Contents
- Introduction
- Literate programming
fork()- Running a new program
- Interprocess communication
- Pipe blocking
- Sieve of Eratosthenes and pipes
- Polling and blocking
- Signals
- Race conditions
- Race condition solutions
"Process control" involves the system calls for creating, managing, and coordinating processes. We’ll focus on a type of program called a shell, which is a program whose purpose is managing other processes. You’re already familiar with shells, because you use them constantly. Now you’ll write one!
“Screwing together programs like garden hose”
One vision of software is that programs grow larger and larger and more and more complicated until every program can do anything. For example, a modern Web browser contains a sophisticated 3D graphics engine and a compiler as well as a complex network layer that communicates with remote servers.
Another vision is that simple programs implement simple tasks, and complex tasks are accomplished by running simple programs in coordination. The operating system should enable this coordination scheme without much hassle. This is the UNIX philosophy. A founding document of this philosophy is the Doug McIlroy memo, in which a manager expresses the desire that “we should have some ways of coupling programs like a garden hose—screw in another segment when it becomes…necessary to massage data in another way.” It is a philosophy of modularity, where programs are divided into self-contained modules with clean interfaces between them. Good modularity makes programs more robust and easier to reuse.
{kind=link}
There are costs and benefits of running multiple small programs instead of a big, complicated program for a certain task.
Costs: In some programming environments, there is a one-time, constant, but very high cost of running any program, regardless of the complexity of the program itself. The Java runtime is such an example, where memory consumption can be high for even very simple programs; coordinating multiple Java programs can be very expensive. In some interpreted languages like Python and JavaScript, running a program may involve starting up the interpreter, which can incur a high cost because interpreters are very complex programs themselves.
Benefits: Different programs run in isolated environments, so an error in a program responsible for a certain task would be self-contained to that program only. This makes it easy to isolate failures in the system. The same program may also be reused for different stages of the task, reducing the code base required to perform the task.
Literate programming
We are going to visit an article, Programming pearls: A literate program, involving Turing Award winner and Stanford professor Donald Ervin Knuth. Prof. Knuth is an incredible researcher; author of The Art of Computer Programming, arguably the most influential books in computer science history; and creator of the TeX typesetting system that underlies LaTeX. He was very good at creating incredibly complex software that also is 100% correct.
Knuth developed a theory of how develop software that he called literate programming. In literate programming, a program is developed alongside a series of small essays that describe the program’s operation. Knuth claimed that literate programming led to better programs. Jon Bentley, who wrote a programming column for the ACM’s flagship magazine, published a column about this idea, and then posed this problem for Knuth to solve in a literate way:
Given a text file and an integer
K, print theKmost common words in the file (and the number of their occurrences) in decreasing frequency.
You can read Knuth’s solution in the article, which involves some rigorous type definitions and a fascinating data structure. In short, it’s very complicated.
Bentley then reached out to Doug McIlroy, author of that memo, for critique and review. McIlroy goes through the program in great detail; he describes the presentation as “engaging and clear,” and compliments Knuth’s creativity. But he also questions the engineering, and speaks up for the UNIX philosophy. This shell script (adapted to modern syntax) solves Knuth’s problem with reasonable performance:
#!/bin/bash
# Call this script as, e.g., “./mostcommonwords.sh 1000 < file”
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
head -n $1
This script spawns six programs and connects them to form a pipeline. The 6 programs run in parallel and consume each others' outputs to perform the described task. Let’s see what it does:
tr -cs A-Za-z '\n': Replace all characters that aren’t letters with newlines, and squeeze out duplicate newlines (that’s the-sflag).tr A-Z a-z: Transforms all upper case letters to lower case.sort: Lexicographically sorts the input by line.uniq -c: De-duplicates input by line (only neighboring duplicate lines are removed). The-coption also puts a duplicate count at the beginning of each line in the output.sort -rn: Numerically sorts the output in reverse order by line.head -n $1: Takes the firstKlines of the input as the final output.
The simplicity of this script is devastating, as is its reliance on reusable tools as opposed to purpose-built, non-reusable functions. The written critique is even more devastating. The UNIX philosophy is powerful!
