Our Embedded EthiCS module touches on data representation—specifically the representation of human language in terms computers can understand. This is an ethically rich and complicated area where technical innovations have had huge impact.
Written coding systems
Human language originates in speech,1 and we assume that for most of human history languages were exclusively spoken.2 Language communication in forms other than speech requires a coding system: a representation of speech (or sign) in a form suitable for another technology.
There are many coding systems, and it’s easy to create one—children do so for fun! (Did you ever make up a secret alphabet, or a code for passing notes in school?)—but important coding systems are culturally standardized and mutually intelligible among many people.
Any written language is a coding system. You’re using a coding system right now, namely the English language, as represented in the Latin alphabet, as mediated by a computer coding system that represents letters as integers. Written coding systems divide into three broad categories:
-
In alphabetic coding systems, a mark represents a part of a sound. Latin is an alphabetic script: a Latin letter can represent a vowel (“a”) or consonant (“b”), but sometimes a sequence of letters represents a single sound (“ch”). Other alphabets include Cyrillic, Coptic, Korean (Hangul), Hebrew, Arabaic, and Devanagari.3
-
In syllabic coding systems, a mark represents a full syllable—a sequence of related sounds. The most-used syllabaries today are in use in Japan.
-
In logographic coding systems, a mark represents a larger concept, such as a full word. The Chinese script is the only broadly-used logographic writing system, but it is very broadly used.
Actual written languages can combine features of all these systems. The Japanese language is written using a combination of four distinct scripts: kanji (logographic Chinese characters), hiragana (a syllabary used for native Japanese words), katakana (a syllabary used mostly for emphasis, for foreign words, and for words representing sounds), and alphabetic Latin script (for instance, for numerals4 and some foreign borrowings, like Tシャツ “T-shirt”).
Users of a coding system or script learn to identify many visually-distinct symbols as the same fundamental symbol. We call that symbol a character. For instance, this, this, this, this, this, and this all appear to Latin-script readers as the same character sequence—‘t h i s’—even though the pixel patterns differ. Some scripts have greater differences between character symbols and their visual expressions. For instance, Arabic letters connect into very different visual forms when combined: the characters ا ل ع ر ب ي ة are written together as العربية, but fluent readers of Arabic script would describe that word as equivalent to its letter components. It is useful to distinguish the underlying character content of a text—the sequence of characters—from the visual presentation of those characters, which might vary depending on context (nearby characters) or preference (color, size, typeface).
Different writing systems have radically different numbers of characters.
- The modern Greek alphabet has 24 letters or 48 characters (if you distinguish upper and lower case).
- The Latin alphabet as used in English requires 52 characters.
- Many coding systems use expanded or contracted Latin
alphabets.
Many of the additional letters in expanded alphabets feature diacritics or
accent marks added to letters in use in English, but some letters are
independent. For instance:
- Classical Latin requires 23 characters (no lower case and no J U W).
- Vietnamese uses 58 characters, adding Ăă Đđ Êê Ôô Ơơ Ưư and dropping Ff Jj Ww Zz (except for foreign words).
- Icelandic uses 64 characters: it includes Ðð and Þþ (which are derived from ancient runic alphabets), accented letters Áá Éé Íí Óó Úú Ýý Öö, and Ææ, but drops Cc Qq Ww Zz (except for foreign words).
- Turkish uses 58 characters: it adds accented letters Çç Ğğ Öö Şş Üü; distinguishes two different forms of Ii, a dotted form and an undotted form, leading to the pairs Iı and İi; and drops Qq Ww Zz (except for foreign words).
- The Arabic alphabet has 28 letters when used for Arabic; coding systems for other languages add up to 36 more.
- The hiragana and katakana syllabaries have 48 characters each.
- Recent dictionaries of Chinese characters list more than 50,000 characters; some list as many as 100,000.
QUESTION. What is the smallest x86-64 integer type that could represent every character in the Latin alphabet as a distinct bit pattern?
QUESTION. What is the smallest x86-64 integer type that could represent every character in all the coding systems listed above as a distinct bit pattern?
DISCUSSION QUESTIONS. What are some advantages of representing characters with small types? Conversely, what are some advantages of representing characters using large types?
