This section introduces you to the notion of access pattern and a classification of different access patterns. It ends by walking through code for a single-slot cache—code that can be the foundation of your problem set.
Blocks, slots, and addresses
A cache is a small amount of fast storage that helps speed up access to slower underlying storage. The underlying storage often has more capacity than the cache, meaning that it holds more data. When discussing caches in general, we use these terms:
-
A block is a unit of data storage. Both the underlying storage and the cache are divided into blocks. In some caches, blocks have fixed size; in others, blocks have variable size. Some underlying storage has a natural block size, but in general, the block size is determined by the cache in question.
-
Each block of underlying storage has an address. We represent addresses abstractly as integers, though in a specific cache, an address might be a memory address, an offset into a file, a disk position, or even a web page’s URL.
-
Each block in the cache is a slot. A slot can either be empty or full. An empty slot has no data, while a full slot contains a cached version of a specific block of underlying storage. A full slot therefore has an associated address, which is the address of that block on underlying storage.
Note that the notion of address corresponds to the unit of access to underlying storage, which might differ from the accesses performed by software. For example, a processor cache for primary memory accesses primary memory in units of cache lines, which are aligned contiguous blocks of 64 or 128 bytes.
EXERCISE. When considering x86-64 general-purpose registers as a cache for words of primary memory (via processor caches), roughly how many slots are there in the cache, how big is a block, and what do cache addresses represent?
EXERCISE. When considering an x86-64 core’s level-1 processor cache as a cache for lines of primary memory, roughly how many slots are there in a cache, and what do cache addresses represent? You may assume a block (a cache line) is 64 aligned contiguous bytes of memory.
Access patterns
The sequence of addresses accessed in slower storage has enormous impact on cache effectiveness. For instance, repeated reads to the same address (temporal locality of reference) are easy to cache. On the first access, the system must fetch a block from underlying storage into a cache slot, but all future accesses can use the cache. On the other hand, a truly random access sequence is very hard to cache when the underlying storage has large capacity: in expectation, every read will require fetching a block.
We can semi-formalize these issues into concepts called reference strings and access patterns.
A reference string is an ordered sequence of addresses representing access requests. For instance, the reference string 0R, 1R, 2R, 3R represents a sequence of four read requests for blocks—first for block 0, then blocks 1, 2, and 3. The operation (R or W) is often omitted.
An access pattern is a description of a class of reference string. It’s important to know at least these:
-
Repeated access pattern: The same address over and over, as in 1, 1, 1, 1, 1, ….
-
