Threads
Modern day computers usually have multiple processors (CPUs) built in. The operating system provides a user-level abstraction of multiple processors call threads. Here is the comparison table of threads (as an abstraction) and multiple processors (as a hardware feature):
| Multiple processors | Threads |
|---|---|
| One primary memory | One virtual address space |
| Multiple sets of registers and logical computations | Multiple sets of registers, stacks, and logical computations |
A process can contain multiple threads. All threads within the same process share the same virtual address space and file descriptor table. Each thread will however have its own set of registers and stack. The processes we have looked at so far all have a single thread running. For multi-threaded processes the kernel will need to store a set of registers for each thread, rather than for each process, to maintain the full process state.
Let's look at how to use threads using our example program in incr-basic.cc:
void threadfunc(unsigned* x) {
// This is a correct way to increment a shared variable!
// ... OR IS IT?!?!?!?!?!?!??!?!
for (int i = 0; i != 10000000; ++i) {
*x += 1;
}
}
int main() {
std::thread th[4];
unsigned n = 0;
for (int i = 0; i != 4; ++i) {
th[i] = std::thread(threadfunc, &n);
}
for (int i = 0; i != 4; ++i) {
th[i].join();
}
printf("%u\n", n);
}
In this code we run the function threadfunc() in parallel in 4 threads. The
std::thread::join() function makes the main thread block until the thread
upon which the join() is called finishes execution. So the final value of
n will be printed by the main thread after all 4 threads finish.
In each thread we increment a shared variable 10 million times. There are 4 threads incrementing in total and the variable starts at zero. What should the final value of the variable be after all incrementing threads finish?
40 million seems like a reasonable answer, but by running the program we observe that sometimes it prints out values like 30 million or 20 million. What's going on?
The compiler can optimize away the loop in threadfunc(). It recognizes that
the loop is simply incrementing the shared variable by an aggregate of 10
million, so it will transform the loop into a single addl instruction with
immediate value 10 million.
Secondly, there is a race condition in the addl instruction itself! Up until
this point in the course, we've been thinking x86 instructions as being
indivisible and atomic. In fact, they are not, and their lack of atomicity
shows up in a multi-processor environment.
Inside the processor hardware, the addl $10000000, (%rdi) is actually
implemented as 3 separate "micro-op" instructions:
movl (%rdi), %temp(load)addl $10000000, %temp(add)movl %temp, (%rdi)(store)
Imagine 2 threads executing this addl instruction at the same time
(concurrently). Each thread loads the same value of (%rdi) from memory, then
adds 10 million to it in their own separate temporary registers, and then
write the same value back to (%rdi) in memory. The last write to memory by
each thread will overwrite each other with the same value, and one increment
by 10 million will essentially be lost.
This is the behavior of running 2 increments on the same variable in x86 assembly. In the C/C++ abstract machine, accessing shared memory from different threads without proper synchronization is undefined behavior, unless all accesses are reads.
Re-running this experiment with compiler optimizations turned off (so the loop does not get optimized away), we will get a result like 15285711, where roughly 2/3 of the updates are lost.
There are 2 ways to synchronize shared memory accesses in C++. We will describe
a low-level approach, using C++'s std::atomic library, first, before
introducing a higher level and more general way of performing synchronization.
Data races
The foundation of correct synchronization is a law we call
The Fundamental Law of Synchronization: If two or more threads concurrently access a non-atomic object in memory, then all such accesses must be reads. Otherwise, the program invokes undefined behavior.
(Atomic objects are defined below.)
For example, our incr-basic.cc function violates the Fundamental Law because
multiple threads concurrently write the n object.
The undefined behavior that occurs when two or more threads have conflicting concurrent accesses to an object is called a data race. Data races are bad news. But note that any number of threads can concurrently read an object; a data race only occurs when at least one of the accesses is a write.
Atomics
incr-atomic.cc implements synchronized shared-memory access, and avoids data
races, using C++ atomics. Relevant code in threadfunc() is shown below.
void threadfunc(std::atomic<unsigned>* x) {
for (int i = 0; i != 10000000; ++i) {
*x += 1; // compiles to atomic “read-modify-write” instruction
// `x->fetch_add(1)` and `(*x)++` also work!
