filter out all multiples of p in the sequence;
- Repeat from step 2 using the filtered sequence;
The following is a demonstration of using the sieve of Eratosthenes to find all prime numbers up to 33:
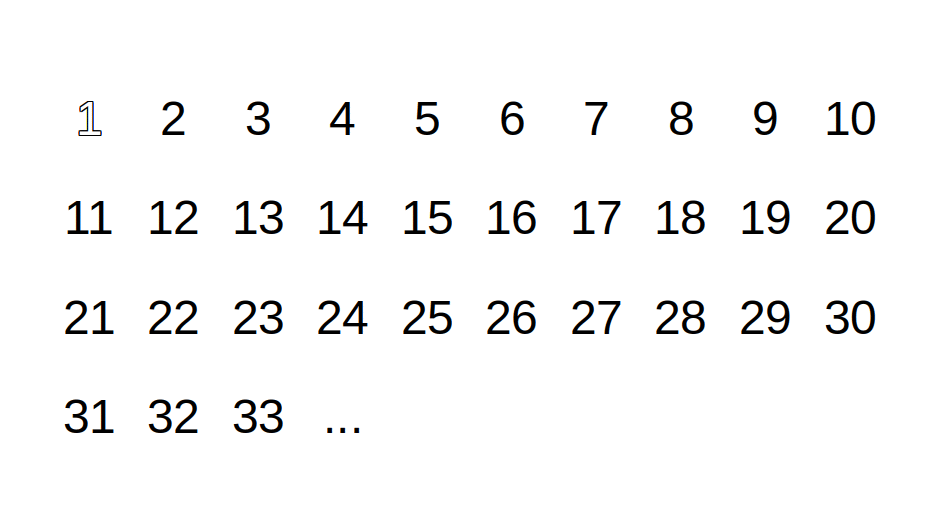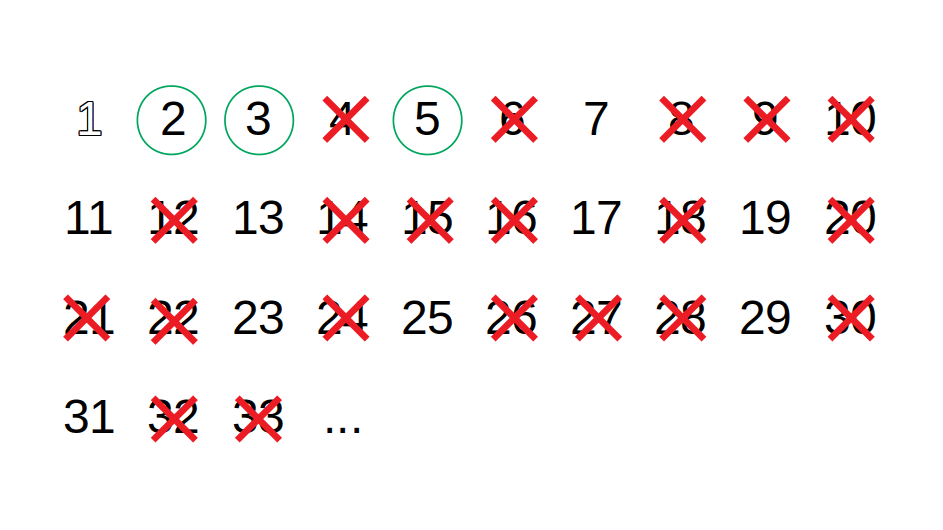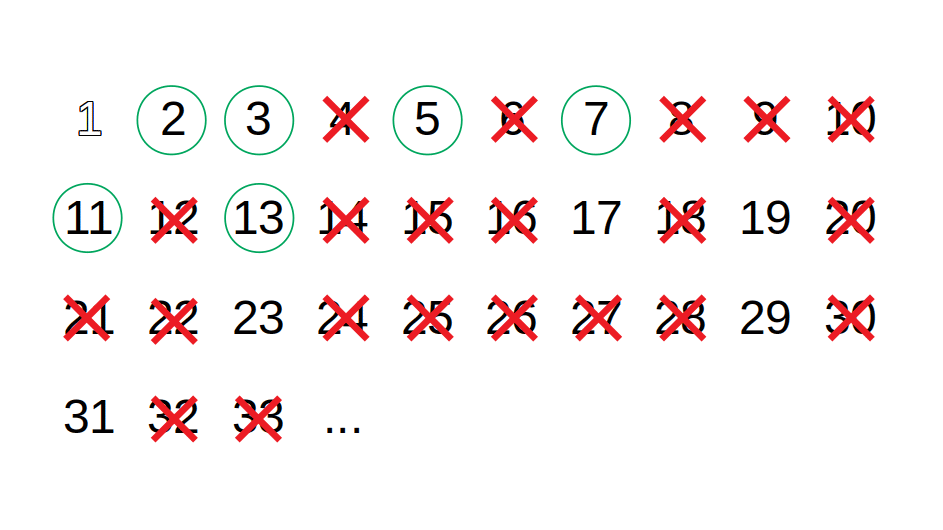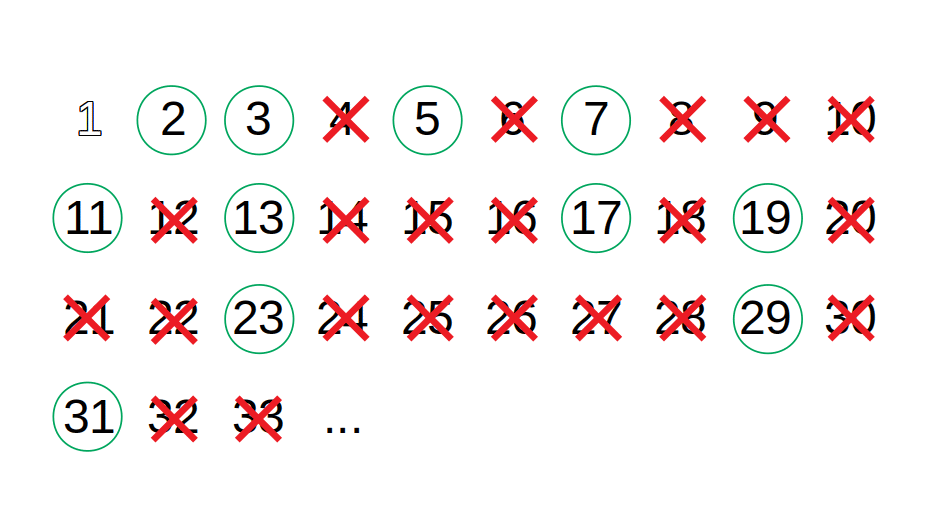
The sieve of Eratosthenes algorithm can be easily translated into a
dynamically extending UNIX pipeline. Every time the algorithm outputs a new
prime number, a new stage is appended to the pipeline to filter out all
multiples of that prime. The following animation illustrates how the pipeline
grows as the algorithm proceeds. Each fm program contained in a pipeline
stage refers to the filtermultiple program, which is a simple program that
reads a sequence of integers from its stdin, , filters out all multiples of
the given argument, and writes the filtered sequence to stdout:

How can we write such a program? The tricky part lies with dynamically extending the pipeline every time a new prime is generated.
Adding a pipeline stage
There are several high-level goals we need to achieve when extending a
pipeline. We would like a filtermultiple program to be running in the added
pipeline stage, and we would like it to be reading from the output from the
previous stage. There also exist a parent process (our primesieve program),
which is the main coordinator program responsible for the creation and
management of all filtermultiple programs in the pipeline. We also need
to pay attention to pipe hygiene, which means by the end of our pipeline
extension all pipes should look clean: each end of any pipe is only associated
with one file descriptor from any process.