Read further: Prof. Bentley’s previous column, Programming pearls: Literate programming.
To support this style of coordinated task solving with multiple programs, we need a program whose purpose is controlling and managing multiple independent programs. A shell acts as such a manager. It uses system calls to perform these process coordination tasks; we’ll discuss these tasks one at a time.
Process creation with fork()
A new process can be created via invocation of the fork() system call.
fork() essentially clones the current process. Its signature is
pid_t fork();
where pid_t is a synonym for int. The fork() operation
returns twice with two different values, once in the parent process
and once in the child process. Specifically, if pid_t p = fork(),
then:
- If
fork()succeeds, then in the parent process,p > 0andpequals the child process’s ID. - If
fork()succeeds, then in the child process,p == 0. - If
fork()fails, then in the parent process,p < 0and the error code is stored inerrno. Note that iffork()fails, there is no child.
A process can obtain its own ID by calling the getpid() system call,
and any process can obtain its parent process’s ID by calling the
getppid() system call.
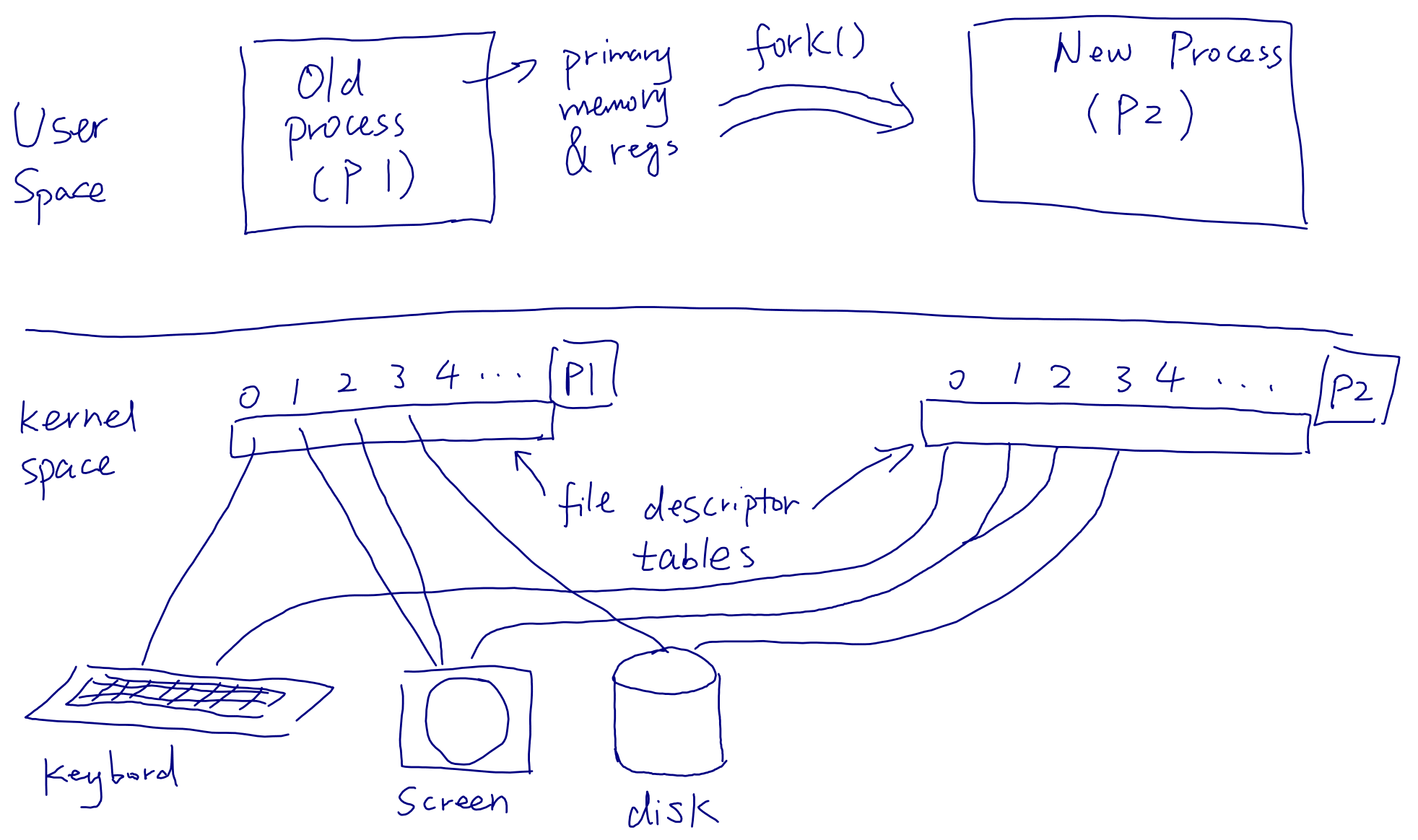
But fork() does not clone everything. In metaphorical terms, fork() copies
the parent’s internal state, but not the external world. In technical terms,
fork() copies the parent process’s registers, primary memory, and internal
per-process operating system structures, such as its file descriptor table;
but it does not copy the structures corresponding to hardware devices, such
as files or the terminal. Instead, those hardware-like structures are shared
between the parent and the child. So:
- The new process has a copy of the old process’s memory state (primary memory and registers).
