Exercises not as directly relevant to this year’s class are marked with ⚠️.
KERN-1. Virtual memory
QUESTION KERN-1A. What is the x86-64 page size? Circle all that
apply.
4096 bytes
64 cache lines
256 words
0x1000 bytes
216 bits
None of the above
#1, #2, #4. The most common x86-64 cache line size is 64 =
26 bytes, and 26×26 = 212,
but there may have been some x86-64 processors with 128-byte cache lines.
The word size is 8; 256×8 = 2048, not 4096. There are 8 bits per byte;
216/8 = 213, not 212.
The following questions concern the sizes of page tables. Answer the questions
in units of pages. For instance, the page tables in WeensyOS each contained
one level-4 page table page (the highest level, corresponding to address bits
39-47); one level-3 page table page; one level-2 page table page; and two
level-1 page table pages, for a total size of 5 pages per page table.
QUESTION KERN-1B. What is the maximum size (in pages) of an x86-64
page table (page tables only, not destination pages)? You may write an
expression rather than a number.
QUESTION KERN-1C. What is the minimum size (in pages) of an x86-64
page table that would allow a process to access 221 distinct
physical addresses?
4 is a good answer—x86-64 page tables have four levels—but the best answer is one.
Whaaat?! Consider a level-4 page table whose first entry refers to the
level-4 page table page itself, and the other entries referred to
different pages. Like this:
Physical address
Index
Contents
0x1000
0
0x1007
0x1008
1
0x2007
0x1010
2
0x3007
0x1018
3
0x4007
…
…
…
0x1ff8
511
0x200007
With this page table in force, the 221 virtual addresses
0x0 through 0x1FFFFF access the 221 distinct physical
addresses 0x1000 through 0x200FFF.
The 64-bit x86-64 architecture is an extension of the 32-bit x86 architecture,
which used 32-bit virtual addresses and 32-bit physical addresses. But before
64 bits came along, Intel extended 32-bit x86 in a more limited way called
Physical Address Extension (PAE). Here’s how they differ.
PAE allows 32-bit machines to access up
to 252 bytes of physical memory (which is about 4000000
GB). That is, virtual addresses are 32 bits, and physical addresses
are 52 bits.
The x86-64 architecture evolves the x86 architecture to a 64-bit
word size. x86-64 pointers are 64 bits wide instead of 32. However,
only 48 of those bits are meaningful: the upper 16 bits of each
virtual address are ignored. Thus, virtual addresses are 48 bits. As
with PAE, physical addresses are 52 bits.
QUESTION KERN-1D. Which of these two machines would support a higher
number of concurrent processes?
x86-32 with PAE with 100 GB of physical memory.
x86-64 with 20 GB of physical memory.
#1 x86-32 with PAE. Each concurrent process occupies some space in
physical memory, and #1 has more physical memory.
(Real operating systems swap, so either machine could support more
processes than fit in virtual memory, but this would cause thrashing.
#1 supports more processes before it starts thrashing.)
QUESTION KERN-1E. Which of these two machines would support a higher
maximum number of threads per process?
x86-32 with PAE with 100 GB of physical memory.
x86-64 with 20 GB of physical memory.
#2 x86-64. Each thread in a process needs some address space for its
stack, and an x86-64 process address space is much bigger than an
x86-32’s.
KERN-2. Virtual memory and kernel programming
The WeensyOS kernel occupies virtual addresses 0 through 0xFFFFF; the
process address space starts at PROC_START_ADDR == 0x100000 and goes
up to (but not including) MEMSIZE_VIRTUAL == 0x300000.
QUESTION KERN-2A. True or false: On x86-64 Linux, like on WeensyOS,
the kernel occupies low virtual addresses.
False
QUESTION KERN-2B. On WeensyOS, which region of a process’s address
space is closest to the kernel’s address space? Choose from code, data,
stack, and heap.
Code
QUESTION KERN-2C. On Linux on an x86-64 machine, which region of a
process’s address space is closest to the kernel’s address space? Choose
from code, data, stack, and heap.
Stack
The next problems consider implementations of virtual memory features in a
WeensyOS-like operating system. Recall that the WeensyOS
sys_page_alloc(addr) system call allocates a new physical page at the given
virtual address. Here’s an example kernel implementation of sys_page_alloc,
taken from the WeensyOS syscall function:
caseSYSCALL_PAGE_ALLOC: {
uintptr_t addr = current->regs.reg_rdi;
/* [A] */void* pg = kalloc(PAGESIZE);
if (!pg) { // no free physical pages
console_printf(CPOS(24, 0), 0x0C00, "Out of physical memory!\n");
return-1;
}
/* [B] */// and map it into the user’s address space
vmiter(current->pagetable, addr).map((uintptr_t) pg, PTE_P | PTE_W | PTE_U);
/* [C] */return0;
}
(Assume that kalloc and kfree are correctly implemented.)
QUESTION KERN-2D. Thanks to insufficient checking, this
implementation allows a WeensyOS process to crash the operating system
or even take it over. This kernel is not isolated. What the kernel
should do is return −1 when the calling process supplies bad
arguments. Write code that, if executed at slot [A], would
preserve kernel isolation and handle bad arguments
correctly.