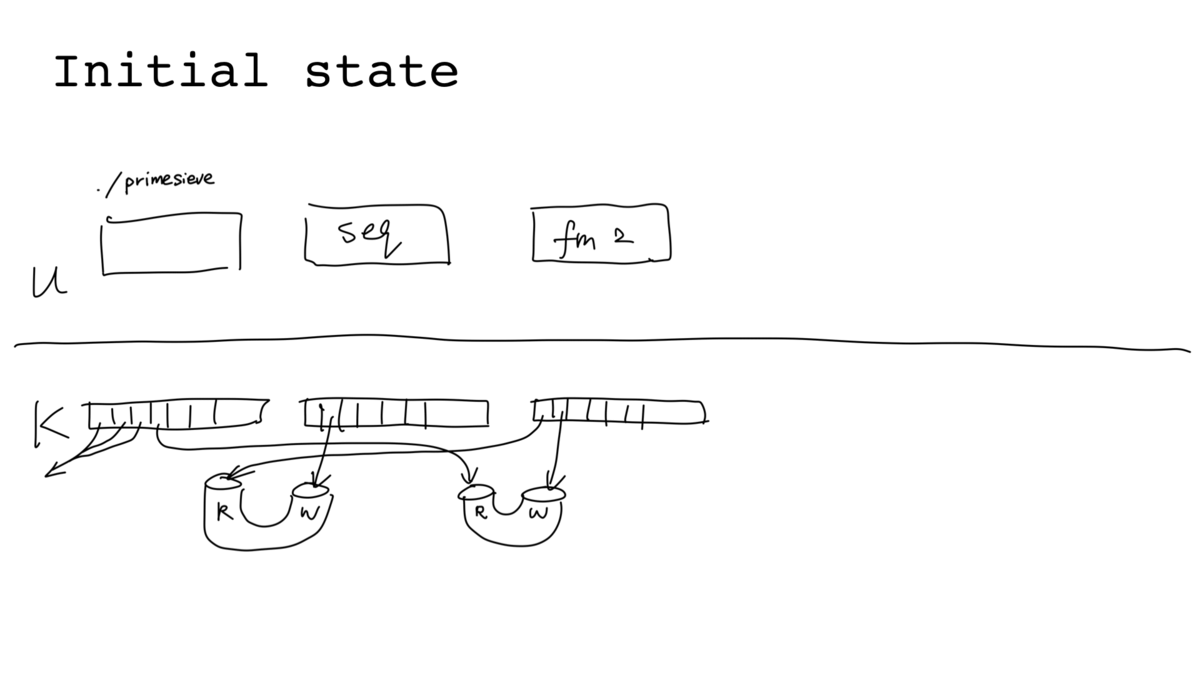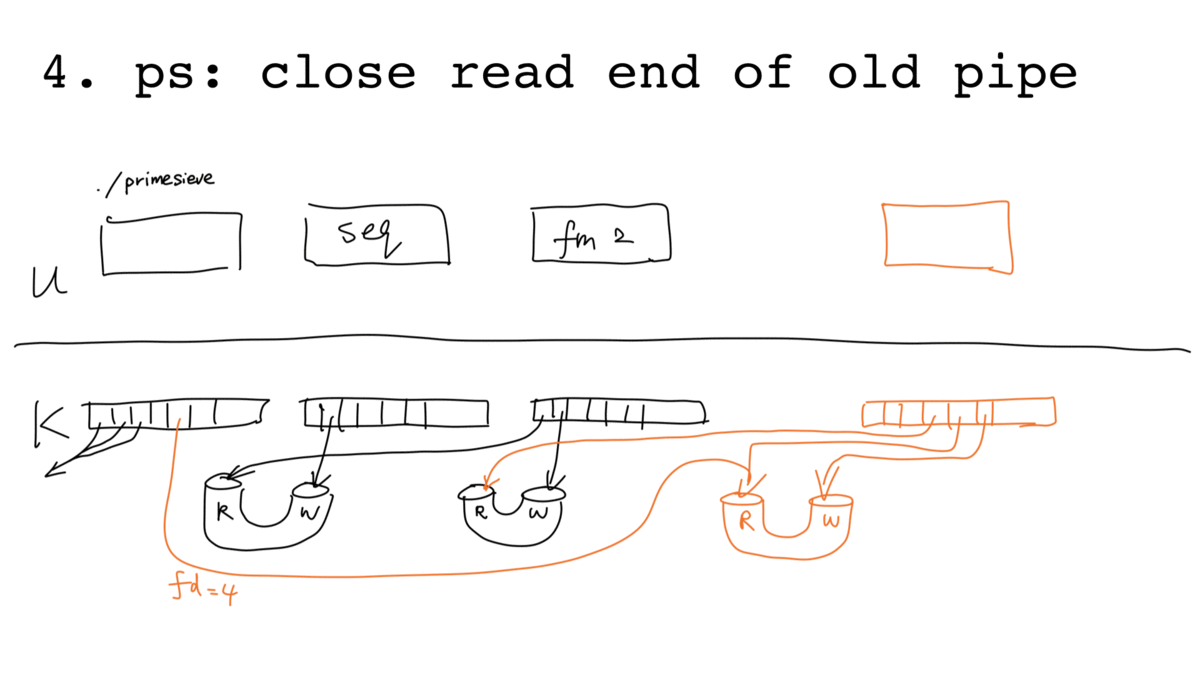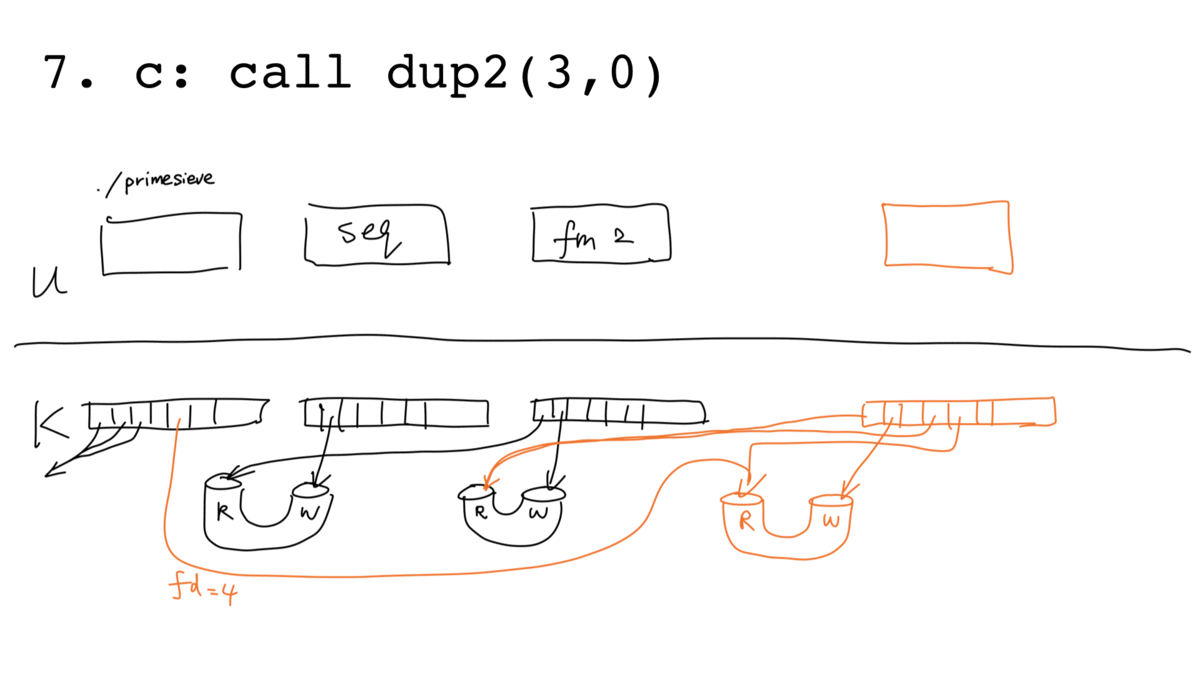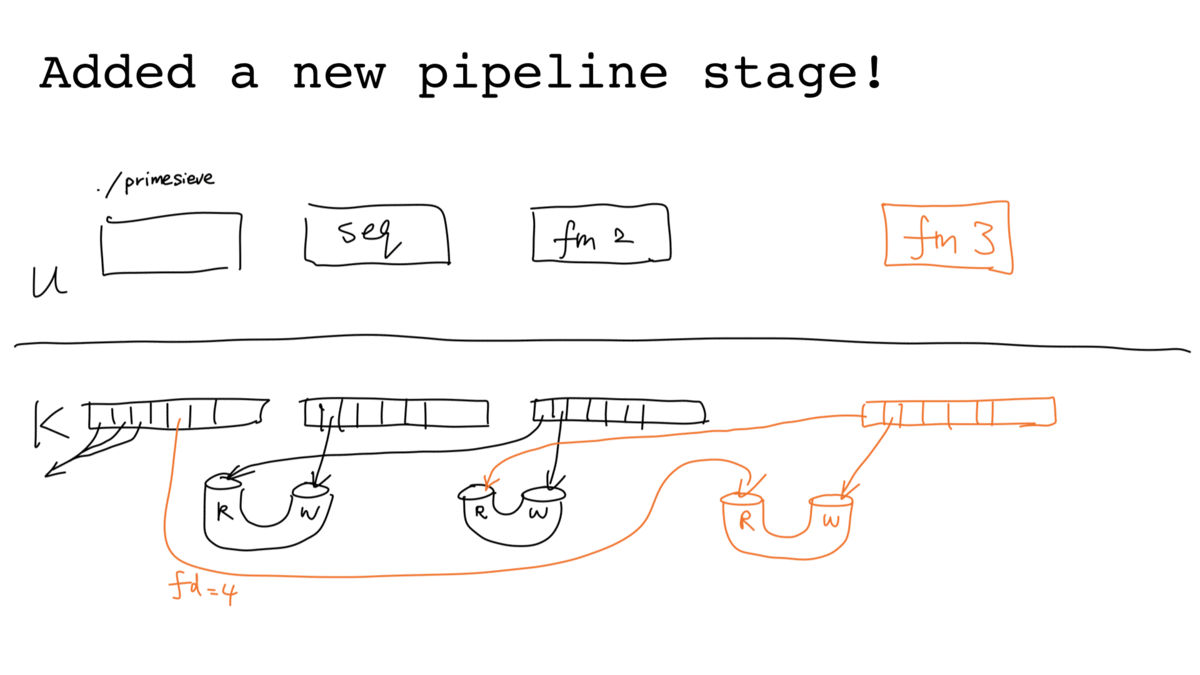
More concretely, adding a pipeline stage involves the following 8 steps ("ps:"
means running as the parent ./primesieve process; "c:" means running as
child process). Assuming at the initial stage the parent reads the first
element of the stream from the read end of a pipe via file descriptor 3:
- ps: call
pipe(), assuming returned file descriptors 4 (read end) and 5 (write end) - ps: call
fork() - ps:
close(5)(write end of the new pipe not used by parent) - ps:
close(3)(read end of the old pipe no longer used by parent) - c: call
dup2(5, 1), redirect stdout to write end of the new pipe - c: call
dup2(3, 0), redirect stdin from read end of the old pipe - c: call
close()on fds 3, 4 ,5 (pipe hygiene) - c: call
execvp(), start running./filtermultiple
The process is illustrated below (with slightly more steps because of the sequence we close "unhygienic" pipe file descriptors):
Synchronization: polling and blocking
Now we transition to the last unit of the course: parallelism and synchronization.