}
}
C++'s atomics library implements atomic additions using an x86's atomic
instruction. When we use objdump to inspect the assembly of threadfunc(),
we see an lock addl ... instruction instead of just addl .... The lock
prefix of the addl instruction asks the processor the hold on to the cache
line with the shared variable (or in Intel terms, lock the memory bus) until
the entire addl instruction has completed.
Because the compiler understands how to implement the atomics library, atomic accesses never cause data races. Specifically, multiple threads can read and write atomic objects concurrently without causing undefined behavior—atomics never violate the Fundamental Law of Synchronization.
Of course, that doesn’t mean that all programs that use atomics are correct.
Consider this threadfunc:
void threadfunc(std::atomic<unsigned>* x) {
for (int i = 0; i != 10000000; ++i) {
unsigned v = *x; // read
v = v + 1; // modify
*x = v; // write
}
}
Because this function separates the read, modify, and write steps into
separate operations, an incr program using the function will almost
certainly produce the wrong answer. Two threads can explicitly read the same
value from *x, which will lose an increment. But there is no undefined
behavior!
Synchronization objects
C++ atomics and lock-prefixed instructions only work with aligned
objects with sizes of one word (8 bytes) or less. This is great, but
limited. To synchronize more complex objects in memory or perform more
complex synchronization tasks, we need abstractions.
Synchronization objects are types whose methods can be used to achieve
synchronization and atomicity on normal (non-std::atomic-wrapped) objects.
Synchronization objects provides various abstract properties that simplify
programming multi-threaded access to shared data. The most common
synchronization object is called a mutex, which provides the mutual
exclusion property.
Mutual exclusion
Mutual exclusion means that at most one thread accesses shared data at a time.
Our multi-threaded incr-poll.cc example does not work because more
than one thread can access the shared variable at a time. The code
would behave correctly if the mutual exclusion policy is enforced. We
can use a mutex object to enforce mutual exclusion
(incr-mutex.cc). In this example it has the same effect as wrapping
*x in a std::atomic template:
std::mutex mutex;
void threadfunc(unsigned* x) {
for (int i = 0; i != 10000000; ++i) {
mutex.lock();
++*x;
mutex.unlock();
}
}
The mutex has an internal state (denoted by state), which can be either
locked or unlocked. The semantics of a mutex object is as follows:
- Upon initialization,
state = unlocked. mutex::lock()method: waits untilstatebecomesunlocked, and then atomically setsstate = locked. Note the two steps shall complete in one atomic operation.mutex::unlock()method: asserts thatstate == locked, then setsstate = unlocked.
The mutual exclusion policy is enforced in the code region between the
lock() and unlock() invocations. We call this region the critical
region.
Implementing a mutex
Let's now think about how we may implement such a mutex object.
Does the following work?
struct mutex {
static constexpr int unlocked = 0;
static constexpr int locked = 1;
int state = unlocked;
void lock() {
while (state == locked) {
}
state = locked;
}
void unlock() {
state = unlocked;
}
};
No! Imagine that two threads calls lock() on an unlocked mutex at the same
time. They both observe that state == unlocked, skip the while loop, and set state = locked, and then return. Now both threads think they have the lock and proceeds
to the critical region, all at the same time! Not Good!
In order to properly implement a mutex we need atomic read-modify-write
operation. std::atomic provides these operations in the form of
operator++and operator-- operators. The following mutex implementation
should be correct:
struct mutex {
std::atomic<int> state = 0;
void lock() {
while (++state != 1) {
--state;
}
}
unlock() {
--state;
}
};
Note that the unlock() method performs an atomic decrement operation,
instead of simply writing 0. Simply storing 0 to the mutex state is incorrect
because of if this store occurred between the ++state and --state steps in
the while loop in the lock() method, state becomes negative and the
while loop can never exit.
Implementing a mutex with a single bit
Last time we showed that we can implement a busy-waiting mutex using an atomic counter. But a mutex can also be implemented using just a single bit, with some special atomic machine instructions!
First, consider this busy-waiting mutex (also called a spin lock):
struct mutex {
std::atomic<int> spinlock = 0;
void lock() {
while (spinlock.swap(1) == 1) {
}
}
void unlock() {
spinlock.store(0);
}
};
The spinlock.swap() method is an atomic swap method, which in one atomic
step stores the specified value to the atomic spinlock variable and returns
the old value of the variable.