Sequential access pattern: A contiguous increasing sequence of addresses, as in 1, 2, 3, 4, 5, 6… or 1009, 1010, 1011, 1012, 1013…, with few or no skipped or repeated addresses.
-
Reverse-sequential access pattern: A contiguous decreasing sequence of addresses, as in 60274, 60273, 60272, 60271, 60270, ….
-
Strided access pattern: A monotonically increasing or decreasing sequence of addresses with uniform distance, as in 0, 4096, 8192, 12288, 16384, …. The distance between adjacent addresses is called the stride.
Sequential and reverse-sequential access are kinds of strided access with stride +1 and −1, respectively, but they are important enough to be assigned their own names. We are more likely to describe an access pattern as strided if it has a large stride.
-
Random access pattern: An apparently-unpredictable sequence of addresses spread over some range.
Real reference strings often contain multiple patterns as subsequences. For example, the reference string 0, 1, 2, 3, …, 39998, 39999, 40000, 100000, 99999, 99998, 99997, … 1 consists of sequential access (0–40000) followed by reverse-sequential access (100000–1).
EXERCISE. Sketch an access pattern that contains three distinct subsequences of sequential access.
EXERCISE. Describe a scenario where random access might not be difficult to cache.
File positions
We now turn from abstract descriptions of reference strings and caches to specific reference strings, as found in file I/O, and a specific type of cache, a standard I/O cache.
Standard I/O caches are intended to speed up access to data read and written
from file descriptors, which are the Unix representation of data
streams and random-access files. System calls like read and
