The pset for this unit concerns our tiny WeensyOS operating system. Our section concerns x86-64 virtual memory and WeensyOS’s internal interfaces for dealing with virtual memory. It will be easiest to follow if you are familiar with the problem set specification.
The coding exercises in this section use the cs61-sections/kernels1
subdirectory. This version of WeensyOS uses identity mappings; all processes
share the same page table (the kernel page table), but the kernel is isolated.
This resembles the state of your pset 3 after step 1.
What is virtual memory?
Virtual memory is the processor feature that supports process isolation for primary memory (the part of the computer that stores data and has addresses). It allows different processes to have completely different views of memory. For instance, the data stored at address 0x100000 in the two processes might be totally different, even though the addresses are the same.
Virtual memory is a very powerful technique with many possible use cases, and when originally developed it was not used primarily for isolation, but isolation is its most important use case now.
Part A: Page alignment
x86-64 virtual memory is paged, meaning memory is managed in units
of pages—aligned groups of 212 = 4096 bytes. The
mapping data structure implemented by vmiter is therefore called a
page table. A virtual page is a page-aligned sequence of
212 contiguous virtual addresses, and a physical page
is a page-aligned sequence of 212 contiguous physical
addresses.
Paged virtual memory has two features:
- Each virtual page maps arbitrarily to any physical page (or to a fault).
- But within each page, each address maps onto the corresponding physical address in fixed fashion, relative to the page mapping.
Mathematically, a valid x86-64 virtual memory mapping function \mathscr{P} : \textit{VA} \mapsto \textit{PA} from virtual addresses to physical addresses must be piecewise linear on aligned pages (units of 212 bytes). It will meet these requirements:
- \mathscr{P}(p \ll 12) = x \ll 12 for some integer x, and
- \mathscr{P}((p \ll 12) + o) = \mathscr{P}(p \ll 12) + o whenever 0\leq o <2^{12}.
EXERCISE A1. Assume \mathscr{P}_1 is a virtual memory mapping function having:
- \mathscr{P}_1(0) = 0
- \mathscr{P}_1(10) = 10
- \mathscr{P}_1(\text{0x3009}) = \text{0x19009}
Can \mathscr{P}_1 be a valid x86-64 virtual memory mapping function?
EXERCISE A2. Assume \mathscr{P}_2 is a virtual memory mapping function having:
- \mathscr{P}_2(4095) = 8193
- \mathscr{P}_2(4096) = 0
Can \mathscr{P}_2 be a valid x86-64 virtual memory mapping function?
EXERCISE A3. Given this valid x86-64 virtual memory mapping function:
- \mathscr{P}_3(0) = \text{0x1F000}
- \mathscr{P}_3(\text{0x4019}) = \text{0x19}
- \mathscr{P}_3(\text{0x1000FF}) = \text{0x500FF}
write a series of
vmitercalls that add the corresponding mappings with permissionsPTE_P|PTE_Wto a page tablept3. (Remember thatvmiter::maprequires page-aligned addresses.)
EXERCISE A4. Assume \mathscr{P}_4 is a virtual memory mapping function having:
- \mathscr{P}_4(0) = \text{0x1F000}
- \mathscr{P}_4(\text{0x1000}) = \text{0x1F000}
- \mathscr{P}_4(\text{0x2000}) = \text{0x1F000}
Can \mathscr{P}_4 be a valid x86-64 virtual memory mapping function?
EXERCISE A5. Assume that
xis a page-aligned object of sizesz> 0. How many virtual pages does that object overlap?
EXERCISE A6. Assume that
xis a page-aligned object of sizesz> 0. How many physical pages does that object overlap (ignoring faults)?
EXERCISE A7. Assume that
xis a possibly non-page-aligned object of sizesz> 0. How many virtual pages does that object overlap? You may assume thatx’s virtual address isva.
Part B: Examining mappings and permissions
Update your cs61-sections repository and change into the kernels1
subdirectory. Run make run-hello to see the exciting result of the
p-hello.cc program!
vmiter and ptiter are iterators in WeensyOS for processing page tables
(the in-memory structures used by the x86-64 processor to implement virtual
memory). vmiter answers the question “In the context of page table pt,
what does the virtual address va map to in terms of physical address and
permissions?” It also lets you modify mappings, thereby changing a process’s
view of memory. ptiter answers the question “Which physical pages are used
to represent this page table?” This lets you free a page table relatively
easily.