There are 2 ways to "wait for things" in a process: polling and blocking:
- Polling: The process waits for an event while remaining runnable.
- Blocking: The process waits for an event while not runnable.
Polling is sometimes also referred to as non-blocking. Strictly speaking, there is a slight conceptual distinction between the two: non-blocking refers to the property of a single interface call, whereas polling refers to action of repeatedly querying a non-blocking interface until some condition is met.
Consider that we need to wait for the following condition (called timed wait):
Wait for the earliest of:
- Child to exit
- 0.75 seconds to elapse
How can we wait this kind of conditions using a combination of blocking and polling system calls?
Since part of our condition is to wait for the child to exit, maybe
waitpid() jumps to mind. However, the waitpid() described in prior
lectures operates in blocking mode, and there is no way to specify a
0.75-second "timeout" value. So if the child doesn't exit within 0.75 seconds
we miss our condition.
There actually exists a version of the waitpid() system call that operates
in polling mode. We can configure which mode waitpid() should operate in
using the last parameter (called options) of the call:
waitpid(pid, status, 0): blocking modewaitpid(pid, status, WNOHANG): polling (non-blocking) mode- In polling mode,
waitpid()returns 0 immediately if the process has not exited yet.
- In polling mode,
We can implement this compounded waiting using these 2 versions of
waitpid(). The relevant code is in timedwait-poll.cc:
int p1 = ... // p1 is pid of the child
int status;
pid_t exited_pid = 0;
while (tstamp() - start_time < 0.75 && exited_pid == 0) {
exited_pid = waitpid(p1, &status, WNOHANG);
assert(exited_pid == 0 || exited_pid == p1);
}
This is a form of "busy-waiting": the process keeps running and querying about the exit status of the child before the condition is met. This consumes CPU resources and therefore power. Ideally we would like a "waiting" process to be taken off the CPU until the condition it's waiting on becomes satisfied. In order for a process to yield the CPU resources in this way some blocking needs to be introduced. What we also need is to unblock at the right time. If only the blocked process can receive a "signal" when, for example, 0.75 seconds has elapsed or when the child has exited.