write perform the reading and writing. Standard I/O caches can
improve performance by reducing the number of system calls performed.
Besides transferring data from or to a file, read and write also affect
the file descriptor’s file position. This is a numeric byte offset
representing the current position in the file.1 A read system call starts
reading at the current file position and advances the file position by the
number of characters read (and similarly for write). This means that
successive calls to read progress sequentially through the file, as you can
see in the following example.
-
Right before executing
read(fd, buf, 1)on a just-opened file (the file position is shown in red):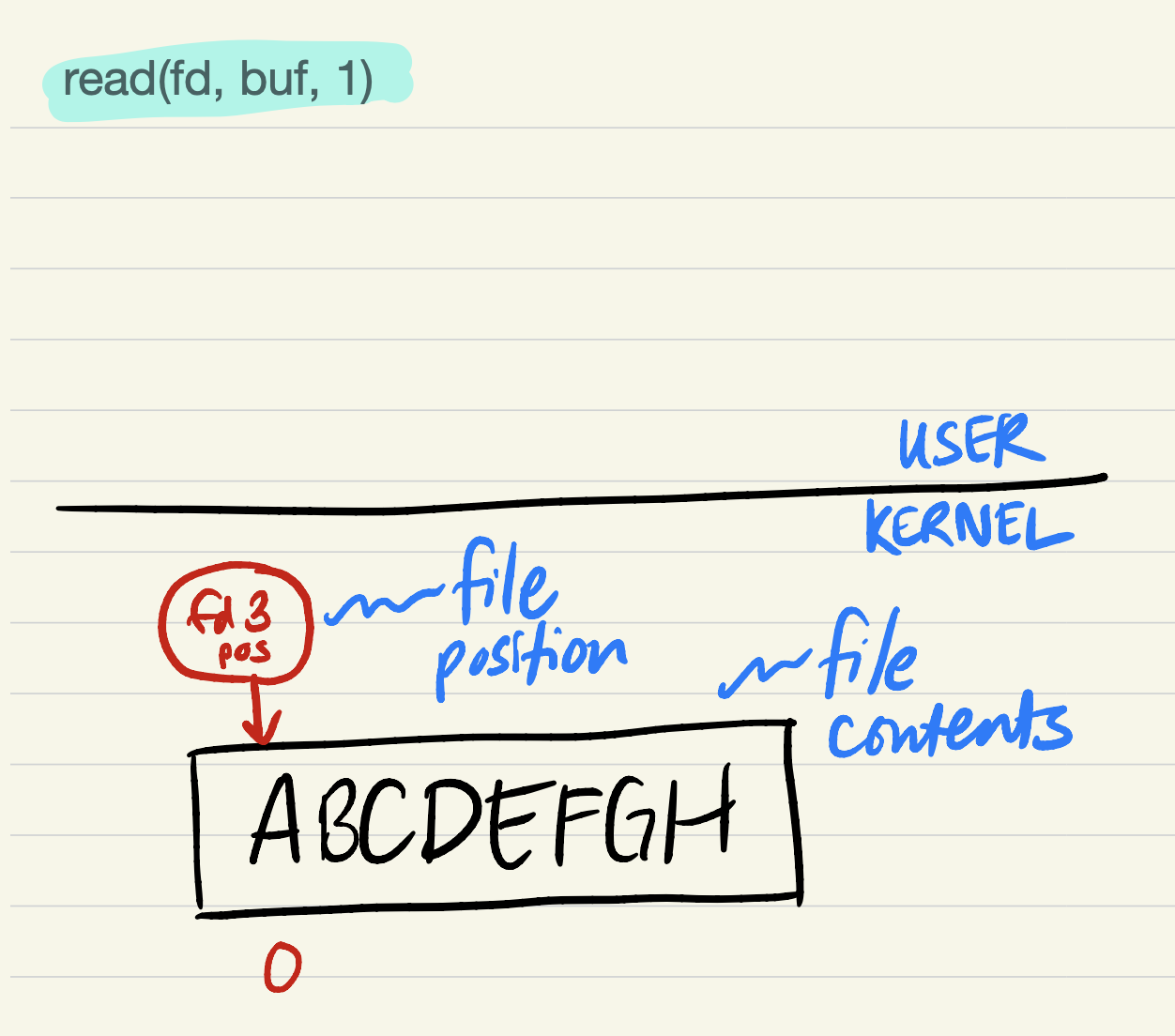
-
After
read(fd, buf, 1):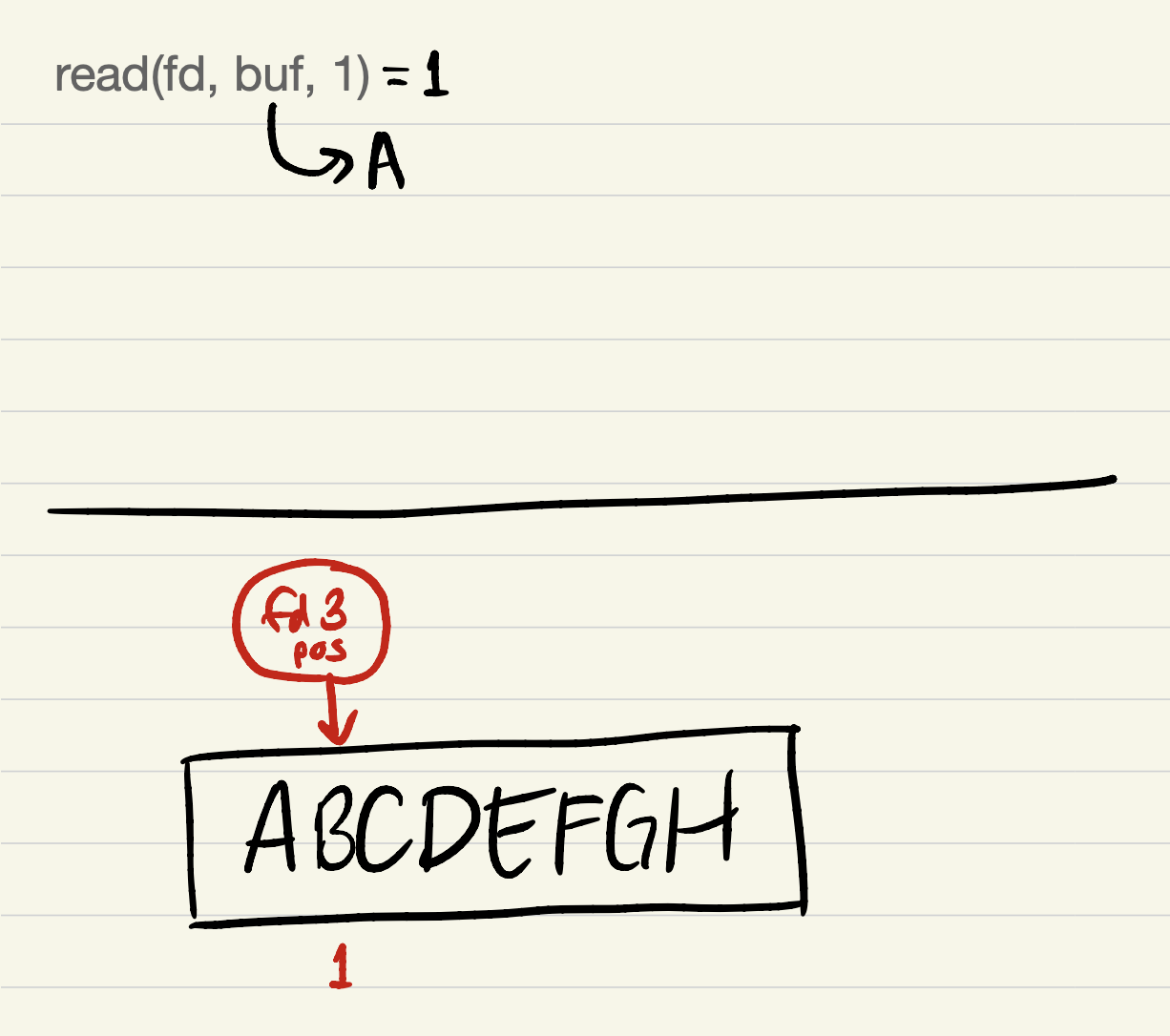
-
After
read(fd, buf, 2):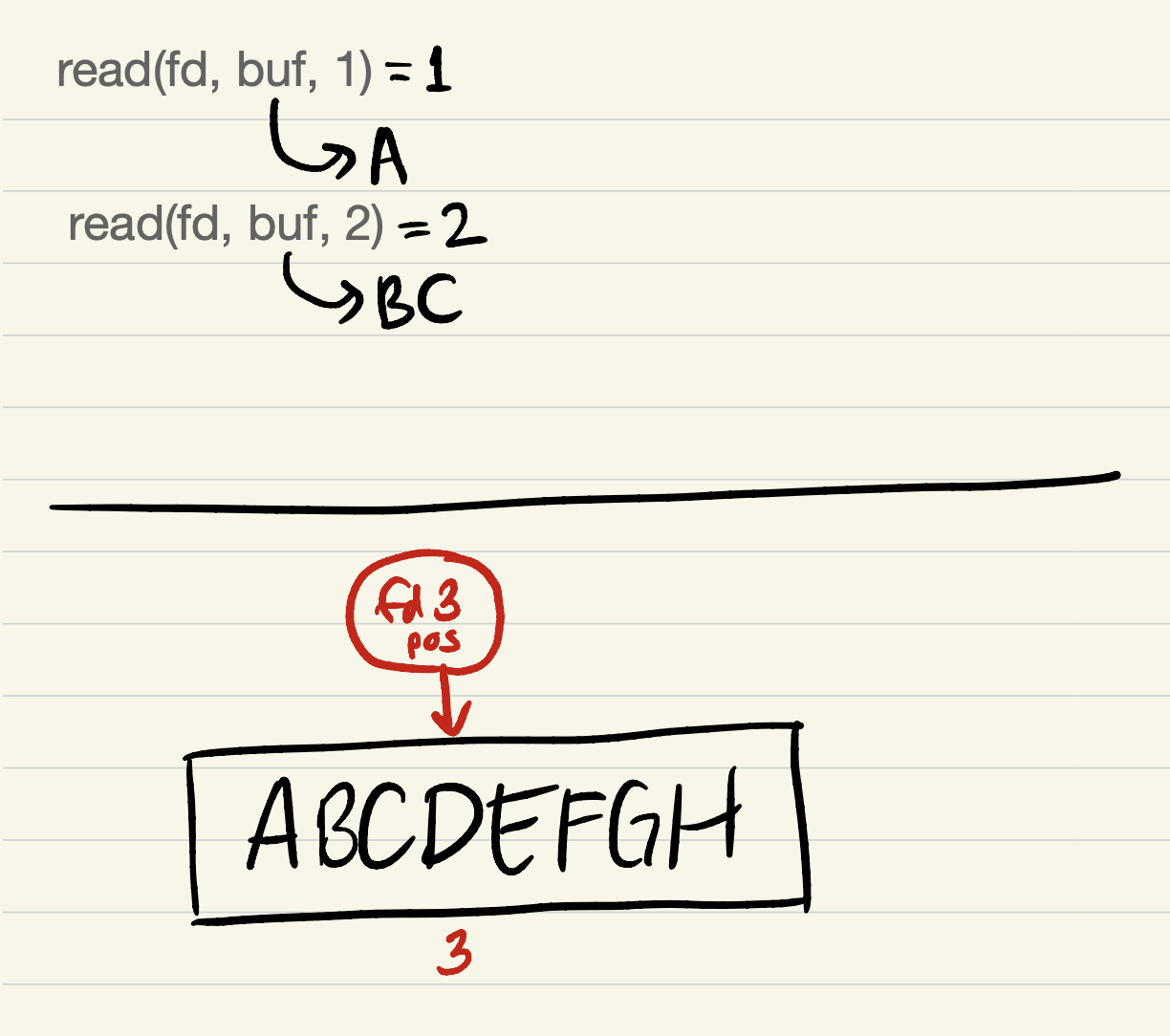
-
After
read(fd, buf, 3):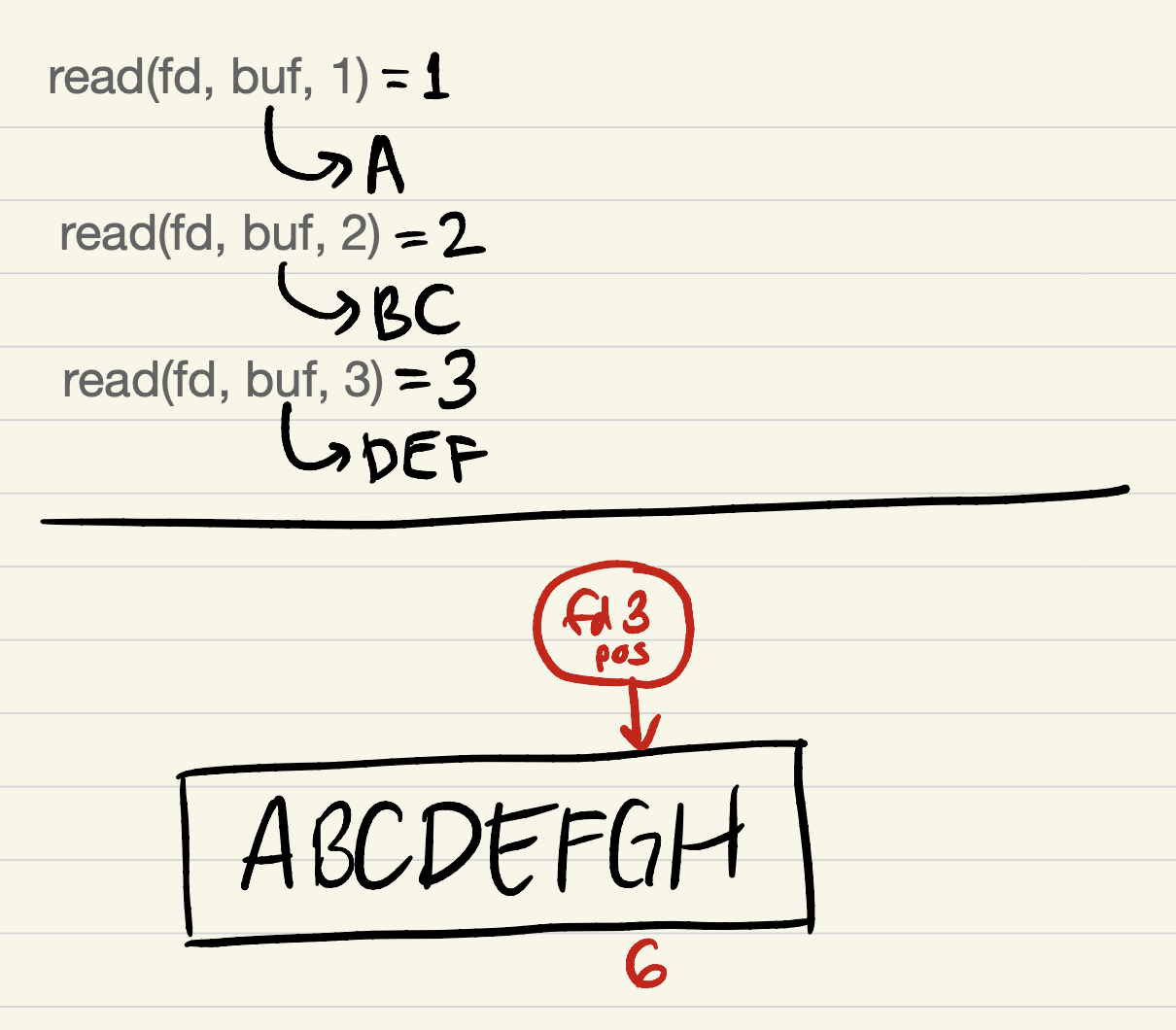
The kernel maintains all file positions: user processes can only observe or
affect a file position by making a system call, such as read, write, or
lseek. The lseek system call modifies the file position
without transferring data, and is required to read or write a file out of
sequential order.
strace exercises
Test your knowledge by characterizing access patterns and cache types given
some system call traces produced by strace!
Recall that strace is run like this:
$ strace -o strace.out PROGRAMNAME ARGUMENTS...
This runs PROGRAMNAME with the given ARGUMENTS, but simultaneously snoops
on all the system calls PROGRAMNAME makes and writes a readable summary of