QUESTION KERN-2E. This implementation has another problem, which the
following process would
trigger:
voidprocess_main() {
heap_top =/* ... first address in heap region ... */;
while (1) {
sys_page_alloc(heap_top);
sys_yield();
}
}
This process code repeatedly allocates a page at the same address. What
should happen is that the kernel should repeatedly deallocate the old page
and replace it with a newly-allocated zeroed-out page. But that’s not what
will happen given the example implementation.
What will happen instead? And what is the name of this kind of problem?
Eventually the OS will run out of physical memory. At least it will
print “Out of physical memory!” (that was in the code we provided).
This is a memory leak.
QUESTION KERN-2F. Write code that would fix the problem, and name the slot
in the SYSCALL_PAGE_ALLOC implementation where your code should go. (You may
assume that this version of WeensyOS never shares process pages among
processes.)
if (vmiter(current, addr).user()) {
kfree((void*) vmiter(current, addr).pa());
}
This goes in slot A or slot B. Slot C is too late; it would free the
newly mapped page.
KERN-3. Kernel programming
WeensyOS processes are quite isolated: the only way they can communicate
is by using the console. Let’s design some system calls that will allow
processes to explicitly share pages of memory. Then the processes can
communicate by writing and reading the shared memory region. Here are
two new WeensyOS system calls that allow minimal page sharing; they
return 0 on success and –1 on error.
int share(pid_t p, void* addr)
Allow process p to access the page at address addr.
int attach(pid_t p, void* remote_addr, void* local_addr)
Access the page in process p’s address space at address
remote_addr. That physical page is added to the calling process’s
address space at address local_addr, replacing any page that was
previously mapped there. It is an error if p has not shared the
page at remote_addr with the calling process.
Here’s an initial implementation of these system calls, written as clauses in
the WeensyOS kernel’s syscall function.
The implementation stores sharing records in an array. A process may
call share successfully at most MAX_NSHARED times. After that,
its future share calls will return an error.
processes[p].nshared is initialized to 0 for all processes.
Assume that WeensyOS has been implemented as in Problem Set 4 up
through step 6 (shared read-only memory).
QUESTION KERN-3A. True or false: Given this implementation, a single
WeensyOS process can cause the kernel to crash simply by calling share
one or more times (with no process ever calling attach). If true, give
an example of a call or calls that would likely crash the kernel.
False
QUESTION KERN-3B. True or false: Given this implementation, a single
WeensyOS process can cause the kernel to crash simply by calling
attach one or more times (with no process ever calling share). If
true, give an example of a call or calls that would likely crash the
kernel.
True. If the user supplies an out-of-range process ID argument, the
kernel will try to read out of bounds of the processes array. Example
call: attach(0x1000000, 0, 0).
QUESTION KERN-3C. True or false: Given this implementation, WeensyOS
processes 2 and 3 could work together to obtain write access to the
kernel code located at address KERNEL_START_ADDR. If true, give an
example of calls that would obtain this access.
True, since the attach and share code don’t check whether the user
process is allowed to access its memory. An example:
QUESTION KERN-3D. True or false: Given this implementation, WeensyOS
processes 2 and 3 could work together to obtain write access to any
memory, without crashing or modifying kernel code or data. If true,
give an example of calls that would obtain access to a page mapped at
address 0x110000 in process 5.
The best answer here is false. Processes are able to gain access to any
page mapped in one of their page tables. But it’s not clear whether 5’s
0x110000 is mapped in either of the current process’s page tables. Now,
2 and 3 could first read the processes array (via share/attach) to
find the physical address of 5’s page table; then, if 2 and 3 are in
luck and the page table itself is mapped in their page table, they could
read that page table to find the physical address of 0x110000; and then,
if 2 and 3 are in luck again, map that page using the VA accessible in
one of their page tables (which would differ from 0x110000). But that
might not work.
QUESTION KERN-3E. True or false: Given this implementation, WeensyOS
child processes 2 and 3 could work together to modify the code run by a
their shared parent, process 1, without crashing or modifying kernel
code or data. If true, give an example of calls that would obtain write
access to process 1’s code, which is mapped at address
PROC_START_ADDR.
True; since process code is shared after step 6, the children can map
their own code read/write, and this is the same code as the parent’s.
QUESTION KERN-3F. Every “true” answer to the preceding questions is
a bug in WeensyOS’s process isolation. Fix these bugs. Write code
snippets that address these problems, and say where they go in the
WeensyOS code (for instance, you could refer to bracketed letters to
place your snippets); or for partial credit describe what your code
should do.
Here’s one possibility.
Prevent share from sharing an invalid address in [A]:
if ((addr &0xFFF) || addr < PROC_START_ADDR) {
return-1;
}
NB don’t need to check addr < MEMSIZE_VIRTUAL as long as we check the
permissions from vmiter below (but that doesn’t hurt).
Prevent attach from accessing an invalid process or mapping at an
invalid address in [B]:
Check the mapping at remote_addr before installing it in [E]:
if (!it.user()) {
return-1;
}
Also, in the ….map call, use it.perm() instead of PTE_P|PTE_W|PTE_U.
For greatest justice we would also fix a potential memory leak caused by
attaching over an address that already had a page, but this isn’t
necessary.
KERN-4. Teensy OS VM System
The folks at Teensy Computers, Inc, need your help with their VM system.
The hardware team that developed the VM system abruptly left and the
folks remaining aren't quite sure how VM works. I volunteered you to
help them.