Early computer coding systems
Coding systems, having already been standardized and simplified, are particularly suitable for translation into other forms, such as computer storage. So: How should a computer represent characters? Or—even more concretely, since computers represent data as sequences of bytes, which are numbers between 0 and 255—which byte sequences should correspond to which characters? This question may seem easy, or even irrelevant (who cares? just pick something!), but different choices can have important consequences for storage costs as well as the ability to represent different languages.
The earliest computer coding systems arose when computer storage was extremely expensive, slow, and scarce. Since computers were mainly used for mathematical computations and data tabulation, their users placed heavy weight on the space required to represent characters (which directly affected cost) and less weight on supporting a wide range of applications. Coding system designers aimed for parsimony, or minimal size for encoded data. Each coding system was designed for a specific application, and extremely parsimonious representations are possible when the data being represented comes from a restricted domain. The resulting systems, though well-suited for the technologies of the time, have limited expressiveness.
For example, this is the 40-character Binary-Coded Decimal Interchange Code, or BCDIC, introduced by IBM in 1928 (!) for punchcard systems, which were electro-mechanical computers. The BCDIC code is actually based on a code developed in the late 1880s for the 1890 US Census; Herman Hollerith, the inventor of the census machine, founded a company that eventually became IBM.
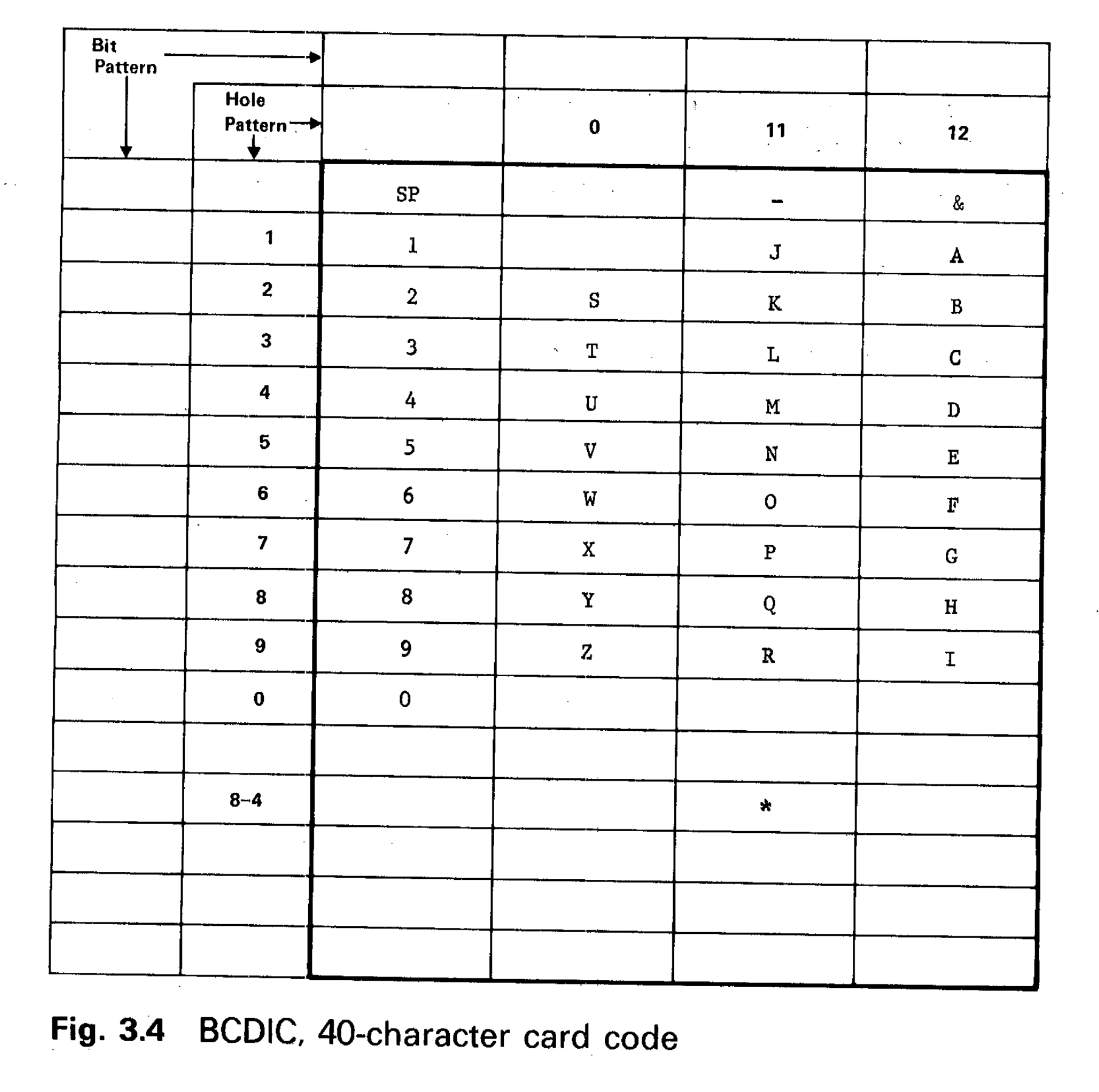
The BCDIC code has a couple interesting features. Lower-case letters cannot be
represented; letters are not represented in order; and the only representable
punctuation marks are - and &. Though sufficient for the 1890 Census, this
encoding can’t even represent this simple sentence, which features an
apostrophe, commas, and an exclamation point, as well as lower case letters!