those system calls to strace.out. You can examine that output using your
favorite editor or by running less strace.out. The first part of an strace
comprises boilerplate caused by program startup. It’s usually pretty easy to
tell where the boilerplate ends and program execution begins; for example, you
might look for the first open calls that refer to data files, rather than
program libraries; or the first accesses to standard input and standard output
(file descriptors 0 and 1), which are not accessed during program startup. You
can find out about any system call in an strace by reading its manual page
(e.g., man 2 read), but it’s best to focus your attention on a handful of
system calls that correspond to file access: open,
read, write, lseek,
close. (File descriptor notes)
In the cs61-sections/storages1 directory, you’ll see a bunch of truncated
strace output in files straceNN.out.
EXERCISE. Describe the access pattern for standard input in
strace01.out. What block size is being accessed? What access pattern? Is a standard I/O cache likely in use by this program?
EXERCISE. Describe the access pattern for standard input in
strace02.out. What block size is being accessed? What access pattern? Is a standard I/O cache likely in use by this program?
HOME EXERCISE. Describe the access patterns for standard output in
strace01.outandstrace02.out. Are they the same or different? What block sizes are being accessed? What access patterns? Is a standard I/O cache likely in use?
HOME EXERCISES. Describe the access patterns for the other
strace*.outfiles.
Single-slot cache