The Teensy machine has a 16-bit virtual address space with 4 KB pages.
The Teensy hardware specifies a single-level page table. Each entry in
the page table is 16-bits. Eight of those bits are reserved for the
physical page number and 8 of the bits are reserved for flag values.
Sadly, the hardware designers did not document what the bits do!
QUESTION KERN-4A. How many pages are in the Teensy virtual address
space?
16 (24)
QUESTION KERN-4B. How many bits comprise a physical address?
20 (8 bits of physical page number + 12 bits of page offset)
QUESTION KERN-4C. Is the physical address space larger or smaller
than the virtual address space?
Larger!
QUESTION KERN-4D. Write, in hex, a PAGE_OFFSET_MASK (the value
that when anded with an address returns the offset of the address on a
page).
0xFFF
QUESTION KERN-4E. Write a C expression that takes a virtual address,
in the variable vaddr, and returns the virtual page number.
(vaddr >> 12) OR ((vaddr) & 0xF000 >> 12)
You are now going to work with the Teensy engineers to figure out what
those other bits in the page table entries mean! Fortunately, they have
some engineering notes from the hardware team—they need your help in
making sense of them. Each letter below has the contents of a note,
state what you can conclude from that note about the lower 8 bits of the
page table entries.
QUESTION KERN-4F. “Robin, I ran 8 tests using a kernel that did
nothing other than loop infinitely -- for each test I set a different
bit in all the PTEs of the page table. All of them ended up in the
exception handler except for the one where I set bit 4. Any idea what
this means?”
Bit 4 is the “present/valid bit”, the equivalent of x86 PTE_P.
QUESTION KERN-4G. “Lynn, I'm writing a memory test that iterates
over all of memory making sure that I can read back the same pattern I
write into memory. If I don't set bit 7 of the page table entries to 1,
I get permission faults. Do you know what might be happening?”
Bit 1 is the “writable bit”, the equivalent of x86 PTE_W.
QUESTION KERN-4H. “Pat, I almost have user level processes running!
It seems that the user processes take permission faults unless I have
both bit 4 and bit 3 set. Do you know why?”
Bit 3 is the “user/unprivileged bit”, the equivalent of x86 PTE_U.
KERN-5. Teensy OS Page Tables
The Teensy engineers are well on their way now, but they do have a few bugs
and they need your help debugging the VM system. They hand you the following
page table, using x86-64 notation for permissions, and need your help
specifying correct behavior for the operations that follow.
Index
Entry contents:
Page number of physical page
Permissions
0
0x00
PTE_U
1
0x01
PTE_P
2
0x02
PTE_P|PTE_W
3
0x03
PTE_P|PTE_W|PTE_U
4
0xFF
PTE_W|PTE_U
5
0xFE
PTE_U
6
0x80
PTE_W
7
0x92
PTE_P|PTE_W|PTE_U
8
0xAB
PTE_P|PTE_W|PTE_U
9
0x09
PTE_P|PTE_U
10
0xFE
PTE_P|PTE_U
11
0x00
PTE_W
12
0x11
PTE_U
All others
(Invalid)
0
For each problem below, write either the physical address of the given
virtual address or identify what fault would be produced. The fault
types should be one of:
Missing page (there is no mapping for the requested page)
Privilege violation (user level process trying to access a
supervisor page)
Permission violation (attempt to write a read-only page)
QUESTION KERN-5A. The kernel dereferences a null pointer
Missing page
QUESTION KERN-5B. A user process dereferences a null pointer
Missing page
QUESTION KERN-5C. The kernel writes to the address 0x8432
0xAB432
QUESTION KERN-5D. A user process writes to the address 0xB123
Missing page (when both PTE_P and PTE_U are missing, it's
PTE_P that counts)
QUESTION KERN-5E. The kernel reads from the address 0x9876
0x09876
QUESTION KERN-5F. A user process reads from the address 0x7654
0x92654
QUESTION KERN-5G. A user process writes to the address 0xABCD
Permission violation
QUESTION KERN-5H. A user process writes to the address 0x2321
Privilege violation
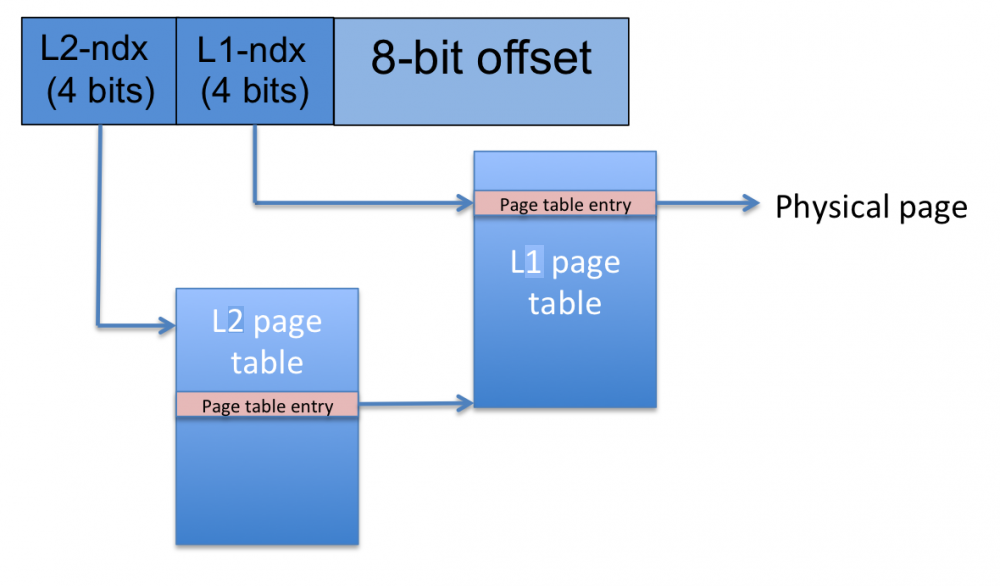
KERN-6. Virtual Memory
You may recall that Professor Seltzer loves inventing strange and
wonderful virtual memory systems—she’s at it again! The Tom and Ginny
(TAG) processor has 16-bit virtual addresses and 256-byte pages. Virtual
memory translation is provided via two-level page tables as shown in the
figure below.