It works because lock() will not return unless spinlock previously
contains value 0 (which means unlocked). In that case it will atomically
stores value 1 (which means locked) to spinlock; this prevents other
lock() calls from returning, ensuring mutual exclusion. While lock()
spin-waits, it simply swaps spinlock's old value 1 with 1, effectively
leaving the lock untouched. Please take a moment to appreciate how this simple
construct correctly implements mutual exclusion.
x86-64 provides this atomic swap functionality via the lock xchg assembly
instruction. We have shown that it is all we need to implement a mutex with
just one bit. x86-64 provides a more powerful atomic instruction that further
opens the possibility of what can be done atomically in modern processors.
The instruction is called a compare-exchange, or lock cmpxchg. It is
powerful enough to implement atomic swap, add, subtract, multiplication,
square root, and many other things you can think of.
The behavior of the instruction is defined as follows:
// Everything in one atomic step
int compare_exchange(int* object, int expected, int desired) {
if (*object == expected) {
*object = desired;
return expected;
} else {
return *object;
}
}
This instruction is also accessible as the this->compare_exchange_strong() member
method for C++ std::atomic type objects. Instead of returning an old value, it
returns a boolean indicating whether the exchange was successful.
For example, we can use the compare-exchange instruction to atomically add 7 to any integer:
void add7(int* x) {
int expected = *x;
while (compare_exchange(x, expected, expected + 7)
!= expected) {
expected = *x;
}
}
Bounded buffers
With the help of mutex, we can build objects that support synchronized accesses with more complex semantics.
A bounded buffer is an object often used to implement a cache. The pipe buffer used by the kernel to implement the pipe abstraction is an example of a bounded buffer. In this unit, we’re going to build a synchronized bounded buffer.
A bounded buffer is a circular buffer that can hold up to CAP characters,
where CAP is the capacity of the buffer. The bounded buffer supports the
following operations:
-
read(buf, sz):- Reads up to
szcharacters from the bounded buffer intobuf - Removes characters read from the bounded buffer
- If the bounded buffer is initially empty,
readshould block until the buffer becomes nonempty or is closed - Returns the number of characters read
- Reads up to
-
write(buf, sz):- Writes up to
szcharacters, frombufto the end of bounded buffer - Writes up to bounded buffer capacity
CAPcharacters - If bounded buffer is initially full,
writeshould block until buffer becomes nonfull or the read end is closed - Returns the number of characters written
- Writes up to
Example: Assuming we have a bounded buffer object bbuf with CAP=4.
bbuf.write("ABCDE", 5); // returns 4
bbuf.read(buf, 3); // returns 3 ("ABC")
bbuf.read(buf, 3); // returns 1 ("D")
bbuf.read(buf, 3); // blocks
The bounded buffer preserves two important properties:
- Every character written can be read exactly once;
- The order in which characters are read is the same order in which they are written.
Each bounded buffer operation should also be atomic, just like read() and
write() system calls.
Unsynchronized bounded buffer
Let's first look at a bounded buffer implementation bbuffer-basic.cc, which does
not perform any synchronization.
struct bbuffer {
static constexpr size_t bcapacity = 128;
char bbuf_[bcapacity];
size_t bpos_ = 0;
size_t blen_ = 0;
bool write_closed_ = false;
ssize_t read(char* buf, size_t sz);
ssize_t write(const char* buf, size_t sz);
void shutdown_write();
};
ssize_t bbuffer::write(const char* buf, size_t sz) {
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
size_t bspace = std::min(bcapacity - bindex, bcapacity - this->blen_);
size_t n = std::min(sz - pos, bspace);
memcpy(&this->bbuf_[bindex], &buf[pos], n);
this->blen_ += n;
pos += n;
}
if (pos == 0 && sz > 0) {
return -1; // try again
} else {
return pos;
}
}
ssize_t bbuffer::read(char* buf, size_t sz) {
size_t pos = 0;
while (pos < sz && this->blen_ > 0) {
size_t bspace = std::min(this->blen_, bcapacity - this->bpos_);
size_t n = std::min(sz - pos, bspace);
memcpy(&buf[pos], &this->bbuf_[this->bpos_], n);
this->bpos_ = (this->bpos_ + n) % bcapacity;
this->blen_ -= n;
pos += n;
}
if (pos == 0 && sz > 0 && !this->write_closed_) {
return -1; // try again
} else {
return pos;
}
}
It implements what we call circular buffer. Every time we read a character
out of the buffer, we increment bpos_, which is the index of the next
character to be read in the buffer. Whenever we write to the buffer, we
increment blen_, which is the number of bytes currently occupied in the
buffer. The buffer is circular, which is why all index arithmetic is modulo
the total capacity of the buffer.
