Eliza Wells’s EthiCS slides
Problems with 16- and 32-bit encodings for Unicode
- Expensive relative to 7-bit ASCII or 8-bit ISO 8859
- Ambiguous representation
- Does the byte sequence 0x65 0x00 represent
A (little-endian U+0065) or
攀 (big-endian U+6500)?
- Incompatibility with existing programming languages
- In the C programming language, a null character 0x00 ends a string
- In 16- or 32-bit-encoded Unicode, null characters abound
Desiderata
- Byte-based encoding
- Compatible with ASCII
- Any byte corresponding to ASCII should indicate that character
- Regardless of where it appears
- Resistant to errors
- Relatively efficient
Straw-man solution
- Bytes 0x00–0xFE represent characters U+0000–U+00FE
- If C>0xFE, represent U+C by repeating the byte 0xFF C times
- Example:
0x65 0x69 0x21 0xFFx128,578
- Problem: How to interpret the string
0xFFx1024?
- U+400? U+200 U+200? U+300 U+100?
- Not self-synchronizing (in fact, ambiguous)
Second straw man
- Bytes 0x00–0xFD represent characters U+0000–U+00FD
- If C>0xFD, represent U+C by as
0xFF 0xFExC
Third straw man (surrogate pairs)
- Bytes 0x00-0x7F represent characters U+0000–U+007F
- If C>0x7F, divide C into upper and lower bits
- Let C = 64\times C_1 + C_0, where 0 \leq C_1,C_0 < 64
- Represent U+C as [
0xC0+C1] [0x80+C0]
- So bytes
0xC0–0xFF can only represent the first byte in a two-byte representation
- Bytes
0x80–0xBF can only represent the second byte
Fourth straw man
- Bytes 0x00-0x7F represent characters U+0000–U+007F
- If C>0x7F, divide C into blocks of 64 bits
- C = \sum_{i=0}^{N-1} C_i \times 64^i where 0 \leq C_i < 64
- Represent U+C as [
0xC0+C_{N-1}] [0x80+C_{N-2}] ... [0x80+C_0]
- Bytes 0x00–0x7F represent characters U+0000–U+007F