EXERCISE B1. Let’s use
vmiterandlog_printfto log information aboutkernel_pagetable’s mappings for the following virtual addresses:
- The
syscall_entryfunction;- The
kernel_pagetable;- The
p-helloprocess’s entry point,process_main.First log the physical addresses mapped for these virtual addresses immediately before the call to
process_setup. What are they?
EXERCISE B2. Now log the physical addresses immediately after the call to
process_setup. Do the values change? Why or why not? Refer to specific properties ofprocess_setup.
EXERCISE B3. Log the permissions associated with those virtual addresses immediately before the call to
process_setup. What are they? What permissions do they correspond to? (Look for thePTE_constants inx86-64.hto understand the meaning of each permission bit.)
EXERCISE B4. What about these permissions indicate that the kernel appears to implement kernel isolation (in terms of virtual memory access)?
EXERCISE B5. Log the permissions associated with those virtual addresses immediately after the call to
process_setup. Did they change?
Part C: Warped virtual memory
Run make run-bigdata. Boo!
EXERCISE C1. Add one line of virtual memory map manipulation code to
process_startupso that thebigdataprocess printsCS 61 Is Amazing. Don’t changep-bigdata.ccor the contents of physical memory, just change memory mappings.
Make sure you remove your VM manipulation code before moving on to another problem.
Part D: Maze
Virtual memory can feel like you’re in a maze of twisty little passages, all alike. Here’s a game that’s a (very weak) metaphor for paged virtual memory. The point of the game is to show how different starting points—different “page tables”!—can provide very different views of the world.
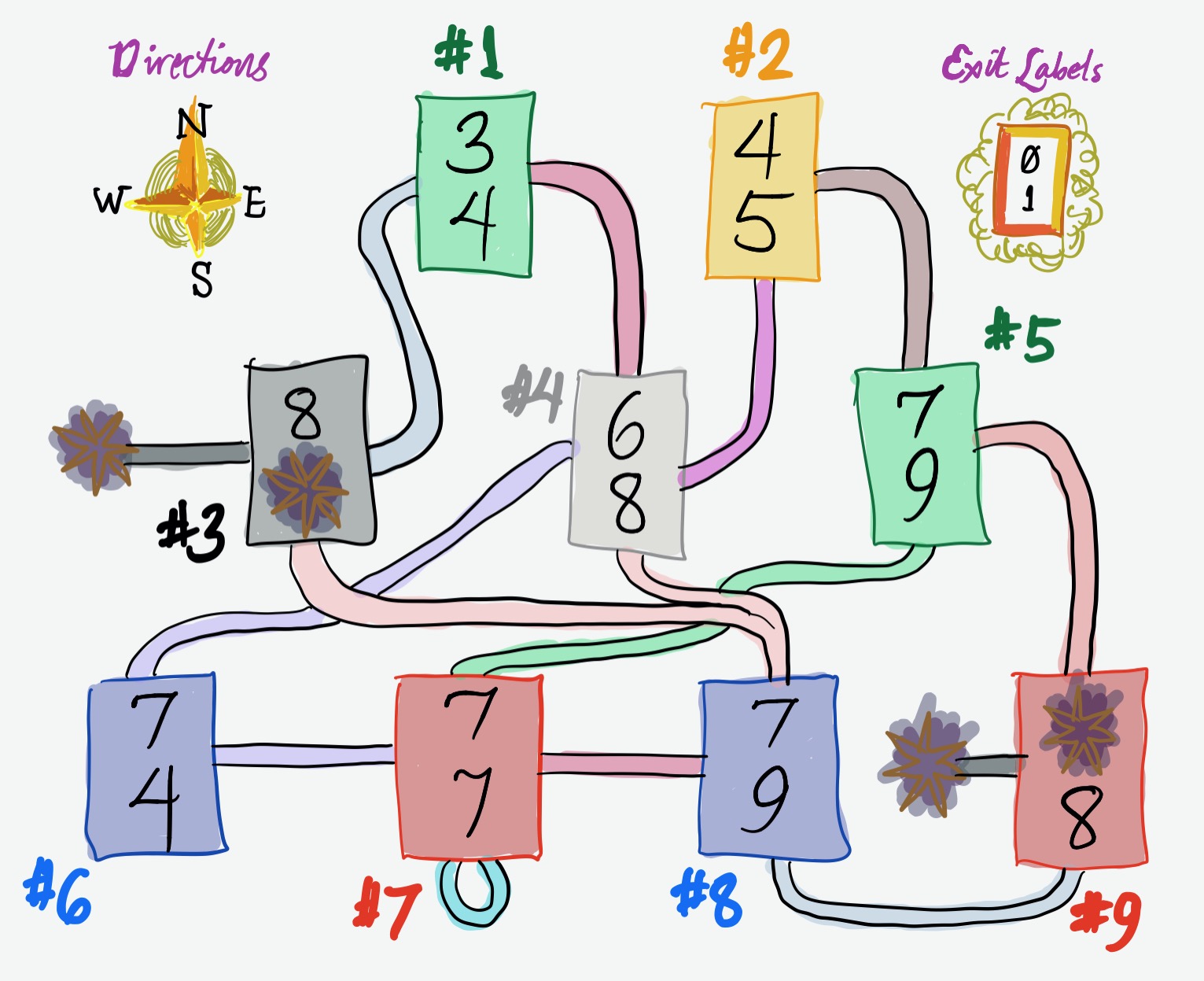
You’ve been teleported into the weird dungeon above and you may only move
according to the rules. You get to pick a starting room (a number from 1
to 9) and a path, which is a bitstring of a given length (for instance,
01). Then you walk through the maze starting from your room by taking the
exits indicated by your bits in sequence:
+-----+
| X | <- exit to take for bit 0
| Y | <- exit to take for bit 1
+-----+
For instance, if you start in room #1 with bitstring 00, you will end up in