When there is just one thread accessing the buffer, it works perfectly fine.
But does it work when multiple threads are using the buffer at the same time?
In our test program in bbuffer-basic.cc, we have one reader thread reading
from the buffer and a second writer thread writing to the buffer. We would
expect everything written to the buffer by the writer thread to show up
exactly as it was written once read out by the reader thread.
It does not work, because there is no synchronization over the internal state
of the bounded buffer. bbuffer::read() and bbuffer::write() both modify
internal state of the bbuffer object (most critically bpos_ and blen_),
and such accesses require synchronization to work correctly in a multi-
threaded environment.
Bounded buffer with mutual exclusion
Looking at the definition of the bounded buffer:
struct bbuffer {
static constexpr size_t bcapacity = 128;
char bbuf_[bcapacity];
size_t bpos_ = 0;
size_t blen_ = 0;
bool write_closed_ = false;
...
};
The bounded buffer's internal state, bbuf_, bpos_, blen_, and
write_closed_, are both modified and read by read() and write() methods.
Local variables defined within these methods are not shared. So we need to
carry out synchronization on shared variables (internal state of the buffer),
but not on local variables.
Mutex synchronization
We can make the bounded buffer synchronized by using std::mutex objects.
We can associate a mutex with the internal state of the buffer, and only
access these internal state when the mutex is locked.
The bounded_buffer::write() method in bbuffer-mutex.cc is implemented
with mutex synchronization. Note that we added a definition of a mutex to the
bbuffer struct definition, and we are only accessing the internal state of the
buffer within the region between this->mutex_.lock() and this->mutex_.unlock(),
which the the time period when the thread locks the mutex.
The association between the mutex and the state it protects can seem rather arbitrary, and is generally not indicated except through comments. This is because the association between a mutex and the state protected by that mutex is not enforced in any way by the runtime system, and must be taken care of by the programmer. The effectiveness of mutexes depends on the program following protocols associating the mutex with the protected state. In other words, if a mutex is not used correctly, there is no guarantee that the underlying state is being properly protected.
struct bbuffer {
...
std::mutex mutex_;
...
};
ssize_t bbuffer::write(const char* buf, size_t sz) {
this->mutex_.lock();
...
this->mutex_.unlock();
if (pos == 0 && sz > 0) {
return -1; // try again
} else {
return pos;
}
}
ssize_t bbuffer::read(char* buf, size_t sz) {
this->mutex_.lock();
...
if (pos == 0 && sz > 0 && !this->write_closed_) {
pos = -1; // try again
}
this->mutex_.unlock();
return pos;
}
All accesses to shared state are contained between calls to mutex::lock and
mutex::unlock. Thus, all accesses to shared state are correctly synchronized.
Simply wrapping accesses to shared state within critical sections using a mutex is the easiest and probably also the most common way to synchronize complex in-memory objects. Using one mutex for the entire object is called coarse-grained synchronization. It is correct, but it also limits concurrency. Under this scheme, whenever there is a writer writing to the buffer, the reader can't acquire the lock and will have to wait until the writer finishes. The reader and the writer can never truly read and write to the buffer at the same time.
Mutex pitfalls
Now consider the following code, which move the mutex lock()/unlock() pair
to inside the while loop. We still have just one lock() and one unlock()
in our code. Is it correct?
ssize_t bbuffer::write(const char* buf, size_t sz) {
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
this->mutex_.lock();
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
this->mutex_.unlock();
}
...
}
The code is incorrect because this->blen_ is not protected by the mutex, but it should be.
What about the following code -- is it correct?
ssize_t bbuffer::write(const char* buf, size_t sz) {
this->mutex_.lock();
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
this->mutex_.lock();
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
this->mutex_.unlock();
}
...
}
It's also wrong! Upon entering the while loop for the first time, the mutex
is already locked, and we are trying to lock it again. Trying to lock a mutex
multiple times in the same thread causes the second lock attempt to block
indefinitely.