Compare BCDIC to this coding system, CCITT (Comité Consultatif International Téléphonique et Télégraphique) International Telegraph Alphabet No. 2, an international standard for telegraph communication introduced in 1924:
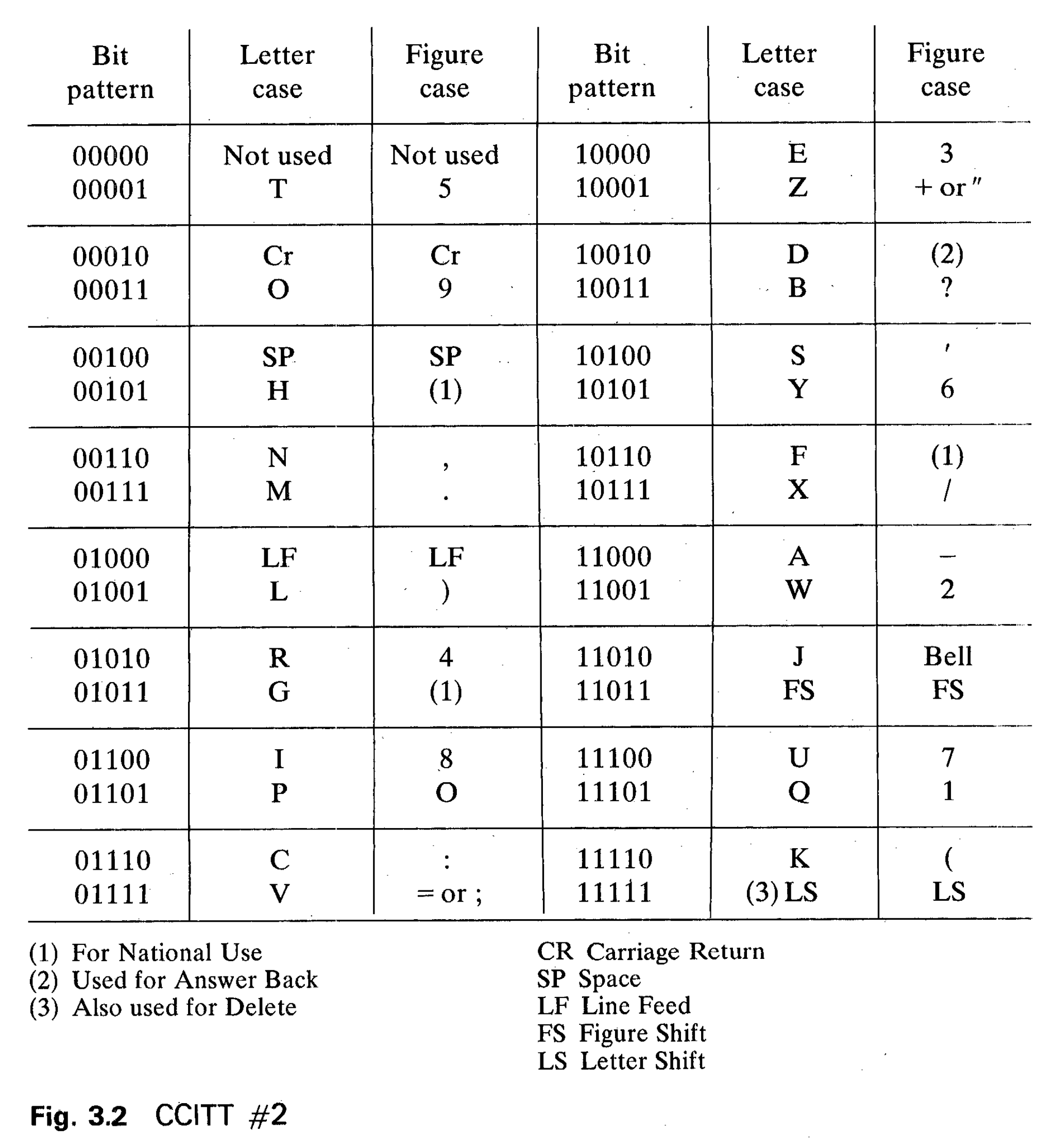
Telegraphs were designed to communicate human-language messages rather than census data, so it makes sense that ITA2 supports a greater range of punctuation. Letters are not coded in alphabetical order, but there is an underlying design: common letters in English text are represented using fewer 1-valued bits. E and T (the most common letters in English text) are represented as 10000 00001, while X and Q (rare letters) are represented as 10111 11101. Some telegraph machinery represented 1-valued bits as holes punched in paper tape, so the fewer 1 bits transmitted, the less mechanical wear and tear!
ITA2 manages to represent 58 characters using a 5-bit code with only 32 bit patterns. This is possible thanks to a complex shift system, where bit patterns have different meaning depending on context. For instance, 01010 might mean either R or 4. A telegraph encoder or decoder is in one of two shift modes, letter shift or figure shift, at any moment. A message always begins in letter shift, so at the beginning of a message 01010 means R. Thereafter, the bit pattern 11011 switches to figure shift, after which 01010 means 4. 11111 switches back to letter shift.