room #8. (The 0 exit from #1 leads to #3. The 0 exit from #3 leads to
#8.) There are death pits hanging off #3 and #9.
EXERCISE D1. Give a starting room from which you can reach all blue and red rooms (#6–9) in exactly two steps.
EXERCISE D2. Give a starting room from which you can reach only blue rooms (#6 and #8) and death pits in exactly two steps.
EXERCISE D3. Give the most boring starting room, which is the room from which you can reach the minimum number of other rooms in exactly two steps.
EXERCISE D4. Which rooms cannot be reached in exactly two steps, no matter where you start?
EXERCISE D5. Now you can change the maze by sending out drones. A drone firsts travel two steps according to a bitstring. When it arrives, it re-routes one of that room’s exits to point to another arbitrary room (or a death pit). (This is vaguely like modifying a page table.)
Assume you start in room #9. How many drones would it take for a drone to reach room #1 in exactly two steps? What are those drones’ instructions?
Part E: Using iterators
In the problem set, you will implement fork and exit system calls. At the
center of these system calls are operations on virtual memory that you’ll use
vmiter and ptiter to implement. In section we investigate related problems
for practice.
EXERCISE E1. Use
vmiterto implement the following function.void copy_mappings(x86_64_pagetable* dst, x86_64_pagetable* src) { // Copy all virtual memory mappings from `src` into `dst` // for addresses in the range [0, MEMSIZE_VIRTUAL). // You may assume that `dst` starts out empty (has no mappings), // and that all calls to `vmiter::map` succeed. // After this function completes, for any va with // 0 <= va < MEMSIZE_VIRTUAL, dst and src should map that va // to the same pa with the same permissions. ... }
The fork system call starts up a new process, called the child
process, that is essentially a copy of the parent process (the process
that called fork). The child process has a copy of the parent process’s
memory, as well as its registers and other state. Changes to the child
process’s memory should not be visible in the parent’s memory and vice versa.
EXERCISE E2. Does
copy_mappingssuffice to implement the memory copying required byfork? Why or why not?