- The new process and the old process share other hardware devices (which are represented by file descriptors).
Let’s consider the following program:
int main() {
pid_t p1 = fork();
assert(p1 >= 0);
printf("Hello from pid %d\n", getpid());
}
This will print two messages, one from the parent and one from the
child. These two messages might appear in either order. The Linux
kernel might run the parent process first (which we can tell by
noting that the line with the numerically-lower process ID appears
first), but that’s not a guarantee: once fork() returns, there are
two isolated process, and the OS can decide to run them in any order.
Also, both messages appear on the terminal (the console). The fork()
does not create a new terminal! Instead, the terminal is shared between
the two processes. Running this program might give outputs like this:
Hello from pid 35931
Hello from pid 35932
However, if we run the program multiple times, sometimes we also see the following outputs:
Hello from pid 35933
user@ubuntu$ Hello from pid 35934
In this case a shell prompt gets printed before the child gets to print out its message. This indicates that the shell only waits for the parent to finish before printing out a prompt and therefore can accept new commands. When a shell "waits" for a process (like the parent, in this case) in this way, we call that the process executes in the foreground within the shell.
Here is fork2.cc:
int main() {
pid_t p1 = fork();
assert(p1 >= 0);
pid_t p2 = fork();
assert(p2 >= 0);
printf("Hello from pid %d\n", getpid());
}
Running this program might produce output like this:
Hello from pid 73285
Hello from pid 73286
Hello from pid 73288
user@ubuntu$ Hello from pid 73287
We have 4 processes running in this case, and the shell again only waits for the parent to finish. We can visualize it like:
1st fork()
/ \
(p1!=0) (p1==0)
| |
2nd fork() 2nd fork()
/ \ / \
(p2!=0) (p2==0) (p2!=0) (p2==0)
| | | |
parent child2 child1 grand child
Or we can draw a process hierarchy diagram (shown on the board during lecture):
(proc0)
/ \
/ \
1st fork 2nd fork
/ \
/ \
(proc1) (proc2)
/
/
2nd fork
/
/
(proc3)
proc0: parent
proc1: child1
proc2: child2
proc3: grand child
Let’s take a look at another program in forkmix-syscall.cc:
#include <cstring>
#include <unistd.h>
int main() {
pid_t p1 = fork();
assert(p1 >= 0);
const char* test;
if (p1 == 0) {
text = "BABY\n";
} else {
text = "mama\n";
}
for (int i = 0; i != 1000000; ++i) {
ssize_t s = write(STDOUT_FILENO, text, strlen(text));
assert(s == (ssize_t) strlen(text));
}
}
Running the program prints out interleaving lines of BABY and mama to the
screen. Sometimes the interleaving is perfect (we see exactly one BABY
followed by exactly one mama, and so on), sometimes we see consecutive
printouts of BABY or mama. It does seem that every line is either BABY
or mama.