Shift-based coding systems cleverly pack many characters into a small range of bit patterns, but they have two important disadvantages. First, the shift characters themselves take up space. A text that frequently switches between letters and numbers may take more space to represent in ITA2 than it would in a 6-bit code, because every switch requires a shift character. More critically, though, transmission errors in shift-based coding systems can have catastrophic effects. Say a bird poops on a telegraph wire, causing one bit to flip in a long message. In a direct coding system with no shifts, this bit-flip will corrupt at most one character. However, in a shift-based coding system, the bit-flip might change the meanings of all future symbols. For instance:
11111 00101 10000 01001 00011 00100 10110 01010 01100 10000 00110 10010= HELLO FRIEND11011 00101 10000 01001 00011 00100 10110 01010 01100 10000 00110 10010= £3))9 !483,#
More complex shift-based systems tend to have even worse failure modes.
ASCII, ISO, and national standards
As computer technology improved, cheaper storage technologies became available, and general-purpose computing came into sight, the disadvantages of proliferating context-specific coding systems became more apparent. How should a given bit pattern be interpreted? According to ITA2 telegraphy rules or BCDIC electromechanical computing rules? There was no ambiguity for bit patterns on a proprietary telegraph wire owned by Western Union (the answer was ITA2), but for bit patterns stored on a general-purpose computer, ambiguity causes real problems. A wave of coding systems was developed to avoid these ambiguities. But it was still early days, and these standardization efforts were limited to single linguistic cultures.