QUESTION KERN-6A. How many entries are in an L1 page table?
16
QUESTION KERN-6B. How many entries are in an L2 page table?
16
QUESTION KERN-6C. If each page table entry occupies 2 bytes of
memory, how large (in bytes) is a single page table?
One good answer is 32 bytes (= 2 * 16). 256 also makes sense—page tables
start on page boundaries on most architectures, and TAG pages are 256 pages
long—but most of that space would be unused for page table data.
QUESTION KERN-6D. What is the maximum number of L1 page table pages that
a process can have?
16
QUESTION KERN-6E. What is the maximum number of L2 page table pages that
a process can have?
1
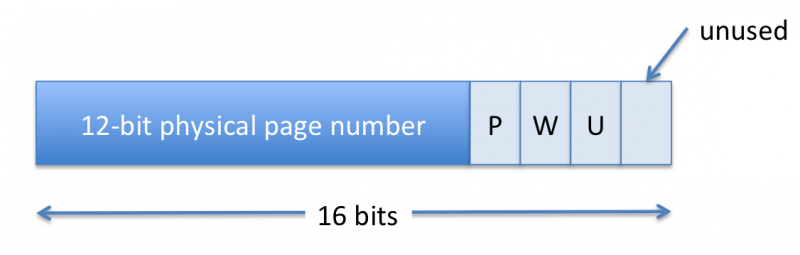
QUESTION KERN-6F. The figure below shows how the PTEs are organized.
Given the number of bits allocated to the physical page number in the PTE, how
much physical memory can the TAG processor support?
12 bits of page number plus 8 bits of page offset is 20 bits, which is 1
MB.
QUESTION KERN-6G. Finally, you’ll actually perform virtual address
translation in software. We will define a TAG page table entry as follows:
typedef uint16_t tag_pageentry;
Write a function unsigned virtual_to_physical(tag_pageentry* pagetable,
unsigned vaddr) that takes as arguments:
pagetable: a TAG page table (that is, a pointer to the first
entry in the L2 page table)
vaddr: a TAG virtual address
and returns a physical address if a valid mapping exists and an invalid
physical address if no valid mapping exists. Comment your code to explain each
step that you want the function to take. You may assume that the current page
table is identity-mapped page table (i.e., each virtual address maps to the
physical address with the same numeric value), and that all page table pages
are accessible via that current page table.
#define PTE_P 8
unsignedvirtual_to_physical(tag_pageentry* pagetable, uint16_t vaddr) {
// grab the PTE for the L1 page table
tag_pageentry pte = pagetable[(vaddr >>12) &0xF];
if ((pte & PTE_P) ==0) {
return INVALID_PHYSADDR;
}
// Calculate L1 page table
uint16_t* l1pt = (uint16_t*) ((pte &~0xF) <<4);
// This loses the upper 4 bits of the 12-bit physical page number!
// That must be OK, because we were told that all page table pages
// are accessible.
pte = l1pt[(vaddr >>8) &0xF];
if ((pte & PTE_P) ==0) {
return INVALID_PHYSADDR;
}
return ((pte &~0xF) <<4) | (vaddr &0xFF);
}
KERN-7. Cost expressions
In the following questions, you will reason about the abstract costs of
various operations, using the following tables of constants.
Table of Basic Costs
S
System call overhead (i.e., entering and exiting the kernel)
F
Page fault cost (i.e., entering and exiting the kernel)
P
Cost of allocating a new physical page
M
Cost of installing a new page mapping
B
Cost of copying a byte
Table of Sizes
nk
Number of memory pages allocated to the kernel
np
Number of memory pages allocated to process p
rp
Number of read-only memory pages allocated to process p
wp
= np − rp
Number of writable memory pages allocated to process p
mp
Number of memory pages actually modified by process p after its previous fork()
QUESTION KERN-7A. Our tiny operating systems’ processes start out with a
single stack page each. A recursive function can cause the stack pointer to
move beyond this page, and the program to crash.
This problem can be solved in the process itself. The process can examine its
stack pointer before calling a recursive function and call sys_page_alloc to
map a new stack page when necessary.
Write an expression for the cost of this sys_page_alloc() system call in
terms of the constants above.
S + P + M
QUESTION KERN-7B. Another solution to the stack overflow issue uses the
operating system’s page fault handler. When a fault occurs in a process’s
stack region, the operating system allocates a new page to cover the
corresponding address. Write an expression for the cost of such a fault in
terms of the constants above.