A single-slot cache is, as the name suggests, a cache comprising a single slot. The standard I/O cache implemented in most operating systems’ standard I/O libraries has a single slot. In the rest of section, we’re going to work on a specific representation of a single-slot I/O cache. The purpose is to explain such caches and to get you used to thinking in terms of file offsets.
Here’s the representation.
struct io61_file {
int fd;
static constexpr off_t bufsize = 4096; // block size for this cache
unsigned char cbuf[bufsize];
// These “tags” are addresses—file offsets—that describe the cache’s contents.
off_t tag; // file offset of first byte in cache (0 when file is opened)
off_t end_tag; // file offset one past last valid byte in cache
off_t pos_tag; // file offset of next char to read in cache
};
pos_tag refers to the effective file position for users of io61 functions.
That is, the next io61_read or io61_write function should begin at the
file offset represented by pos_tag. Note that this is often different from
the actual file position!
Example single-slot cache for reading
To demonstrate how this single-slot cache representation might work, we walk
through the file position example with a small
bufsize of 4 for clarity. Recall that the goal of a cache for reads is to
produce equivalent results to a series of system calls, so our
io61_reads should return the same bytes in the same order as the reads
above.
-
The cache is initialized to an empty state, with
fd3,bufsiz4, and all oftag,pos_tag, andend_tagequal to 0. When the firstio61_readrequest is passed to the cache, it must fill its buffer with a call toread.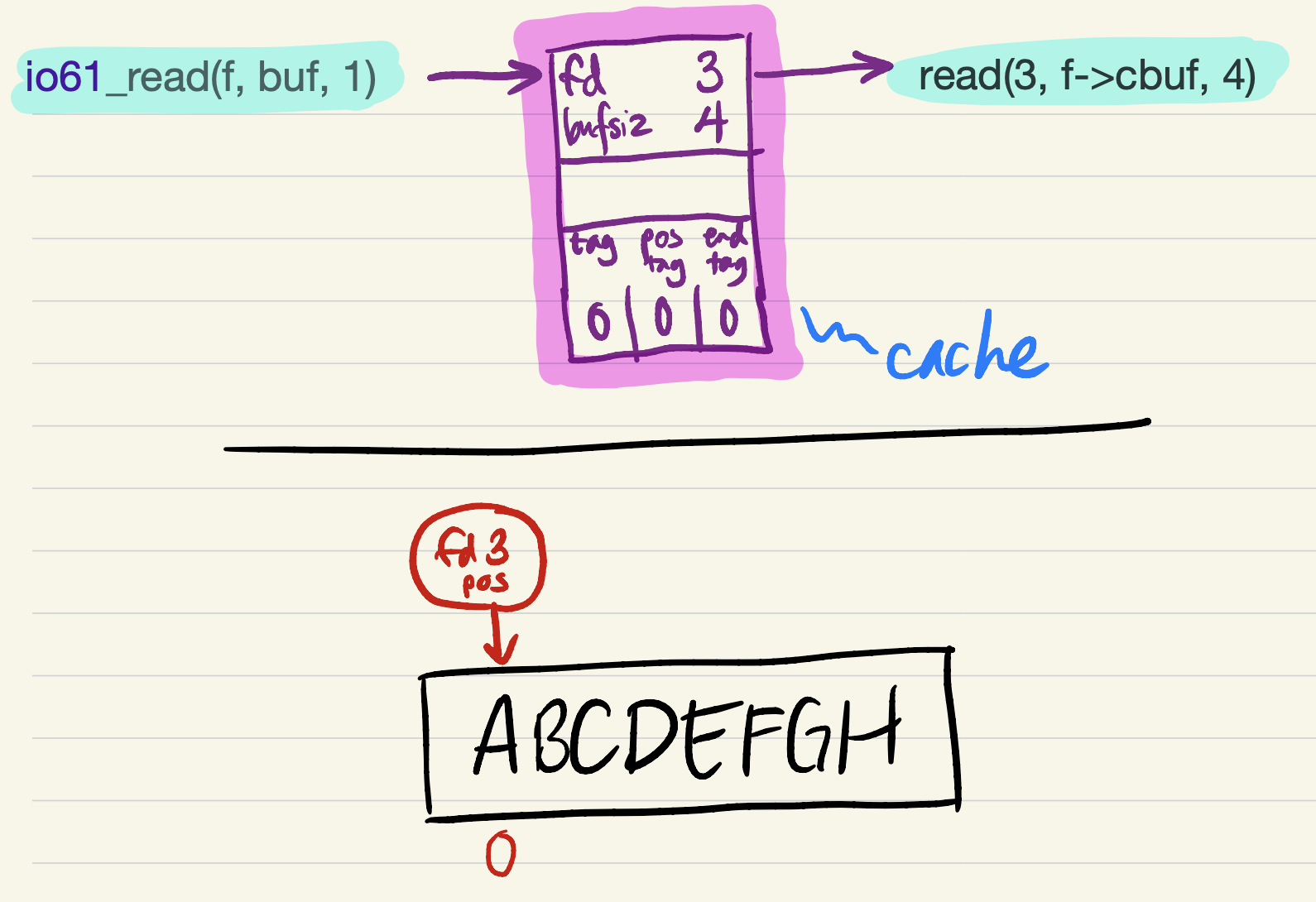
-