The American Standard Code for Information Interchange, which is the core of the text encodings we use now, was developed in 1961–1963. It looks like this:
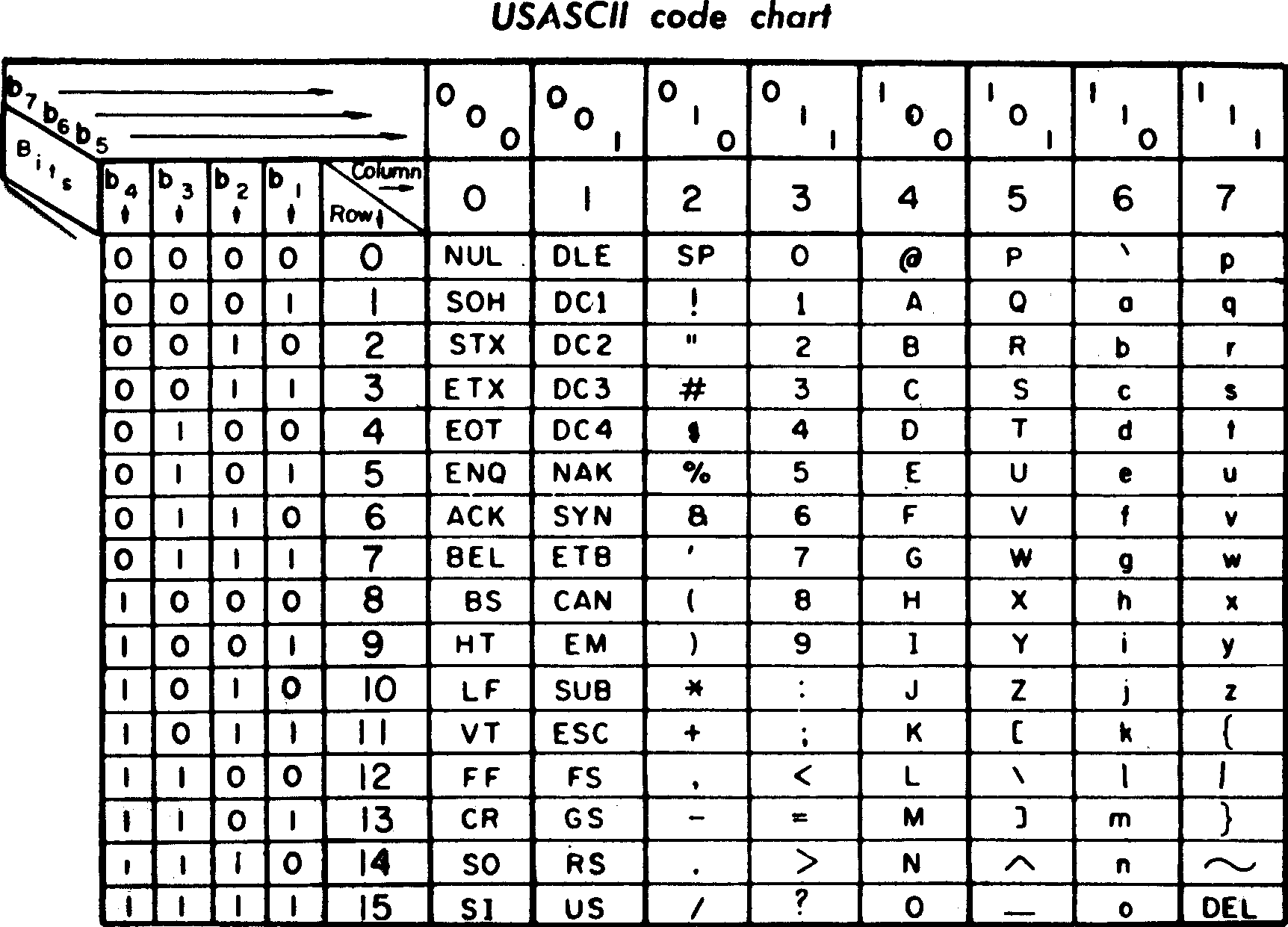
ASCII supports lower case letters and punctuation without any shift system. There’s space for all those characters because ASCII is a 7-bit encoding with 128 bit patterns. It might seem amazing now, but this caused some controversy; the committee designing the standard apparently deadlocked for months before it agreed to go beyond 5 bits:

ASCII, an American standard, was adopted by ISO, the International Standards
Organization, as ISO/IEC 646.
However, ISO is an explicitly international organization (albeit one
headquartered in Switzerland and, especially early on, Eurocentric). It had to
consider the needs of many countries, not just English-speaking America; and
ASCII had no space for letters outside the basic Latin alphabet.
ISO’s solution was to reserve many of the ASCII punctuation characters for
national use. Different variants of ISO/IEC 646 could reassign those code points.