F + P + M
QUESTION KERN-7C. Design a revised version of sys_page_alloc that
supports batching. Give its signature and describe its behavior.
Example: sys_page_alloc(void *addr, int npages)
QUESTION KERN-7D. Write an expression for the cost of a call to your
batching allocation API.
Can vary; for this example, S + npages*(P + M)
In the remaining questions, a process p calls fork(), which creates
a child process, c.
Assume that the base cost of performing a fork() system call is Φ.
This cost includes the fork() system call overhead (S), the overhead
of allocating a new process, the overhead of allocating a new page
directory with kernel mappings, and the overhead of copying registers.
But it does not include overhead from allocating, copying, or mapping
other memory.
QUESTION KERN-7E. Consider the following implementations of
fork():
Naive fork: Copy all process memory.
Eager fork: Copy all writable process memory; share read-only process memory, such as code.
Copy-on-write fork: Initially share all memory as read-only. Create writable copies later, on demand, in response to write faults.
Which expression best represents the total cost of the fork() system
call in process p, for each of these fork implementations? Only
consider the system call itself, not later copy-on-write faults.
(Note: Per-process variables, such as n, are defined for each
process. So, for example, np is the number of pages
allocated to the parent process p, and nc is the number
of pages allocated to the child process c.)
Φ
Φ + np × M
Φ + (np + wp) × M
Φ + np × 212 × (B + F)
Φ + np × (212B + P + M)
Φ + np × (P + M)
Φ + wp × (212B + P + M)
Φ + np × (212B + P + M) −
rp × (212B + P)
Φ + np × M + mc × (P + F)
Φ + np × M + mc × (212B + F + P)
Φ + np × M + (mp+mc) × (P + F)
Φ + np × M + (mp+mc) ×
(212B + F + P)
A: #5, B: #8 (good partial credit for #7), C: #2
QUESTION KERN-7F. When would copy-on-write fork be more efficient
than eager fork (meaning that the sum of all fork-related overheads,
including faults for pages that were copied on write, would be less for
copy-on-write fork than eager fork)? Circle the best answer.
When np < nk.
When wp × F < wp × (M + P).
When mc × (F + M + P) < wp × (M +
P).
When (mp+mc) × (F + M + P +
212B) < wp × (P + 212B).
When (mp+mc) × (F + P +
212B) < wp × (P + M +
212B).
When mp < mc.
None of the above.
#4
KERN-8. Virtual memory
QUESTION KERN-8A. What kind of address is stored in x86-64 register
%cr3, virtual or physical?
physical
QUESTION KERN-8B. What kind of address is stored in x86-64 register
%rip, virtual or physical?
virtual
QUESTION KERN-8C. What kind of address is stored in an x86-64 page table
entry, virtual or physical?
physical
QUESTION KERN-8D. What is the x86-64 word size in bits?
64
Many paged-virtual-memory architectures can be characterized in terms of the
PLX constants:
P = the length of the page offset, in bits.
L = the number of different page indexes (equivalently, the number
of page table levels).
X = the length of each page index, in bits.
QUESTION KERN-8E. What are the numeric values for P, L, and X for
x86-64?
P=12, L=4, X=9
Assume for the remaining parts that, as in x86-64, each page table page fits
within a single page, and each page table entry holds an address and some
flags, including a Present flag.
QUESTION KERN-8F. Write a PLX formula for the number of bytes per page,
using both mathematical and C notation.
Mathematical notation: _____________________
C notation: _____________________________
2P, 1 << P
QUESTION KERN-8G. Write a PLX formula for the number of meaningful bits
in a virtual address.
P + L*X
QUESTION KERN-8H. Write a PLX formula that is an upper bound on the
number of bits in a physical address. (Your upper bound should be
relatively tight; PX100L is a bad
answer.)
There are several good answers. The best answer uses the fact that a
physical address fits inside a page table entry, so the number of bits in a
physical address is limited by the number of bits in an entry. So what’s an
entry’s size? A page table contains 2X entries, and a page table
fits in 2P bytes. That leaves the number of bits as:
8 * sizeof(entry) = 8 * 2P/2X = 8 * 2P–X
Another reasonable answer assumes that virtual addresses aren’t likely to be
smaller than physical addresses, giving the answer P + L*X. (On some
machines, physical addresses have been larger than virtual addresses, but as
a general rule, virtual addresses are in fact bigger.)
QUESTION KERN-8I. Write a PLX formula for the minimum number of pages
it would take to store a page table that allows access to
2X distinct destination physical pages.
L (for a well-formed page table with distinct pages for each level), or 1
(for a “trick” page table that reuses the top-level page for all subsequent
levels; see question KERN-1C).
KERN-9. Weensy signals
WeensyOS lacks signals. Let’s add them.
⚠️ Signals are covered in the Shell unit.
Here’s sys_kill, a system call that should deliver a signal to a
process.