We can verify this using the shell knowledge we just learned. Running
./forkmix-syscall | sort | uniq
generates exactly 2 lines (BABY and mama), so our assumption seems
correct. It is guaranteed that every line is either BABY or mama. This is
because of the atomicity guarantee of the write() system call.
System call atomicity. Unix file system system calls, such as
readandwrite, should have atomic effect. Atomicity is a correctness property that concerns concurrency—the behavior of a system when multiple computations are happening at the same time. (For example, multiple programs have the file open at the same time.)An operation is atomic, or has atomic effect, if it always behaves as if it executes without interruption, as if at one indivisible moment in time, with no other operation happening. Atomicity is good because it makes it easier to reason about complex behavior and prove correctness.
The standards that govern Unix say
reads andwrites should have atomic effect. It is the operating system kernel’s job to ensure this atomic effect, perhaps by preventing different programs from read or writing to the same file at the same time.Unfortunately, experiment shows that on Linux many
writesystem calls do not have atomic effect, meaning Linux has bugs. Butwrites made in “append mode” (open(… O_APPEND)orfopen(…, "a")) do have atomic effect. In this mode, which is frequently used for log files,writes are always placed at the end of the open file, after all other data.
Let’s now look at a very similar program in forkmix-stdio.cc. The program
is almost identical to forkmix-syscall.cc except that it uses stdio’s
fputs() instead of the write() system call to write out data.
When we run this program, we first observe that it is much faster (because
fewer system calls!). Second, we observe that the output doesn’t look quite
right. When we again run the sort-uniq pipeline against its output, we
get much weirder results like lines with maBABY, mamaBABY, maY, and
so on. So looks like even characters are now interleaved! Why?
Recall that stdio uses a internal user-level cache that’s 4096 bytes large.
Once the cache is filled the whole 4KB block is written using a single system
call, which is atomic. The problem is that the strings we are writing,
"BABY\n" and "mama\n", are actually 5 bytes long. 4096 is not divisible by
5, so at cache line boundaries we can have "left-over" characters that gives
us this behavior. It’s also worth noting here that the two processes here
(parent and child) do not share the same stdio cache, because the cache is
in the process’s own isolated address space.
Now let’s look at our last forkmix program, forkmix-file.cc. Again the program
is similar, except that it now opens a file (all using stdio) and writes to
the file, instead of the screen (stdout).
Note the following few lines in the program:
...
FILE* f = fopen(argv[1], "w");
pid_t p1 = fork();
assert(p1 >= 0);
...
So the program opened the file before calling fork(). This shouldn’t give us
any surprising results compared to forkmix-stdio. But what if we called
fork() before opening the file?
Once we move the fopen() call after the fork, we observe that the output
file now contains only half of the expected number of characters.
The reason for this effect is because when we call fopen() after the
fork(), the parent and the child will get two separate offsets into the same
file (maintained by the kernel). The two processes then essentially race with
each other to fill up the file. The process that writes slower will overwrite
what’s already been written in the file at that offset. Eventually the length
of the file will only be the number of characters written by either process,
because that’s the final value of the two file offset values in both the
parent and the child.
Let’s do a quick exercise to remind us of what fork() does. In particular,
let's examine what parent state is and isn't copied into the child. Take a
look at fork3.cc:
#include <cstdio>
#include <unistd.h>
int main() {
printf("Hello from initial pid %d\n", getpid());
pid_t p1 = fork();
assert(p1 >= 0);
pid_t p2 = fork();
assert(p2 >= 0);
printf("Hello from final pid %d\n", getpid());
}
Question: How many lines of output would you expect to see when you run the program?
Question: How many lines of output would you expect if we run the program
and redirect its output to a file (using ./fork3 > f)?
Running a new program
The UNIX way: fork-and-exec style
There is a family of system calls in UNIX that executes a new program. The system
call we will discuss here is execv(). At some point you may want to use other
system calls in the exec syscall family. You can use man exec to find more
information about them.
The execv system call (and all system calls in the exec family) performs the
following:
- Discard the preexisting content in the current process’s virtual address space
- Begin executing the specified program in the current process
Note that execv does not "spawn" a process. It replaces the executable in the
current process. Therefore it’s common to use execv in conjunction with fork: we
first use fork() to create a child process, and then use execv() to run a
new program inside the child.