Specifically, the code points for
#$@[\]^`{|}~ could represent other symbols.5 For example, 0x23 meant
# in America and £ in Britain. One Dutch standard used 0x40, 0x5B, and
0x5C for ¾ ij ½, not @[\. The first French variant encoded à ç é ù è in the
positions for @\{|}, but did not encode uppercase versions or other
accented letters. Swedish encoded ÉÄÖÅÜéäöåü in preference to @[\]^`{|}~.
The resulting coding systems facilitated communication within national borders and linguistic systems, but still caused problems for communication across borders or linguistic systems. A given bit pattern would be displayed in very different ways depending on country. Humans were able to adapt, but painfully. For example, this C code:
{ a[i] = '\n'; }
would show up like this on a Swedish terminal:
ä aÄiÜ = 'Ön'; ü
Some Swedish programmers learned to read and write C code in that format! Alternately, programmers might set their terminal to American mode—but then then their native language looked weird: “What’s up?” might appear as “Hur {r l{get?” The authors of the C standard tried to introduce an alternate punctuation format that didn’t rely on reserved characters, but everyone hated it; this just sucks:
??< a??(i??) = '??/n'; ??>
Meanwhile, other cultures with language coding systems not based on the Latin alphabet developed their own coding systems, totally unrelated to ASCII, in which bit patterns used for Latin letters in ASCII might represent characters from Japanese syllabaries, or even shift commands. Such a file would look like gibberish on an American computer, and American files would look like gibberish on those computers.
ISO/IEC 8859
With increasing international data communication and cheaper computer storage, the ambiguity and misinterpretation caused by national character set standards grew more painful and less justifiable. It was clear what to do: add another bit and eliminate the national character sets. The ISO 8859 standards represent up to 256 characters, not 128, using 8-bit codes. In each ISO 8859 coding system, code points 0x00–0x7F (0–127) are encoded according to ASCII. Here are the meanings of code points 0x80–0xFF in ISO-8859-1:
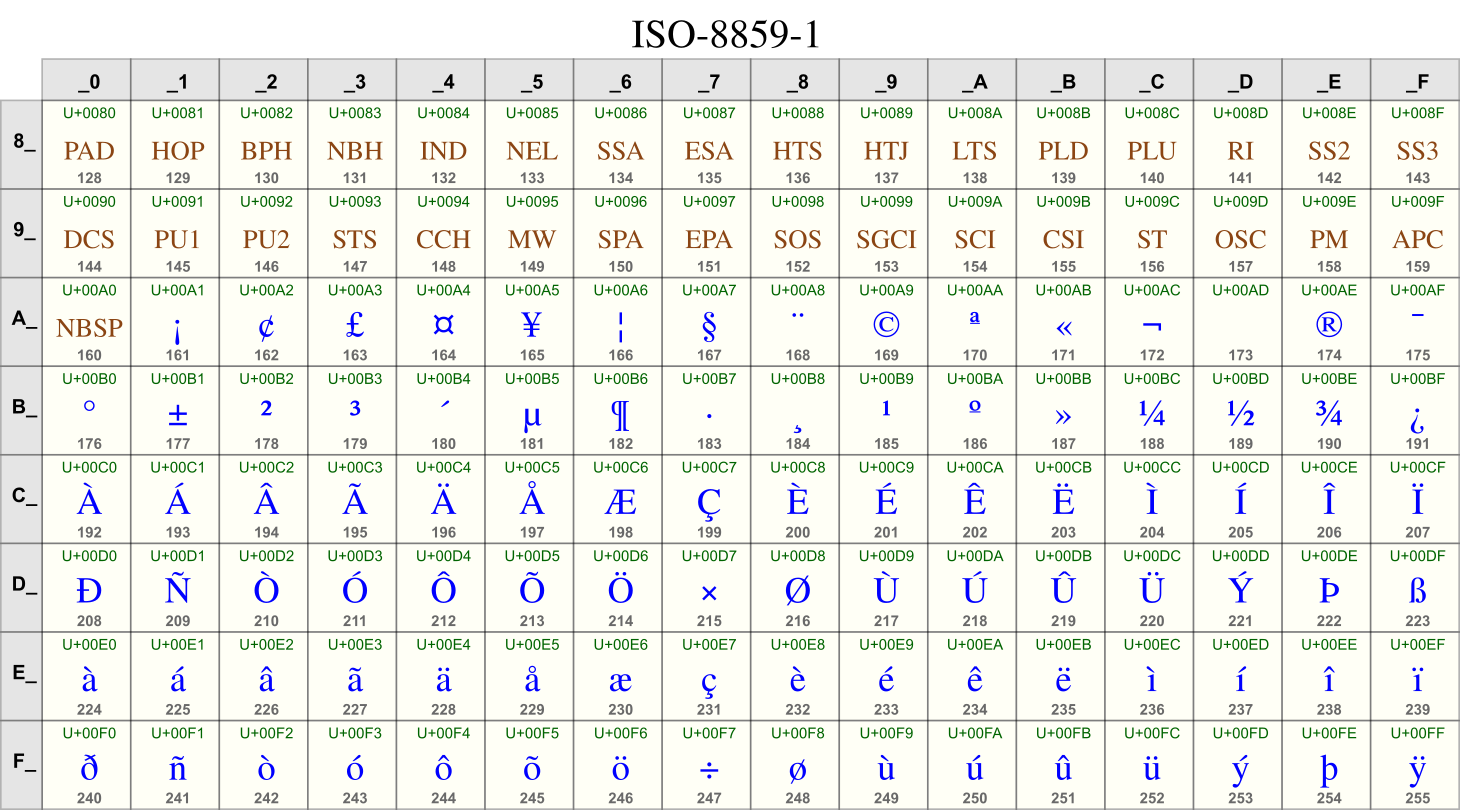
Finally Swedish programmers could ask what’s up and program C on the same terminal! ISO 8859-1 includes code points for all of ÉéÄäÖöÅåÜü@[\]^`{|}~.
But ISO 8859 was at best a stopgap. A single 8-bit coding system can support more languages than a 7-bit system, but not many more, and computer data remained ambiguous. ISO 8859-1, the most common version of ISO 8859, supports Western European languages, but not Central or Eastern European languages (for example, it lacks Hungarian’s ŐőŰű), let alone Greek or Cyrillic. Some of the encoding choices in ISO 8859 may seem strange to us, or at least governed by