// sys_kill(pid, sig)
// Send signal `sig` to process `pid`.
inlineintsys_kill(pid_t pid, int sig) {
register uintptr_t rax asm("rax") = SYSCALL_KILL;
asmvolatile ("syscall":"+a" (rax), "+D" (pid), "+S" (sig)
::"cc", "rcx", "rdx", …, "memory");
return rax;
}
QUESTION KERN-9A. Implement the WeensyOS kernel syscall case for
SYSCALL_KILL. Your implementation should simply change the
receiving process’s state to P_BROKEN. Check arguments as necessary
to avoid kernel isolation violations; return 0 on success and -1 if the
receiving process does not exist or is not running. A process may kill
itself.
uintptr_t syscall(...) { ...
caseSYSCALL_KILL:
// your code here
The WeensyOS signal handling mechanism is based on that of Unix. When a
signal is delivered to a WeensyOS process:
The kernel saves the receiving process’s registers and switches the
process to signal-handling mode.
The kernel causes the receiving process to execute its signal
handler.
It creates a stack frame for the signal handler by subtracting
at least 128 bytes from the process’s stack
pointer. This ensures that the signal handler’s local variables
(if any) do not overwrite those of the interrupted function.
It sets the signal handler’s arguments. A WeensyOS signal
handler takes one argument, the signal number.
It sets the process’s instruction pointer to the signal handler
address and resumes the process.
The signal handler can tell the kernel to resume normal processing
by calling the sigreturn system call. This will restore the
registers to their saved values and resume the process.
Implement this. Begin from the following system call definitions and changes
to the WeensyOS kernel’s struct proc.
inlineintsys_kill(pid_t pid, int sig) { ... } // as above
// sys_signal(sighandler)
// Set the current process’s signal handler to `sighandler`.
inlineintsys_signal(void (*sighandler)(int)) {
register uintptr_t rax asm("rax") = SYSCALL_SIGNAL;
asmvolatile ("syscall":"+a" (rax), "+D" (sighandler)
: ...);
return rax;
}
// sys_sigreturn()
// Returns from a signal handler to normal mode. Does nothing if in normal mode already.
inlineintsys_sigreturn() {
register uintptr_t rax asm("rax") = SYSCALL_SIGRETURN;
asmvolatile ("syscall":"+a" (rax)
: ...);
return rax;
}
structproc {
x86_64_pagetable* pagetable;
pid_t pid;
regstate regs;
procstate_t state;
// Signal support:
uintptr_t sighandler; // signal handler (0 means default)
bool sigmode; // true iff in signal-handling mode
regstate saved_regs; // saved registers, if in signal-handling mode
};
QUESTION KERN-9B. Implement the WeensyOS kernel syscall case for
SYSCALL_SIGNAL.
uintptr_t syscall(...) { ...
caseSYSCALL_SIGNAL:
// your code here (< 5 lines)
QUESTION KERN-9C. Implement the WeensyOS kernel syscall case for
SYSCALL_SIGRETURN. If the current process is in signal-handling
mode (current->p_sigmode != 0), restore the saved registers and
leave signal-handling mode; otherwise simply return 0.
voidsyscall(...) { ...
caseSYSCALL_SIGRETURN:
// your code here (< 10 lines)
if (current->sigmode) {
current->regs = current->saved_regs;
current->sigmode =false;
run(current);
// not as correct as `run(current)`, but OK:
// return current->regs.reg_rax;
} else {
return0;
}
Note that it is important to call run(current) in the sigmode case,
since the normal syscall return path will not restore all registers.
QUESTION KERN-9D. Implement the WeensyOS kernel syscall case for
SYSCALL_KILL. If the receiving process’s sighandler is 0,
behave as in part A. Otherwise, if the receiving process is in
signal-handling mode, return -1 to the calling process rather than
delivering the signal. Otherwise, save the receiving process’s registers
and cause it to call its signal handler in signal-handling mode, as
described above.
uintptr_t syscall(...) { ...
caseSYSCALL_KILL:
// your code here (< 25 lines)
uintptr_t pid = current->regs.reg_rdi;
int sig = current->regs.reg_rsi;
if (pid ==0|| pid >= NPROC || proc[pid].state != P_RUNNING
|| proc[pid].sigmode) {
return-1;
} elseif (proc[pid].sighandler ==0) { // default signal handler: kill process
proc[pid].state = P_BROKEN;
return0;
} else {
proc[pid].saved_regs = proc[pid].regs;
proc[pid].regs.reg_rsp -=128; // ignore alignment
proc[pid].regs.reg_rdi = sig;
proc[pid].regs.reg_rip = proc[pid].p_sighandler;
if (pid == current->pid) {
// special case for killing self
proc[pid].saved_regs.reg_rax =0; // after signal handler runs, `kill` returns 0
run(current);
} else {
return0;
}
}
break;
QUESTION KERN-9E. Unix has some signals that cannot be caught or handled,
especially SIGKILL (signal 9), which unconditionally exits a
process. Which kernel and/or process code would change to support
equivalent functionality in WeensyOS? List all that apply.
Just the SYSCALL_KILL case in syscall.
QUESTION KERN-9F. Is it necessary to verify the signal handler address to
avoid kernel-isolation violations? Explain briefly why or why not.
No, because that address is only accessed in unprivileged mode.
QUESTION KERN-9G.BONUS QUESTION. A WeensyOS signal handler function
must end with a call to sys_sigreturn(). Describe how the WeensyOS
kernel could set it up so that sys_sigreturn() is called
automatically when a signal-handler function returns.
Write instructions to the stack, after the 128-byte region, that implement
sys_sigreturn(). Then push the address of those instructions—that will be
the return address.
KERN-10. Weensy threads
⚠️ Threads are covered in the Synchronization unit.