So what if we do this:
ssize_t bbuffer::write(const char* buf, size_t sz) {
this->mutex_.lock();
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
this->mutex_.unlock();
this->mutex_.lock();
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
this->mutex_.unlock();
this->mutex_.lock();
}
...
}
Now everything is protected, right? NO! This is also incorrect and in many ways much worse than the two previous cases.
Although this->blen_ is now seemingly protected by the mutex, it is being
protected within a different region from the region where the rest of the
buffer state (bbuf_, bpos_) is protected. Further more, the mutex
is unlocked at the end of every iteration of the while loop. This means
that when two threads call the write() method concurrently, the lock can
bounce between the two threads and the characters written by the threads
can be interleaved, violating the atomicity requirement of the write()
method.
C++ mutex patterns
We may find it very common that we write some synchronized function where we need to lock the mutex first, and then unlock it before the function returns. Doing this repeatedly can be tedious. Also, if the function can return at multiple points, it is possible to forget a unlock statement before a return, resulting in errors. C++ has a pattern to help us deal with these problems and simplify programming: a scoped lock.
We use scoped locks to simplify programming of the bounded buffer in
bbuffer-scoped.cc. The write() method now looks like the following:
ssize_t bbuffer::write(const char* buf, size_t sz) {
std::unique_lock<std::mutex> guard(this->mutex_);
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
}
...
}
Note that in the first line of the function body we declared a
std::unique_lock object, which is a scoped lock that locks the mutex for the
scope of the function. Upon initialization of the std::unique_lock object,
the mutex is automatically locked, and when this object goes out of scope, the
mutex is automatically unlocked. These special scoped lock objects lock and
unlock mutexes in their constructors and destructors to achieve this effect.
This design pattern is also called Resource Acquisition is Initialization
(or RAII), and is a common pattern in C++ software engineering in general. The use
of RAII simplify coding and also avoids certain programming errors.
You should try to leverage these scoped lock objects for your synchronization tasks in the problem set as well.
Condition variables
So far we implemented everything in the spec of the bounded buffer except
blocking. It turns out mutex alone is not enough to implement this feature:
we need another synchronization object. In standard C++ this object is called
a condition variable, std::condition_variable_any.
A condition variable supports the following operations:
cv.wait(lock):lockmust be a mutex-like type, such asstd::mutexorstd::unique_lock. In one atomic step, this function unlocks the lock vialock.unlock()and blocks the calling thread. The thread will remain blocked until another thread callsnotify_all(). When the thread resumes, it will re-lock the lock vialock.lock().cv.notify_all(): Wakes up all threads blocked incv.wait(...).
Condition variables are designed to avoid the sleep-wakeup race conditions we
briefly visited when we discussed signal handlers. The atomicity of the
unlocking and the blocking guarantees that a thread that blocks can't miss
a notify_all() message.
Logically, the writer to the bounded buffer should block when the buffer
becomes full, and should unblock when the buffer becomes nonfull again. Let's
create a condition variable, called nonfull_, in the bounded buffer, just
under the mutex. Note that we conveniently named the condition variable after
the condition under which the function should unblock. It will make code
easier to read later on. The write() method implements blocking is in
bbuffer-cond.cc. It looks like the following:
ssize_t bbuffer::write(const char* buf, size_t sz) {
std::unique_lock<std::mutex> guard(this->mutex_);
assert(!this->write_closed_);
while (this->blen_ == bcapacity) { // #1
this->nonfull_.wait(guard);
}
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
}
...
The new code at #1 implements blocking until the condition is met. This is a
pattern when using condition variables: the condition variable's wait()
function is almost always called in a while loop, and the loop tests the
condition in which the function must block.