concerns other than the number of readers of a language. ISO 8859-1 includes the six characters ÝýÐðÞþ because they are required to support Icelandic, which has 360,000 speakers. Perhaps it would have been more useful to include the six additional characters required to support Turkish (ĞğŞşıİ), which has 88,000,000 speakers? Why was geographic proximity (“Western Europe”) more important for ISO 8859 than number of readers? And if geographic proximity was important, why were some Western European languages left out (Welsh, Catalan, parts of Finnish)?
Unicode
In the 1980s, some employees of Xerox and Apple got together to discuss a better way forward: a single encoding that could support all human languages using one code point per character (no external metadata to define the context for a bit pattern; no shifts). This effort eventually became Unicode, the current universal standard for character encoding.
The initial Unicode standard encoded all characters, including Chinese logographs, in a 16-bit coding system with two bytes per character. The attentive reader may note that this seems too small: a current Chinese dictionary lists more than 100,000 characters, while a 16-bit coding system has 65,536 code points available for all languages. The solution was a process called Han unification, in which all characters encoded in East Asian national standards were combined into a single set with no duplicates and certain “uncommon” characters were left out.6
Han unification was quite controversial when Unicode was young. People didn’t like the idea of American computer manufacturers developing a worldwide standard, especially after those manufacturers had downplayed the needs of other writing systems. Conspiracy theories and ad hominem arguments flew. Here’s an anti-Unicode argument:
I did not attend the meetings in which ISO 10646 was slowly turned into a de facto American industrial standard. I have read that the first person to broach the subject of "unifying" Chinese characters was a Canadian with links to the Unicode project. I have also read that the people looking out for Japan's interests are from a software house that produces word processors, Justsystem Corp. Most shockingly, I have read that the unification of Chinese characters is being conducted on the basis of the Chinese characters used in China, and that the organization pushing this project forward is a private company, not representatives of the Chinese government. … However, basic logic dictates that China should not be setting character standards for Japan, nor should Japan be setting character standards for China. Each country and/or region should have the right to set its own standard, and that standard should be drawn up by a non-commercial entity. (reference)
And a pro-Unicode argument:
Have these people no shame?