Betsy Ross is changing her WeensyOS to support threads. There are many
ways to implement threads, but Betsy wants to implement threads using
the ptable array. “After all,” she says, “a thread is just like a
process, except it shares memory with some other process!”
Betsy has defined a new system call, sys_create_thread, that starts a new
thread running a given thread function, with a given argument, and a given
stack pointer:
And here’s the start of her sys_create_thread implementation.
// in syscall()
caseSYSCALL_CREATE_THREAD:
return handle_create_thread(current);
...
uint64_t handle_create_thread(proc* p) {
// Whoops! Got a revolution to run, back later
return-1;
}
QUESTION KERN-10A. Complete her handle_create_thread
implementation. Assume for now that the thread function never exits. You
may use these helper functions if you need them (you may not):
proc* find_unused_process()
Return a usable proc* that has state P_FREE, or nullptr if
no unused process exists.
x86_64_pagetable* copy_pagetable(x86_64_pagetable*
pgtbl)
Return a copy of pagetable pgtbl, with all unprivileged writable
pages copied. Returns nullptr if any allocation fails.
void* kalloc(size_t)
Allocates a new physical page, zeros it, and returns its physical
address.
Recall that system call arguments are passed according to the x86-64
calling convention: first argument in %rdi, second in %rsi,
third in %rdx, etc.
QUESTION KERN-10B. Betsy’s friend Prince Dimitri Galitzin thinks
Betsy should give processes even more flexibility. He suggests that
sys_create_thread take a full set of registers, rather than just a
new instruction pointer and a new stack pointer. That way, the creating
thread can supply all registers to the new thread, rather than just a
single argument.
sys_exit_thread causes the thread to exit with the given exit
value; it does not return. sys_join_thread behaves like
pthread_join or waitpid. If thread corresponds is a thread
of the same process, and thread has exited, sys_join_thread
cleans up the thread and returns its exit value; otherwise,
sys_join_thread returns (void*) -1.
QUESTION KERN-10C. Is the sys_join_thread specification
blocking or polling?
Polling
QUESTION KERN-10D. Betsy makes the following changes to WeensyOS internal
structures to support thread exit.
She adds a void* exit_value member to struct proc.
She adds a new process state, P_EXITED, that corresponds to
exited threads.
Complete the case for SYSCALL_EXIT_THREAD in syscall(). Don’t worry about
the case where the last thread in a process calls sys_exit_thread instead of
sys_exit.
Note that we don’t even need exit_value, since we could use
regs.reg_rdi to look up the exit value elsewhere!
If you wanted to clean up the last thread in a process, you might do
something like this:
int nlive =0;
for (int i =1; i < NPROC &&!nlive; ++i) {
if (is_thread_in(i, current) && processes[i].state != P_EXITED) {
++nlive;
}
}
if (!nlive) {
for (int i =1; i < NPROC; ++i) {
if (is_thread_in(i, current)) {
do_sys_exit(&processes[i]);
}
}
}
QUESTION KERN-10E. Complete the following helper function.
// Test whether `test_pid` is the PID of a thread in the same process as `p`.
// Return 1 if it is; return 0 if `test_pid` is an illegal PID, it corresponds to
// a freed process, or it corresponds to a thread in a different process.
intis_thread_in(pid_t test_pid, proc* p) {
QUESTION KERN-10F. Complete the case for SYSCALL_JOIN_THREAD
in syscall(). Remember that a thread may be successfully joined at
most once: after it is joined, its PID is made available for
reallocation.
Note that we can’t distinguish a –1 return value from error from a –1
return value from sys_exit_thread(-1).
QUESTION KERN-10G. In pthreads, a thread can exit by returning from
its thread function; the return value is used as an exit value. So far,
that’s not true in Weensy threads: a thread returning from its thread
function will execute random code, depending on what random garbage was
stored in its initial stack in the return address position. But Betsy
thinks she can implement pthread-style behavior entirely at user level,
with two changes:
She’ll write a two-instruction function called
thread_exit_vector.
Her create_thread library function will write a single 8-byte
value to the thread’s new stack before calling
sys_create_thread.
Explain how this will work. What instructions will
thread_exit_vector contain? What 8-byte value will
create_thread write to the thread’s new stack? And where will that
value be written relative to sys_create_thread’s stack_top
argument?
The 8-byte value will equal the address of thread_exit_vector, and
it will be placed in the return address slot of the thread’s new stack.
So it will be written starting at address stack_top.
KERN-11. Virtual memory cache
x86-64 processors maintain a cache of page table entries called the TLB
(translation lookaside buffer). This cache maps virtual page addresses to
the corresponding page table entries in the current page table.
TLB lookup ignores page offset: two virtual addresses with the same L1–L4
page indexes use the same TLB entry.
QUESTION KERN-11A. A typical x86-64 TLB has 64 distinct entries. How many
virtual addresses are covered by the entries in a full TLB? (You can use
hexadecimal or exponential notation.)
212 * 64 = 218
4pts
QUESTION KERN-11B. What should happen to the TLB when the processor executes an
lcr3 instruction?
It should be emptied because the current page table changed.
4pts
QUESTION KERN-11C. Multi-level page table designs can naturally support multiple
sizes of physical page. Which of the following is the most sensible set of
sizes for x86-64 physical pages (in bytes)? Explain briefly.