The read succeeds, filling all 4 bytes in
cbuf. Theend_tagis updated to indicate that the cache is full (contains 4 bytes of file data).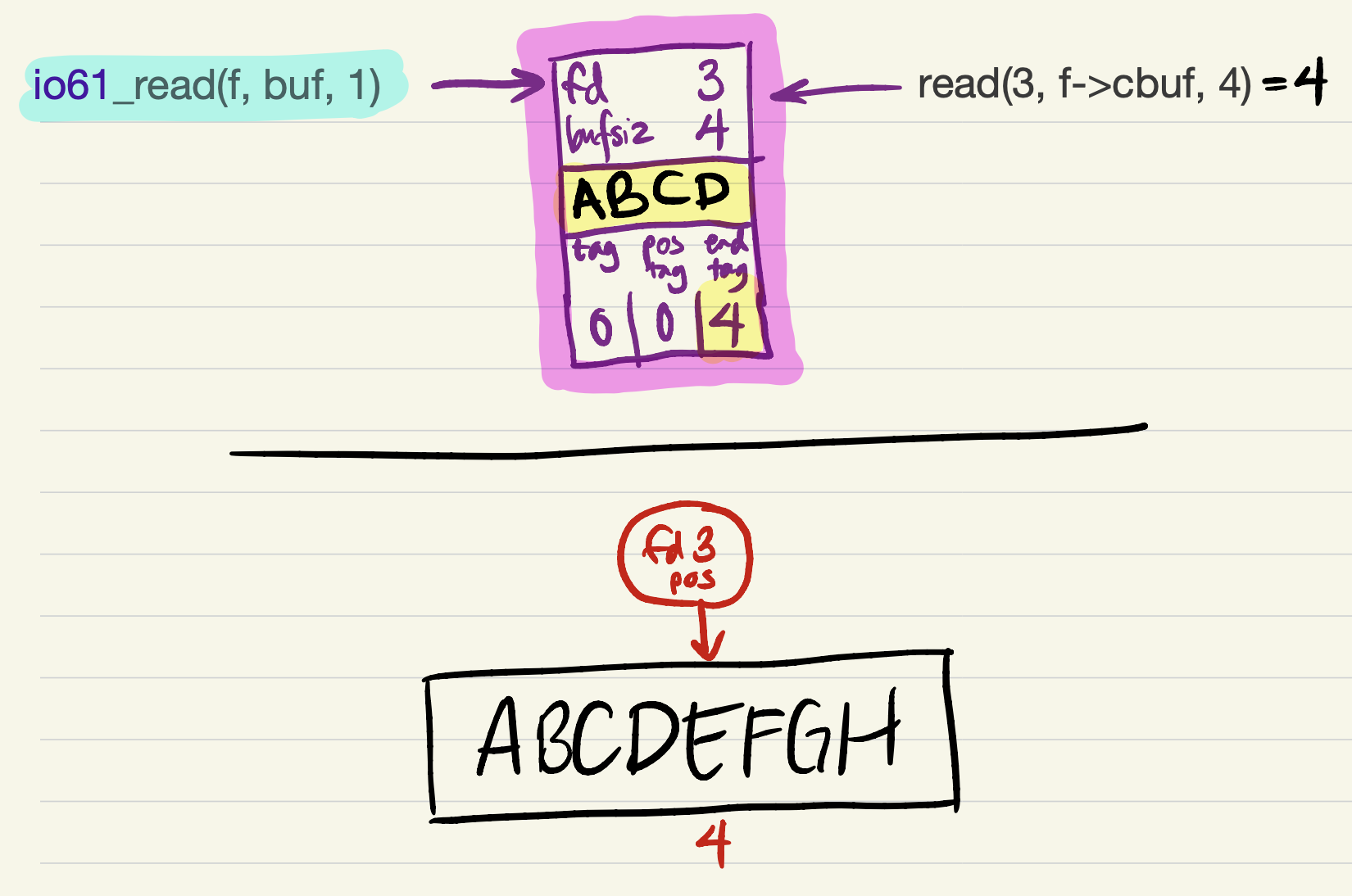
-
Now there is enough data in the cache to fulfill the
io61_readrequest. The request starts from the offset corresponding topos_tag, and must incrementpos_tagaccording to the amount read (just asreadupdates the kernel’s file position by the amount read).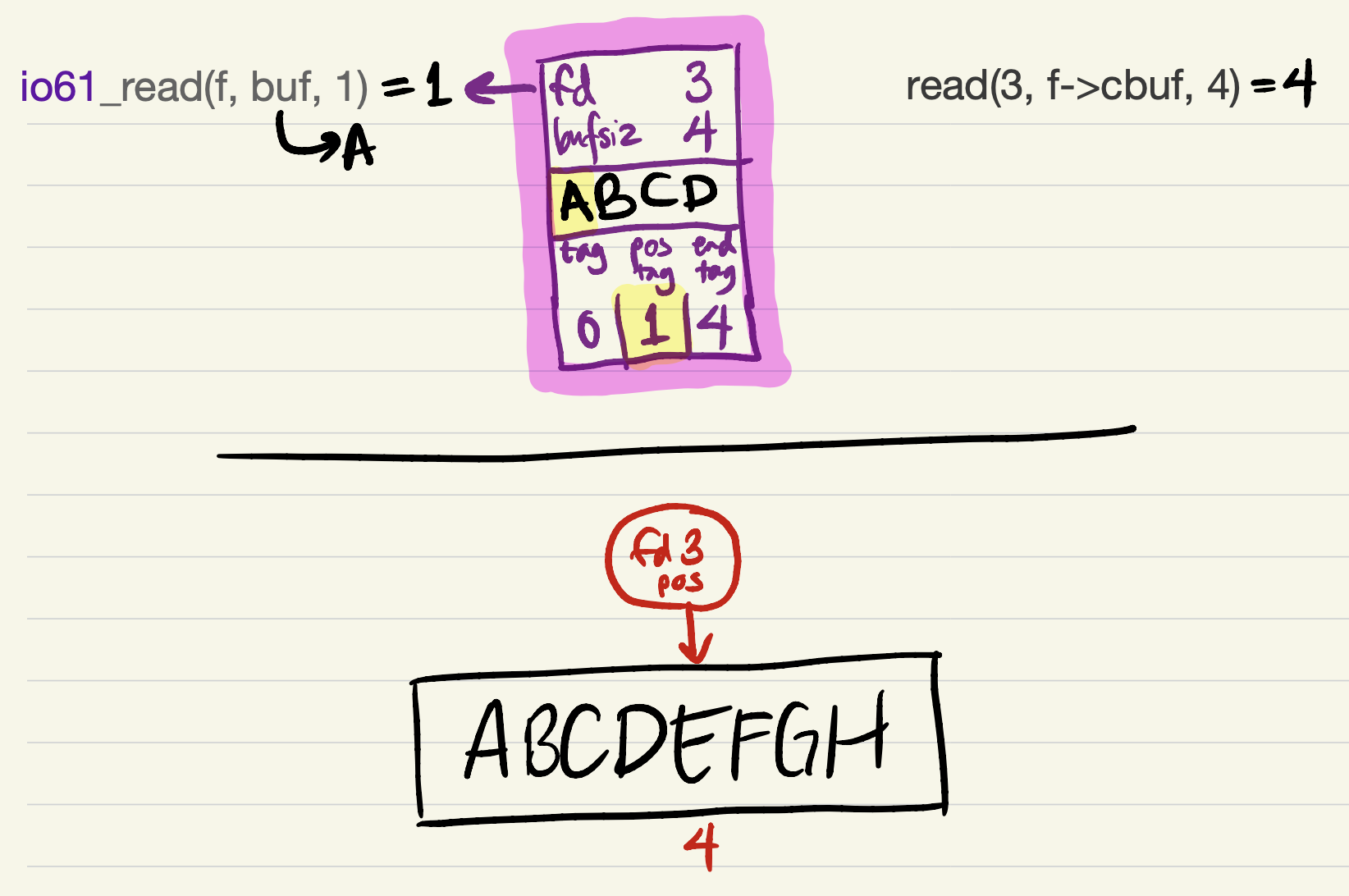
-
The next
io61_readrequest can be satisfied entirely from the cache. No system calls occur, so the kernel’s file position is unchanged.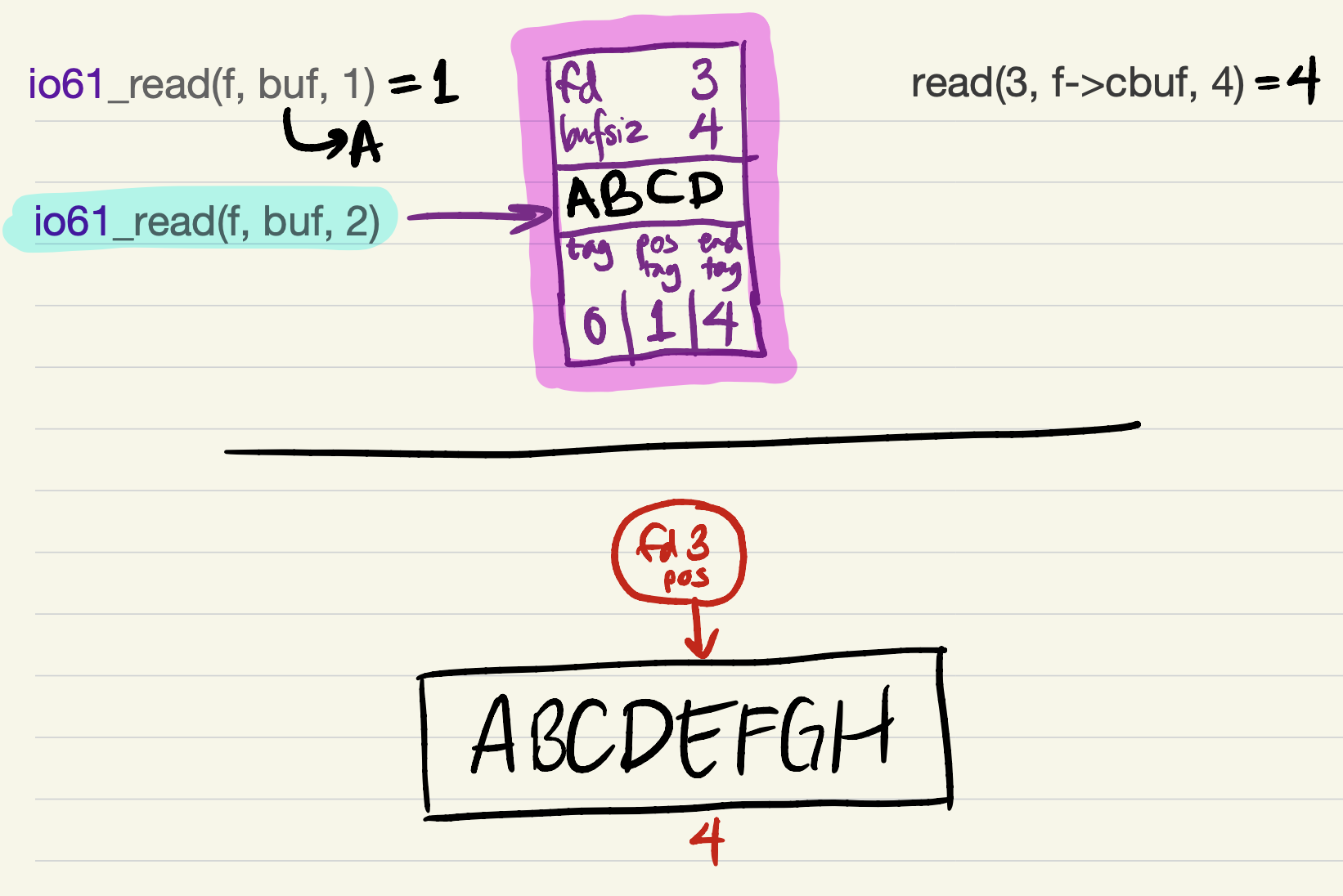
-
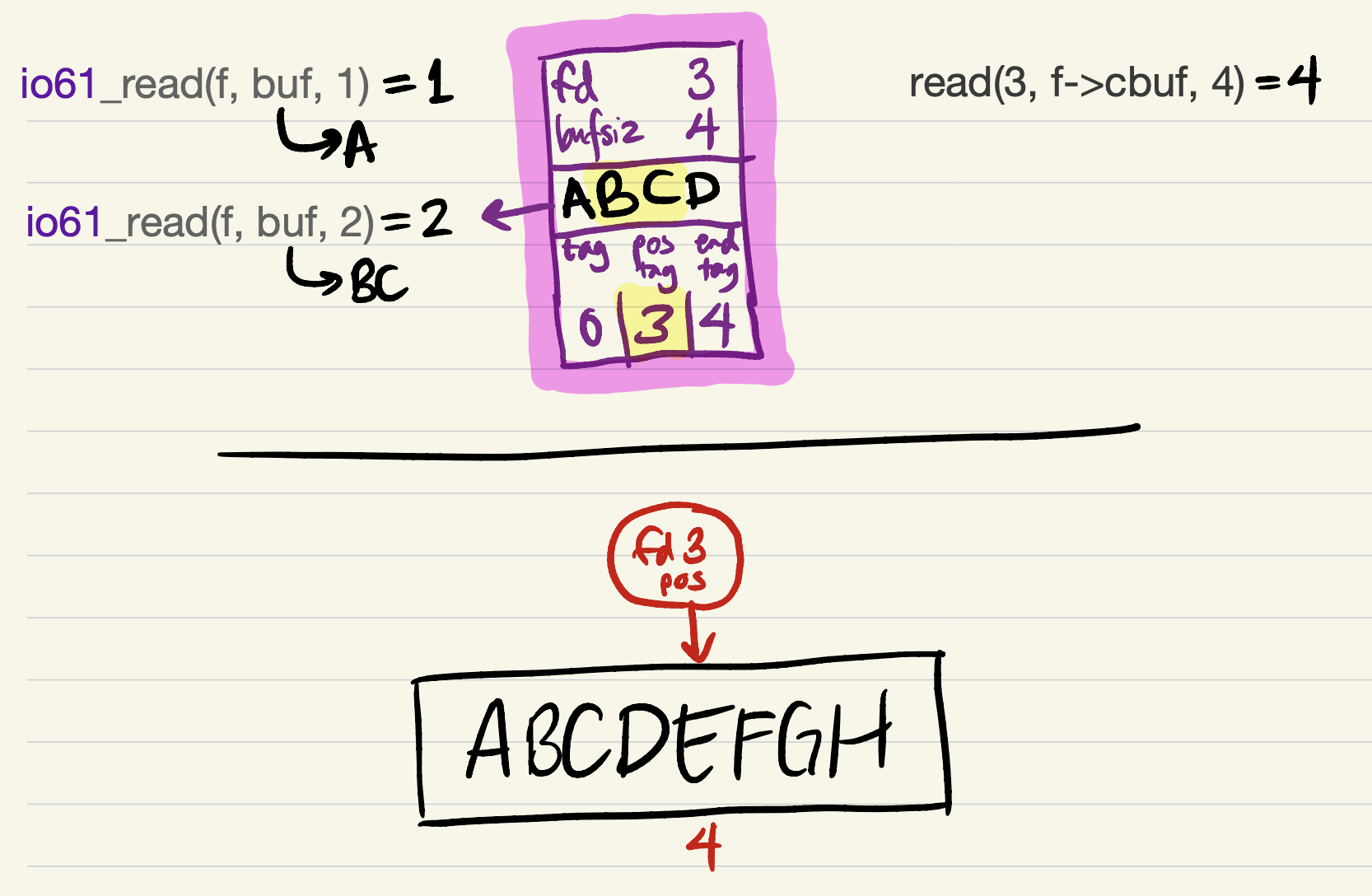
-
The cache contains just 1 byte of data after
pos_tag, so the nextio61_readrequest can only be partially satisfied at first.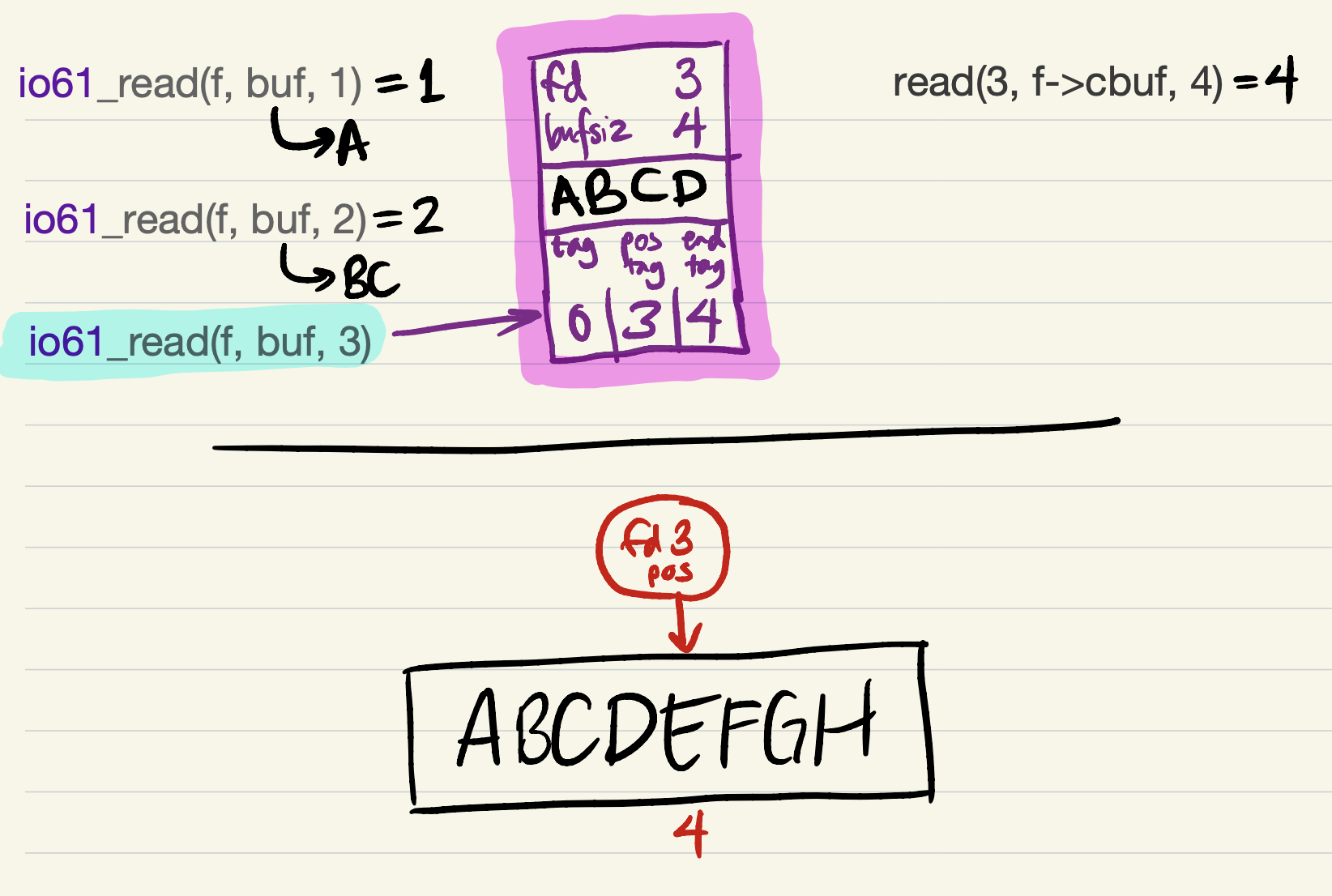
-
Since short reads and writes are allowed by the specifications of
io61_readandio61_write, it would be safe forio61_readto return now, with a short read of 1 byte! This still counts as equivalent to the version with system calls, because the same bytes are being returned in the same order.2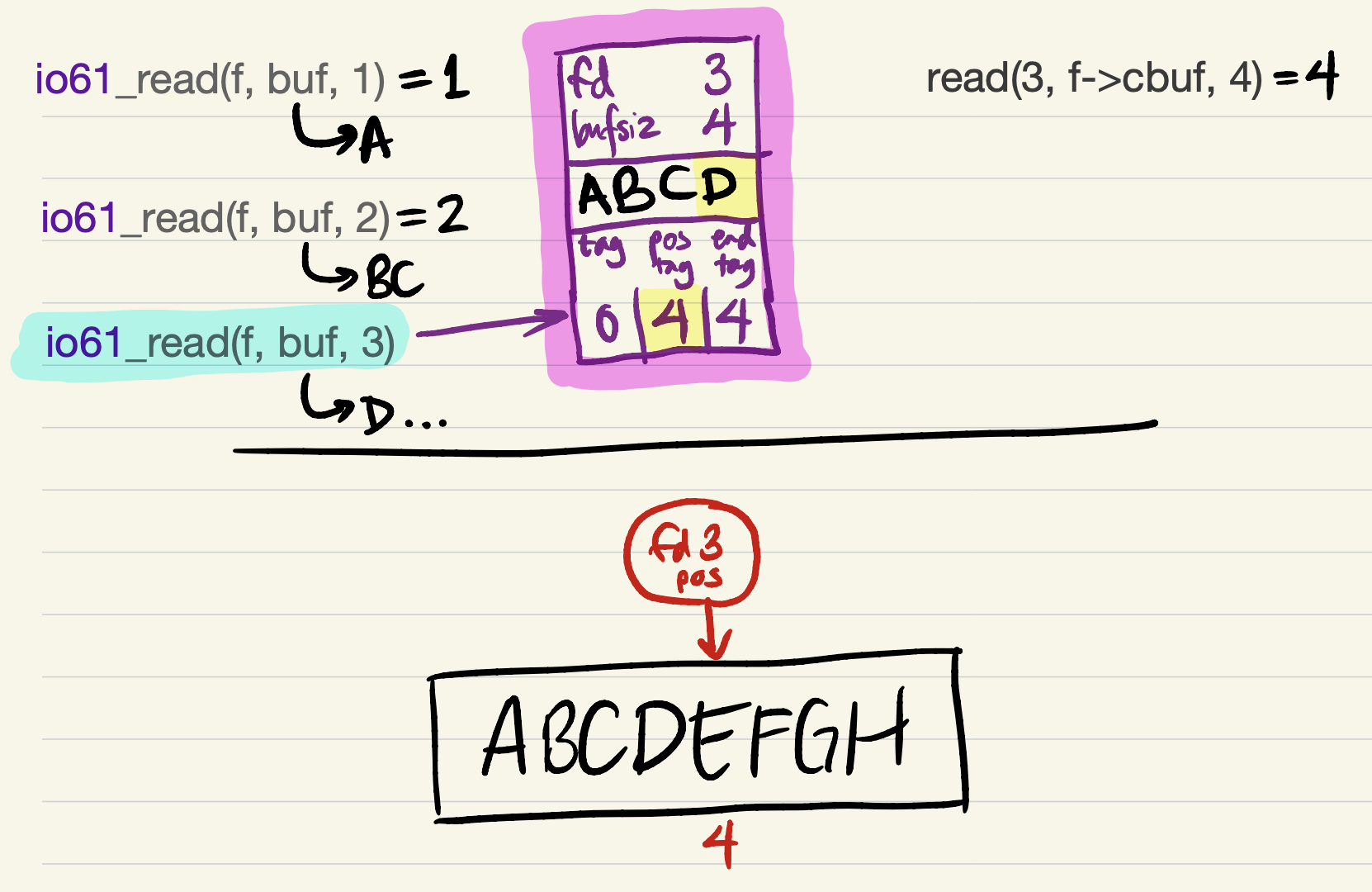
-
But it’s probably better to try to return as much data as the user requested. This requires refilling the cache. We update
tagbefore refilling the cache (because the offset of the first cached byte would equal the file position);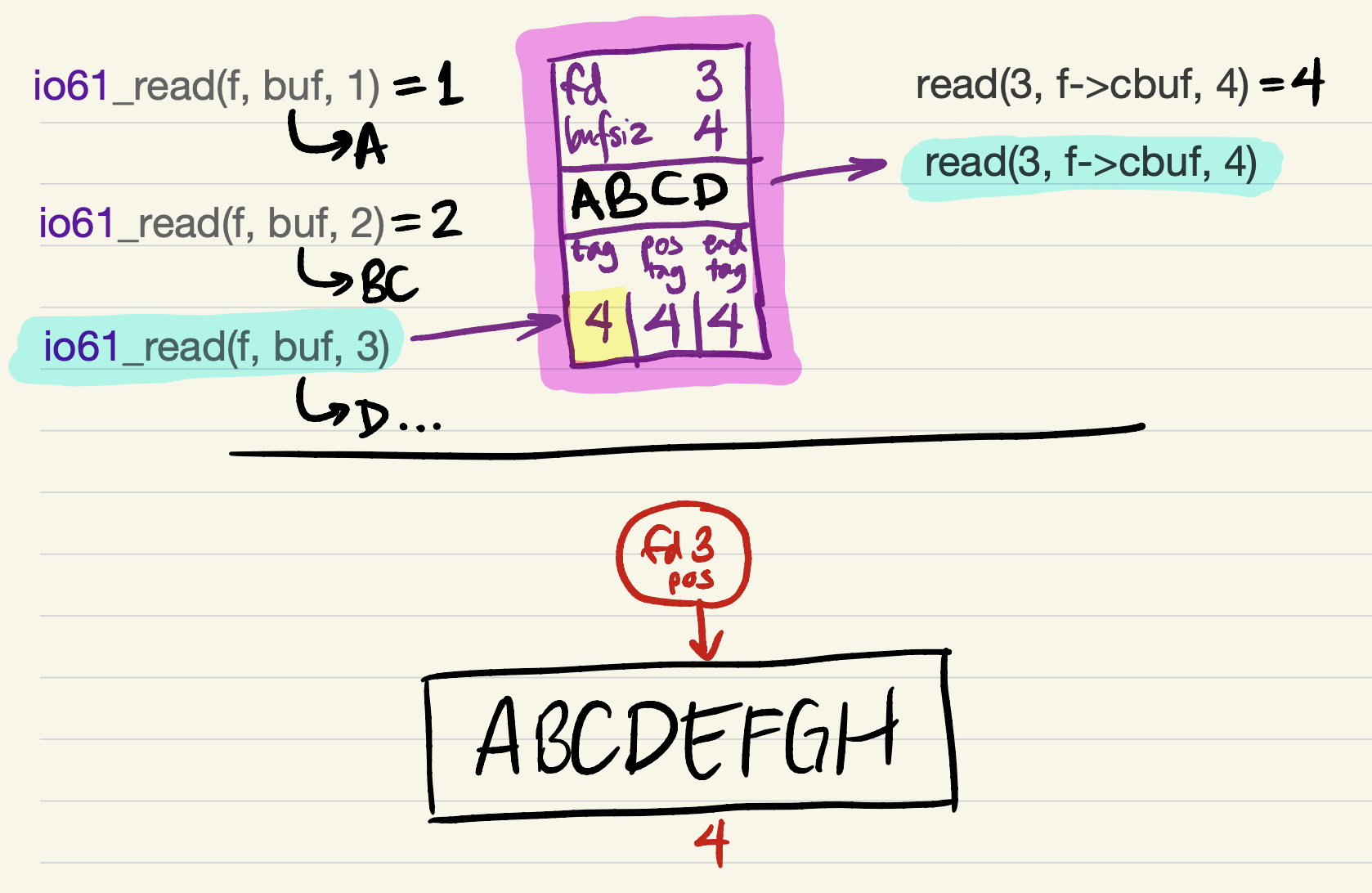
-
and then, after the
readsucceeds, updateend_tag(because the cache is filled).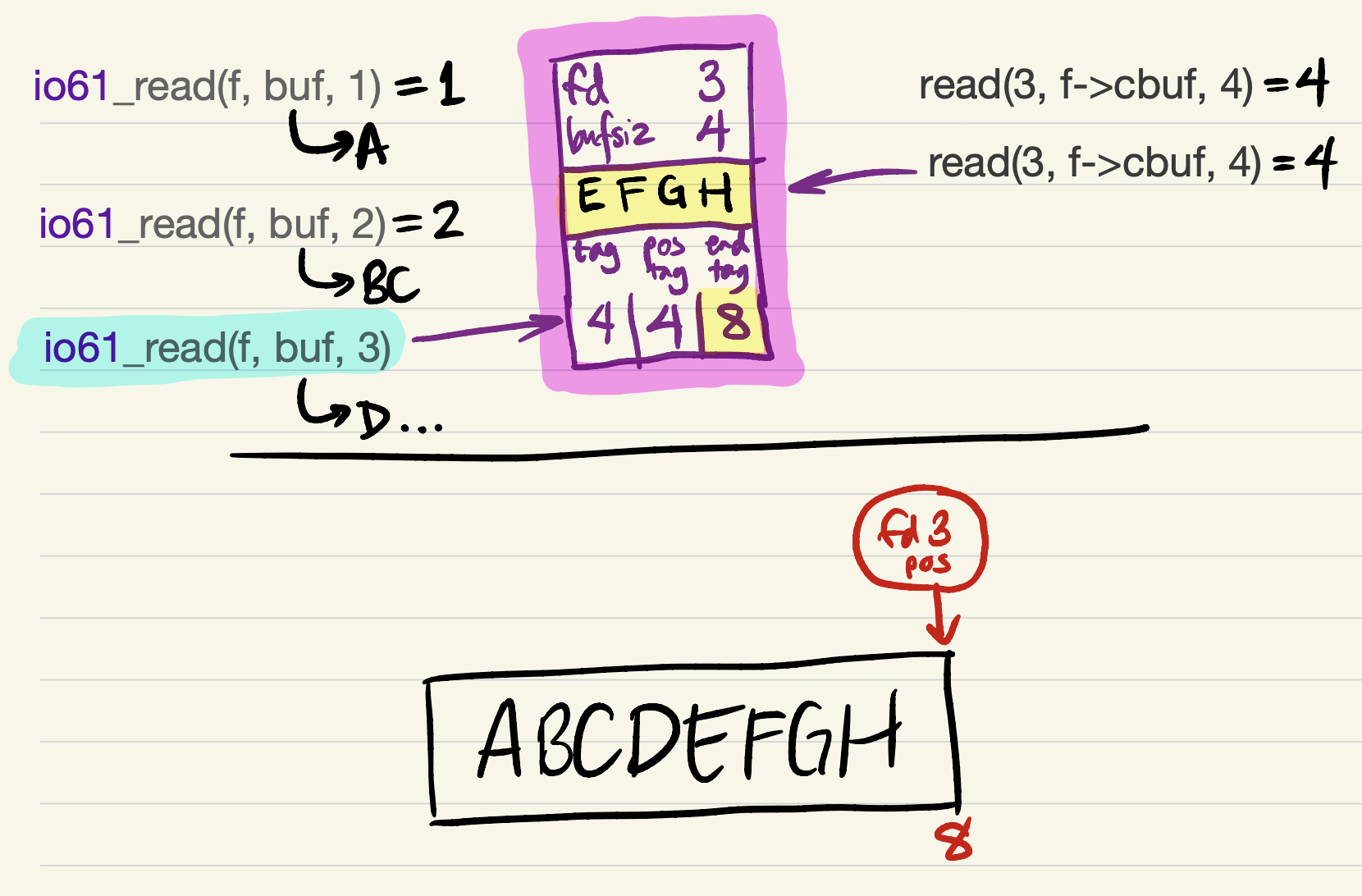
-
Finally, the last 2 bytes can be returned to the user.