- For 0x80≤C<0x7FF, use two bytes: [
0xC0–0xDF] [0x80–0xBF]
- Bitwise, 0b100'0000 ≤ C < 0b111'1111'1111
- Let C = 64\times C_1 + C_0 where 0 \leq C_1 < 32 and 0 \leq C_0 < 64
- [
0xC0+C_1] [0x80+C_0]
- For 0x800≤C<0xFFFF, use three bytes: [
0xE0–0xEF] [0x80–0xBF] [0x80–0xBF]
- Let C = 2^{12}\times C_2 + 64\times C_1 + C_0 where 0 \leq C_2 < 16 and 0 \leq C_0, C_1 < 64
- [
0xE0+C_2] [0x80+C_1] [0x80+C_0]
- For 0x10000≤C<0x10FFFF, use four bytes: [
0xF0–0xF7] [0x80–0xBF] [0x80–0xBF] [0x80–0xBF]
- Let C = 2^{18}\times C_3 + 2^{12}\times C_2 + 64\times C_1 + C_0 where 0 \leq C_3 < 8 and 0 \leq C_0, C_1, C_2 < 64
- [
0xF0+C_3] [0x80+C_2] [0x80+C_1] [0x80+C_0]
- Sketched on a placemat in 1992 by Ken Thompson, one of the Unix inventors (citation)
Advantages of UTF-8
- Compatible with existing software and libraries
- Every ASCII file is also a UTF-8 file with the same meaning
- UTF-8 does not use the 0 byte, so existing C library functions continue
to work on UTF-8 strings! (UTF-16 texts contain tons of zero bytes)
- Resistant to errors
- No synchronization issues: an error in one byte affects at most one character
- Contrast the telegraphy system, where an error in a “shift byte” can
affect the interpretation of all future characters
- Relatively efficient
- Unicode code points U+0080–U+07FF can be represented in two bytes
- So texts in European Latin script, African Latin script, Greek script,
Cyrillic script, and most Arabic-script languages take no more space than in UTF-16
- But other scripts may take more space than UTF-16: Brahmic (Indic), Han,
Japanese, Korean
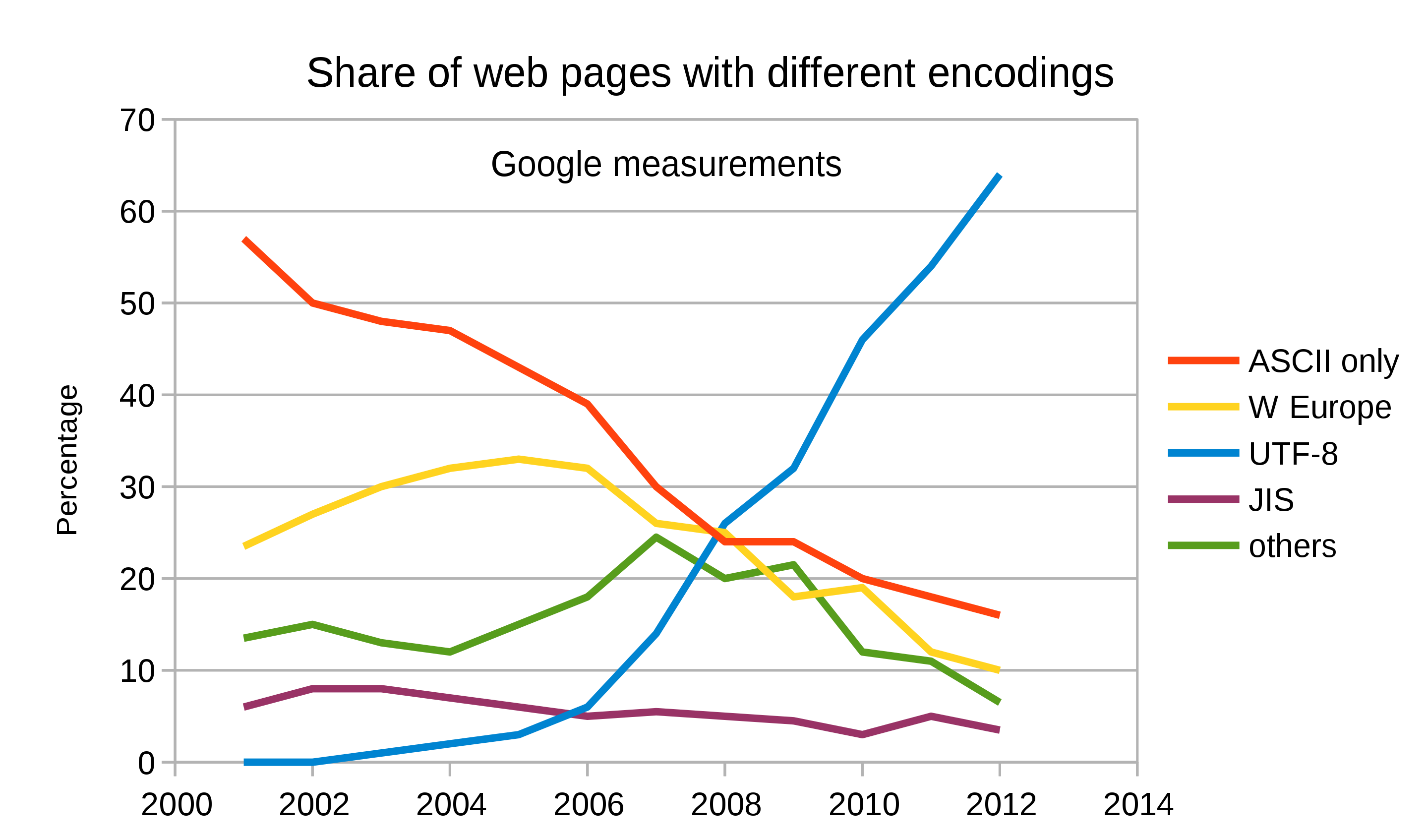
Is UTF-8 good?
- Now over 97% of web pages!
- Increasingly the default in programming languages and operating systems
Reference