EXERCISE E3. Use
vmiterandptiterto implement the following function.void free_everything(x86_64_pagetable* pt) { // Free the following pages by passing their kernel pointers // to `kfree(void*)`: // 1. All memory accessible via unprivileged mappings in `pt` from virtual // addresses in [0,MEMSIZE_VIRTUAL). // 2. All page table pages that are part of `pt`. ... }
The exit system call allows a process to stop executing. All memory
belonging to or representing that process must be returned to the kernel for
reuse. This will include some memory that is accessible only to the kernel,
such as memory storing the process’s page table.
EXERCISE E4. Does
free_everythingsuffice to implement the memory freeing required byexit? Why or why not?
Part F: Spawn
The remaining three part won’t be covered in section by default. They are optional practice to prepare for the problem set or exams. We suggest groups of students get together and work through them on their own.
In the first part, we start a new process in WeensyOS. Starting a new process
requires a couple things: choosing a struct proc member of the ptable
array, initializing memory, initializing registers, and marking the process as
runnable. The fork system call in pset 3 step 5
starts a process by copying an already-running process, but other interfaces
are possible. The spawn interface, for example, starts a new process from
scratch.
EXERCISE F1. The
p-spawn.ccprocess tries to start another process—a copy of thep-aliceprogram—by callingsys_spawn("alice"). Usemake run-spawn(ormake run-console-spawn, etc.) to run this program.
- The system call is not working. How can you tell?
- Complete the system call implementation so that
p-spawn.ccsuccessfully starts a new process.- Modify
p-spawn.ccso that it tries to start two copies ofalice. What happens and why? How could you fix this? Refer to the steps of pset 3.- Does your implementation of
syscall_spawncheck its arguments for validity? If not, how would you change it to do this?
Part G: Confused deputy
A confused deputy attack occurs when a low-privilege attacker convinces a privileged “deputy” to complete an attack on its behalf. In the context of operating systems, a process is unprivileged, while the kernel has full privilege. However, a system call asks the kernel to perform an operation on behalf of a process, making the kernel act as a privileged deputy. A confused deputy attack occurs if the process, by invoking system calls, can somehow convince the kernel to perform a function that violates process isolation.
EXERCISE G1.
p-eve.ccandp-alice.ccmay be familiar from class. Usemake run-friendsto run Alice and Eve together.
- It is possible to change one argument of one system call in
p-eve.ccto execute a successful confused deputy attack that breaks the kernel or otherwise prevents Alice from running. What is the system call? What is the confused deputy attack?- Complete the attack.
- Modify the kernel’s system call checking to prevent the attack. The kernel might kill the Eve process upon detecting the attack, or (better perhaps) return -1 from the relevant system call.
Part H: Efficient communication
The central theme of Unit 3 is isolation and security, but kernels also can offer design features that transform overall system performance.
The p-pipewriter.cc and p-pipereader.cc programs implement a simple form
of communication, mediated by the kernel. The pipewriter program picks a
random message and writes it to a shared “pipe,” which is just a memory buffer
located in the kernel. The pipereader program reads this message by reading
from the pipe.
EXERCISE H1. Use
make run-pipeto run the pipewriter and pipereader together.
- Read the explanations for the
sys_pipereadandsys_pipewritesystem calls inu-lib.hh. What do these system calls remind you of? How do their parameters differ from the parameters to analogous functions in Unix/Linux?- Find the implementations of
SYSCALL_PIPEWRITEandSYSCALL_PIPEREADinkernel.cc. What is the maximum number of bytes these system calls can read or write at a time? How might this be a performance problem?- How many system calls do the writer and reader make per message? Is there a discrepancy? Look at their code; can you explain the discrepancy?
EXERCISE H2. Change the kernel, and only the kernel, to reduce the number of system calls required to transfer a message to the minimum, which is less than five. Here are some techniques you can use:
- Scheduling. When process P is unlikely to be doing useful work, it often makes sense to run a process other than P. The handout kernel does not follow this rule of thumb.
- Batching/buffering. It is more efficient to transfer more than one byte at a time.
- Blocking. When process P cannot make progress until some state changes, it can be more efficient overall to put process P to sleep. This is called blocking process P. For instance, perhaps the
sys_pipereadsystem call might block the calling process until there is at least one byte available to read.