212, 214, 216
212, 224, 236
212, 221, 230
212, 239
3. These sizes match up to levels in the page table.
4pts; need to read text—3 points possible for #1 (reasoning: fragmentation)
QUESTION KERN-11D. In a system with multiple physical page sizes, which factors
are reasons to prefer allocating process memory using small pages? List all
that apply.
TLB hit rate.
Page table size (number of page table pages).
Page table depth (number of levels).
Memory fragmentation.
None of the above.
4
4pts
KERN-12. Page tables
QUESTION KERN-12A. How big is an x86-64 page?
4096 bytes (or 212 bytes).
QUESTION KERN-12B. How many page table entries are there in an x86-64 page?
512: the size of the page divided by the size of the entry, which is 8.
QUESTION KERN-12C. How many bytes of virtual address space are accessible starting
at level-3 page table page in x86-64?
Also accepted 230 (off-by-one error in counting to the L3 page table).
QUESTION KERN-12D. Describe contents of x86-64 physical memory that would ensure
virtual addresses 0x100ff3 through 0x1011f3 map to a contiguous range of 512
physical addresses 0x9'9999'9ff3 through 0x9'9999'a1f3. We’ve given you the
contents of 2 words of physical memory; you should list more. Assume and/or
recall:
This problem concerns a new system call, urgent, with the following
specification.
int urgent(pid_t p, long v)
If p != 0, then p must be the process ID of a running process. That process
is placed into urgent mode with value v. All future system calls by p,
except for sys_urgent, will return immediately with return value v, rather
than performing as normal. If the process is currently blocked in a system call,
then it is unblocked and the system call returns v.
If p == 0, then the current process is taken out of urgent mode.
Returns 0 on success, -1 on failure. Failure occurs if p != 0 and p is not the ID of a running process.
The urgent system call in some ways resembles kill, which causes signals,
in that it allows one process to disrupt the normal execution of another.
However, urgent only disrupts the operation of system calls—it does not
interrupt normal process computation.
QUESTION KERN-13A. Process isolation: list all that apply; explain briefly if unsure.
The urgent system call violates process isolation because any process can
disrupt the execution of any other process, without regard to parent–child
relationships or user privileges.
The urgent system call violates process isolation because it can allow a
process to gain control of the kernel, which runs with process ID 1.
The urgent system call does not violate process isolation because
operating system policy defines exactly what process isolation means.
The urgent system call is likely to make it much harder to build robust
software.
None of the above.
#4 is absolutely true: urgent allows one process to totally confuse
another, and it is impossible to program robustly in the presence of
urgent.
Of the others, #2 is false—the kernel does not run with process ID 1.
Between #1 and #3, there are arguments on both sides, but the best answer is
#3. Operating system policy does define process isolation; if an OS wants
urgent, that by definition does not violate isolation, in the same way
that root privilege on Unix does not violate isolation.
QUESTION KERN-13B. The timed-wait example from lecture aimed to write a program
that exited after a 0.75 second timeout, or its child process exited,
whichever came first. Many attempts were subject to a race condition,
including the following:
voidsignal_handler(int signal) {
(void) signal;
}
intmain() {
int r = set_signal_handler(SIGCHLD, signal_handler);
pid_t p1 = fork();
if (p1 ==0) {
... do something ...
}
r = usleep(750000); // will be interrupted if SIGCHLD occurs
(void) r;
}
What best describes the race condition? List all that apply.
The race condition can occur when the child exits before usleep begins.
The race condition can occur when the child exits after usleep completes.
The race condition can occur if set_signal_handler does not install the
signal handler before the child runs.
The race condition can occur if the kernel neglects to send the process a
SIGCHLD signal when the child exits.
None of the above.
#1 is the best answer. #2 does not cause a race condition. #3 and #4 are
impossible situations unless we assume some insane kernel bugs.
QUESTION KERN-13C. Describe how to modify the timed-wait example code from part
B to avoid the race condition using urgent. Either write code or explain
briefly. Make sure you include a call to urgent(0, 0) so that the parent
process can exit!
The signal handler should call urgent(getpid(), -100) or something. This
will cause the usleep to unblock. Since urgent mode is persistent,
usleep will not block at all, even if the signal is delivered before
usleep! Then, after usleep returns, call urgent(0, 0).
Also accepted solutions that put urgent(getppid(), v) at the very end
of the child's code (i.e., right before its exit).
QUESTION KERN-13D. Describe how to modify the WeensyOS kernel to support
sys_urgent. You will want to refer to your WeensyOS code, and change at
least 3 locations marked below. (WeensyOS has no blocking system calls so
don’t worry about urgent’s unblocking behavior.)
// Process descriptor type
structproc {
x86_64_pagetable* pagetable; // process's page table
pid_t pid; // process ID
int state; // process state (P_RUNNABLE, P_FREE, etc.)
regstate regs; // process's current registers
// (1) Your code here
};
extern proc ptable[NPROC];
uintptr_t syscall(regstate* regs) {
// Copy the saved registers into the `current` process descriptor.
current->regs =*regs;
regs =¤t->regs;
console_show_cursor(cursorpos);
memshow();
check_keyboard();
if (regs->reg_rax == SYSCALL_URGENT) {
// (2) Your code here to handle the `sys_urgent` system call
}
// (3) Your code here to check for and handle urgent mode
// Normal system calls
switch (regs->reg_rax) { ...