Signals
Signals are user-level abstraction of interrupts. A signal has the following effects:
- Interrupts normal process execution.
- Interrupts blocked system calls, making them immediately return -1 with
errnoset toEINTR.
We have in fact all used signals to manage processes before. When we hit
CTRL+C on the keyboard to kill a running program, we are actually telling
the operating system to send a signal (SIGINT in this case) to the program.
The default behavior of the SIGINT signal is to kill the process.
Handling signals
The process can define a signal handler to override the default behavior of
some signals. (This is why CTRL+C doesn't work in some programs as you would
expect. In gdb and many text editors you will see this behavior.)
We use a signal handler to help us with the timed wait task. Let's see the
following code in timedwait-block.cc:
void signal_handler(int signal) {
(void) signal;
}
int main(int, char** argv) {
fprintf(stderr, "Hello from %s parent pid %d\n", argv[0], getpid());
// Demand that SIGCHLD interrupt system calls
int r = set_signal_handler(SIGCHLD, signal_handler);
assert(r >= 0);
// Start a child
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
usleep(500000);
fprintf(stderr, "Goodbye from %s child pid %d\n", argv[0], getpid());
exit(0);
}
double start_time = tstamp();
// Wait for the child and print its status
r = usleep(750000);
if (r == -1 && errno == EINTR) {
fprintf(stderr, "%s parent interrupted by signal after %g sec\n",
argv[0], tstamp() - start_time);
}
...
}
By registering a signal handler, we demand that all outstanding blocked system
calls be interrupted when the parent receives the SIGCHLD signal. The
SIGCHLD signal is delivered to the process when any of its children exits.
The default behavior of SIGCHLD is to ignore the signal, so we need to
explicitly define and register a handler to override the default behavior.
For descriptions and list of all signals supported by the Linux kernel, use manual page
man 7 signal.
The waiting part in the parent now becomes just this, without any polling loop:
// Wait for the child and print its status
r = usleep(750000);
if (r == -1 && errno == EINTR) {
fprintf(stderr, "%s parent interrupted by signal after %g sec\n",
argv[0], tstamp() - start_time);
}
The parent simply goes to sleep for 0.75 seconds. If the child exited before the
0.75-second deadline, the SIGCHLD signal will cause the usleep() system call
to unblock with errno == EINTR. This way the parent does no busy waiting and
will only be blocked for at most 0.75 seconds.
Race conditions in signals
The code above looks correct and behaves as expected in our tests. It is
really correct though? What if we make child exit right away, instead of
waiting for half a second before exiting? If the child exited so fast that the
SIGCHLD signal arrived before the parent even started calling usleep(), the
parent can simply "miss" the signal. In this case the parent would wait for
the full 0.75 seconds even though the child exited immediately (within
milliseconds). This is not what we want!
The program has what we call a race condition. A race condition is a bug that's dependent on scheduling ordering. These bugs are particularly difficult to deal with because they may not manifest themselves unless specific scheduling conditions are met.
Perhaps we can eliminate the race condition by having the signal handler
actually do something. We modify the signal handler to set a flag variable
when a SIGCHLD signal is received. The modified program is in
timedwait-blockvar.cc.
static volatile sig_atomic_t got_signal;
void signal_handler(int signal) {
(void) signal;
got_signal = 1;
}
int main(int, char** argv) {
...
// Wait for the child and print its status
if (!got_signal) {
r = usleep(750000);
}
...
}
We changed the waiting logic in the parent so that it only goes to sleep after making sure that the flag variable is not set (meaning the child has not exited yet). This should solve our problem!
Does it though?
What if the SIGCHLD signal arrives right after we check the flag variable in
the if conditional, but before we invoke the usleep() system call?
Again, there still exists a window, however small it is, for the parent to miss the signal.
We actually already learned the mechanism needed to reliably eliminate this race condition. It's called, wait for it, a pipe. We will show how to use pipes to solve this race condition in the next lecture.