This is what happens when a computing tradition that has never been able to move off ground-zero in associating 1 character to 1 glyph keeps grinding through the endless lists of variants, mistakes, rare, obsolete, nonce, idiosyncratic, and novel ideographs available through the millenia in East Asia. (reference)
In the West, however, anti-Unicode arguments tended to focus on space and transmission costs. Computer storage is organized in terms of 8-bit bytes, so the shift from ASCII to ISO 8859—from 7- to 8-bit encodings—did not actually affect the amount of storage required to represent a text. But the shift from ISO 8859 to Unicode was quite impactful. Any text representable in ISO 8859 doubled in size when translated to Unicode 1, which used a fixed-width 16-bit encoding for characters. When Western users upgraded to a computer system based on Unicode—such as Windows 2000 and successors, Java environments, and macOS—half the memory previously used for meaningful characters was given over to zero bytes required by Unicode’s UCS-2 representation.
Meanwhile, Unicode itself grew. The original 65,536-character code set didn’t have enough room to encode historic scripts, such as Egyptian hieroglyphs. More relevantly for living people, the Han unification process had been based on a misunderstanding about rarely-used Chinese characters: some rarely-used characters were truly obsolete, but others remained in use in proper names, and thus were critically important for particular people. It is not good if a supposedly-universal character encoding standard makes it impossible to write one’s name! It became clear that 65,536 characters would not suffice to express all human languages, and in 1996 Unicode 2.0 expanded the number of expressible code points by roughly 17x to 1,112,064. The most recent Unicode standard defines meanings for 144,697 of these 1.1M code points, including a wide range of rare and historic languages, mathematical alphabets, symbols, and emoji.
Summing up
All of this leaves us with some competing interests.
- The Unicode standard can express almost any human-language text unambiguously as a sequence of code points: hooray!
- However, with 1,112,064 possible code points, the smallest natural type that can represent every Unicode character is a 32-bit integer. When characters are represented as 32-bit units (the so-called UTF-32 or UCS-4 encoding), a Western European text will take four times more bytes to represent in Unicode than in ISO 8859-1.7 This will take four times as much power to transmit and four times as much money to store.
So what is to be done? It’s not obvious: transmission and storage costs are not just economic but environmental. Should Western systems use ISO 8859 by default, resulting in smaller texts and lower costs but problems of representation and ambiguity (e.g., if a user wants to add a single non-ISO-8859 character to a text, the whole text must be converted to Unicode and will quadruple in size)? Or is there some clever data representation that can reduce the cost of representing Unicode without losing its benefits? Stay tuned!
Footnotes
-
Deaf communities use sign languages that do not originate in speech. ↩︎
-
“Behaviorally modern” humans arose around 500,000 years ago; the earliest evidence of written language is around 5,000 years old. ↩︎
-
To be pedantic, Hebrew and Arabic are “abjads”, not alphabets, because marks represent consonants and vowel sounds are implied. Devanagari and other South Asian scripts are “abugidas” because vowel sounds are indicated by accent-like marks on the more-foundational marks for consonants. ↩︎
-
The Latin script uses what are called “Western Arabic” numerals, 0123456789. These numerals are derived from Arabic, and they are used in some countries that use the Arabic script, but in other countries—Iran, Egypt, Afghanistan—“Eastern Arabic” numerals are used: ٠١٢٣٤٥٦٧٨٩ ↩︎
-
Less frequently, the code points for
!":?_—0x21, 0x22, 0x3A, 0x3F, 0x5F—were also reassigned. ↩︎ -
Han unification built on work by librarians and others, including Taiwan’s Chinese Character Code for Information Interchange (CCCII) and the Research Libraries Information Network’s East Asian Character Code (EACC). The work continued through a Joint Research Group, convened by Unicode, with expert members from China, Japan, and Korea (the successor group has experts from Vietnam and Taiwan as well; reference). For an example of how unification works, consider this image from the Unicode standard of character U+43B9. This character is unified from five closely-related characters in five distinct standards—from left to right, these are from mainland China, Hong Kong, Taiwan, Japan, and Korea.
-
Very few systems use this “natural” encoding, though some do. Instead, many systems use an encoding called UTF-16, in which code points above 0xFFFF are expressed as so-called surrogate pairs of code points in the range 0xD800–0xDFFF. This encoding is still shiftless, but it can use up to 4 bytes to represent a character. ↩︎