On the other hand, notify_all() should be called whenever some changes we
made might turn the unblocking condition true. In our scenario, this means we
must call notify_all() in the read() method, which takes characters out of
the buffer and can potentially unblock the writer, as shown in the inserted
code #2 below:
ssize_t bbuffer::read(char* buf, size_t sz) {
std::unique_lock<std::mutex> guard(this->mutex_);
...
while (pos < sz && this->blen_ > 0) {
buf[pos] = this->bbuf_[this->bpos_];
this->bpos_ = (this->bpos_ + 1) % bcapacity;
--this->blen_;
++pos;
}
if (pos > 0) { // #2
this->nonfull_.notify_all();
}
Note that we only put notify_all() in a if but put the wait() inside
a while loop. Why is it necessary to have wait() in a while loop?
wait() is almost always used in a loop because of what we call spurious
wakeups. Since notify_all() wakes up all threads blocking on a certain
wait() call, by the time when a particular blocking thread locks the mutex
and gets to run, it's possible that some other blocking thread has already
unblocked, made some progress, and changed the unblocking condition back to
false. For this reason, a woken-up thread must revalidate the unblocking condition
before proceeding further, and if the unblocking condition is not met it must
go back to blocking. The while loop achieves exactly this.
C++ note. C++ has two condition variable implementations,
std::condition_variable_anyandstd::condition_variable. Despite the longer name, we recommend usingstd::condition_variable_any.std::condition_variableonly works withstd::unique_lock, and it requires that all threads waiting on a condition variable use the same mutex. This code, which uses one condition variable with two different mutexes, causes undefined behavior ift1andt2run at the same time:std::mutex m1, m2; std::condition_variable cv; // not recommended — prefer std::condition_variable_any void t1() { std::unique_lock lock(m1); cv.wait(lock); } void t2() { std::unique_lock lock(m2); // different mutex cv.wait(lock); // + same CV = undefined behavior! }
std::condition_variable_anybehaves fine in this case.
Deadlock
Deadlock is a situation in a multi-threaded process where each thread is waiting (forever) for a resource that is held by another thread.
It is necessary to have a cycle in a resource ownership-wait diagram to have a deadlock. The following diagram illustrates a deadlock where two threads are waiting for some resources held by each other and are therefore unable to ever make progress.
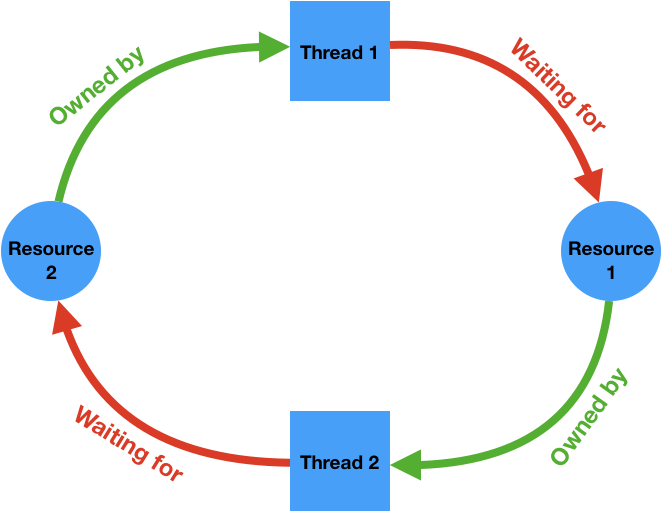
Cycles like this can potentially be detected by the runtime system and it can intervene to break the deadlock, for example by forcing one of the threads to release the resources it owns. The C++ runtime does not perform these checks for performance reasons, therefore it's the programmer's responsibility to make sure the program is free of deadlocks.
There are many ways to lead to a deadlock, even with just a single mutex and a single thread. Consider the following code:
std::mutex m;
void f() {
std::scoped_lock guard(m);
g();
}
void g() {
std::scoped_lock guard(m);
// Do something else
}
This code will not make any progress because the lock acquisition
scoped_lock in g() is waiting for the scoped_lock in f() to go out of
scope, which it never will.
Also, the resources that are involved in a ownership-wait cycle don't have to be mutexes. Recall the extra credit in the stdio problem set (problem set 4). The two resources are two pipe buffers. Let's say the two processes are following the procedure below:
Process 1:
writes 3 requests to the pipe, 33000 bytes each
reads 3 responses from the pipe, 66000 bytes each
Process 2:
while (true) {
reads a request from the pipe
writes a response to the pipe
}
Process 1 should successfully write two requests to the pipe, as Process 2 consumes one request so there is space in the pipe to hold the second request. The third request write will however be blocked because there is not enough space in the pipe buffer (assuming pipe buffers are 65536 bytes). Process 2 can not consume another request because it is also blocked while writing the large response for the first request, which does not fit in the pipe buffer. A cycle occurs and no process can make progress.