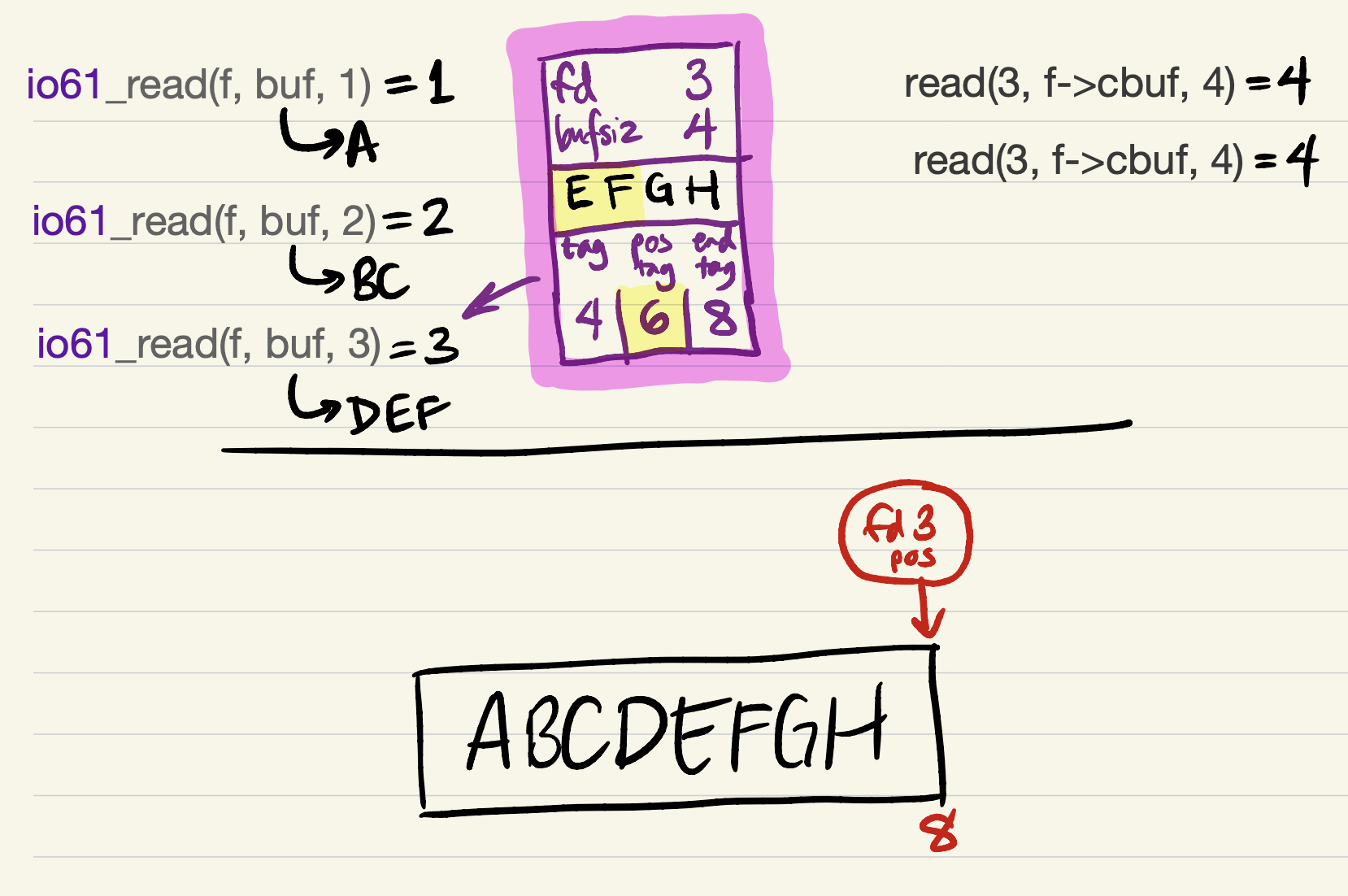
Cache invariants
Here are some facts about this cache representation.
tag <= end_tag. This is an invariant: an expression that is always true for every cache. You could encode the invariant as an assertion:assert(tag <= end_tag).- The cache slot contains
end_tag - tagbytes of valid data. - If
tag == end_tag, then the cache slot is empty (contains no valid data). - If
tag <= o < end_tag, then bytecbuf[o - tag]corresponds to the byte of file data at offseto.
- The cache slot contains
end_tag - tag <= bufsize. Another invariant: the cache slot contains space for at mostbufsizedata bytes.tag <= pos_tag && pos_tag <= end_tag. Another invariant: thepos_taglies between thetagandend_tag, inclusive.- The file descriptor’s file position equals
end_tagfor read caches of seekable files. It equalstagfor write caches of seekable files. - A
io61_readorio61_writecall should begin accessing the file at the offset equal topos_tag. Thus, the first byte read byio61_readshould come from file offsetpos_tag.
Fill read cache
We strongly recommend that you try these exercises yourself before looking at the solutions. As you implement, remember the invariants: we find the invariants and representation extremely good guidance for a correct implementation.
EXERCISE SS1. Implement this function, which should fill the cache with data read from the file. You will make a
readsystem call.void io61_fill(io61_file* f) { // Fill the read cache with new data, starting from file offset `end_tag`. // Only called for read caches. // Check invariants. assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); // Reset the cache to empty. f->tag = f->pos_tag = f->end_tag; // Recheck invariants (good practice!). assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); }
Read from read cache (simple version)
EXERCISE SS2. Implement
io61_read, assuming that the desired data is entirely contained within the current cache slot.ssize_t io61_read(io61_file* f, unsigned char* buf, size_t sz) { // Check invariants. assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); // The desired data is guaranteed to lie within this cache slot. assert(sz <= f->bufsize && f->pos_tag + sz <= f->end_tag); }
Read from read cache (full version)
EXERCISE SS3. Implement
io61_readwithout that assumption. You will need to callio61_fill, and will use a loop. You may assume that no call toreadever returns an error.Our tests do not check whether your IO61 library handles errors correctly. This means that you may assume that no
readandwritesystem call returns a permanent error. But the best implementations will handle errors gracefully: if areadsystem call returns a permanent error, thenio61_readshould return -1. (What to do with restartable errors is up to you, but most I/O libraries retry on encounteringEINTR.)ssize_t io61_read(io61_file* f, unsigned char* buf, size_t sz) { // Check invariants. assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); }
Write to write cache (easy version)
When reading from a cached file, the library fills the cache using system calls and empties it to the user. Writing to a cached file is the converse: the library fills the cache with user data and empties it using system calls.
For a read cache, the cache buffer region between pos_tag and end_tag
contains data that has not yet been read, and the region after end_tag (if
any) is invalid. There are several reasonable choices for write caches; in
these exercises we force pos_tag == end_tag as an additional invariant.
EXERCISE SS4. Implement
io61_write, assuming that space for the desired data is available within the current cache slot.ssize_t io61_write(io61_file* f, const unsigned char* buf, size_t sz) { // Check invariants. assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); // Write cache invariant. assert(f->pos_tag == f->end_tag); // The desired data is guaranteed to fit within this cache slot. assert(sz <= f->bufsize && f->pos_tag + sz <= f->tag + f->bufsize); }
Flush write cache
EXERCISE SS5. Implement a function that empties a write cache by flushing its data using a system call. As before, you may assume that the system call succeeds (all data is written).
void io61_flush(io61_file* f) { // Check invariants. assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); // Write cache invariant. assert(f->pos_tag == f->end_tag); }
Write to write cache (full version)
EXERCISE SS6. Implement a function that implements write without the assumption from Exercise SS4. You will call
io61_flushand use a loop.ssize_t io61_write(io61_file* f, const unsigned char* buf, size_t sz) { // Check invariants. assert(f->tag <= f->pos_tag && f->pos_tag <= f->end_tag); assert(f->end_tag - f->pos_tag <= f->bufsize); // Write cache invariant. assert(f->pos_tag == f->end_tag); }
Seeks
To continue with this implementation offline, try adding an implementation of
io61_seek. How should this function change the representation? Think about
the invariants!
Aside: Running blktrace
If you’re interested in exploring the pattern of references made to a
physical hard disk, you can try running blktrace, a Linux program
that helps debug the disk requests made by an operating system in the
course of executing other programs. This is below the level of system
calls: a single disk request might be made in response to multiple
system calls, and many system calls (such as those that access the
buffer cache) do not cause disk requests at all.
Install blktrace with sudo yum install blktrace (on Ubuntu), and run it
like this:
$ df . # figure out what disk you’re on
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 61897344 18080492 41107316 31% /
$ sudo sh -c "blktrace /dev/sda1 &" # puts machine-readable output in `sda1.blktrace.*`
$ PROGRAMNAME ARGUMENTS...
$ sudo killall blktrace
=== sda1 ===
CPU 0: 282 events, 14 KiB data
CPU 1: 658 events, 31 KiB data
Total: 940 events (dropped 0), 45 KiB data
$ blkparse sda1 | less # parses data collected by blktrace
The default output of blkparse has everything anyone might want to know, and
is a result is quite hard to read. Try this command line to restrict the
output to disk requests (“-a issue”, which show up as lines with “D”) and
request completions (“-a complete” and “C”).
$ blkparse -a issue -a complete -f "%5T.%9t: %2a %3d: %8NB @%9S [%C]\n" sda1 | less
With those arguments, blkparse output looks like this:
0.000055499: D R: 16384B @ 33902656 [bash]
0.073827694: C R: 16384B @ 33902656 [swapper/0]
0.074596596: D RM: 4096B @ 33556536 [bash]
0.090967020: C RM: 4096B @ 33556536 [swapper/0]
0.091078346: D RM: 4096B @ 33556528 [bash]
0.091270951: C RM: 4096B @ 33556528 [swapper/0]
0.091432386: D WS: 4096B @ 24284592 [bash]
0.091619438: C WS: 4096B @ 24284592 [swapper/0]
0.100106375: D WS: 61440B @ 17181720 [kworker/0:1H]
0.100526435: C WS: 61440B @ 17181720 [swapper/0]
0.100583894: D WS: 4096B @ 17181840 [jbd2/sda1-8]
| | | | | |
| | | | | |
| | | | | +--- responsible command
| | | | |
| | | | +----------- disk offset of read or write
| | | +-------------------- number of bytes read or written
| | |
| | +------------------------------ Read or Write (plus other info)
| +---------------------------------- D = request issued to device,
| C = request completed
|
+------------------------------------------- time of request