Let’s look at the program myecho.cc:
int main(int argc, char* argv[]) {
fprintf(stderr, "Myecho running in pid %d\n", getpid());
for (int i = 0; i != argc; ++i) {
fprintf(stderr, "Arg %d: \"%s\"\n", i, argv[i]);
}
}
It’s a simple program that prints out its pid and content in its argv[].
We will now run this program using the execv() system call. The "launcher"
program where we call execv is in forkmyecho.cc:
int main() {
const char* args[] = {
"./myecho", // argv[0] is the string used to execute the program
"Hello!",
"Myecho should print these",
"arguments.",
nullptr
};
pid_t p = fork();
if (p == 0) {
fprintf(stderr, "About to exec myecho from pid %d\n", getpid());
int r = execv("./myecho", (char**) args);
fprintf(stderr, "Finished execing myecho from pid %d; status %d\n",
getpid(), r);
} else {
fprintf(stderr, "Child pid %d should exec myecho\n", p);
}
}
The goal of the launcher program is to run myecho with the arguments shown
in the args[] array. We need to pass these arguments to the execv system
call. In the child process created by fork() we call execv to run the
myecho program.
execvandexecvpsystem calls take an array of C strings as the second parameter, which are arguments to run the specified program with. Note that everything here is in C: the array is a C array, and the strings are C strings. The array must be terminated by anullptras a C array contains no length information. You will need to set up this data structure yourself (converting from the C++ counterparts provided in the handout code) in the shell problem set.
Running forkecho gives us outputs like the following:
Child pid 78462 should exec myecho
About to exec myecho from pid 78462
user@ubuntu$ Myecho running in pid 78462
Arg 0: "./myecho"
Arg 1: "Hello!"
Arg 2: "Myecho should print these"
Arg 3: "arguments."
We notice that the line "Finished execing myecho from pid..." never gets
printed. The fprintf call printing this message takes place after the
execv system call. If the execv call is successful, the process’s address
space at the time of the call gets blown way so anything after execv won’t
execute at all. Another way to think about it is that if the execv system
call succeeds, then the system call never returns.
Alternative interface: posix_spawn
Calling fork() and execv() in succession to run a process may appear
counter-intuitive and even inefficient. Imagine a complex program with
gigabytes of virtual address space mapped and it wants to creates a new
process. What’s the point of copying the big virtual address space of the
current program if all we are going to do is just to throw everything away and
start anew?
These are valid concerns regarding the UNIX style of process management.
Modern Linux systems provide an alternative system call, called
posix_spawn(), which creates a new process without copying the address space
or destroying the current process. A new program gets "spawned" in a new
process and the pid of the new process is returned via one of the
passed-by-reference arguments. Non-UNIX operating systems like Windows also
uses this style of process creation.
The program in spawnmyecho.cc shows how to use the alternative
interface to run a new program:
int main() {
const char* args[] = {
"./myecho", // argv[0] is the string used to execute the program
"Hello!",
"Myecho should print these",
"arguments.",
nullptr
};
fprintf(stderr, "About to spawn myecho from pid %d\n", getpid());
pid_t p;
int r = posix_spawn(&p, "./myecho", nullptr, nullptr,
(char**) args, nullptr);
assert(r == 0);
fprintf(stderr, "Child pid %d should run myecho\n", p);
}
Note that posix_spawn() takes many more arguments than execv(). This has
something to do with the managing the environment within which the new
process to be run.
In the fork-and-exec style of process creation, fork() copies the current
process’s environment, and execv() preserves the environment. The explicit
gap between fork() and execv() provides us a natural window where we can
set up and tweak the environment for the child process as needed, using the
parent process’s environment as a starting point.
With an interface like posix_spawn(), however, this aforementioned window no
longer exists and we need to supply more information directly to the system
call itself. We can take a look at posix_spawn’s manual page to find out
what these extra nullptr arguments are about, and they are quite
complicated. This teaches an interesting lesson in API design: performance and
usability of an API, in many cases, are a pair of trade-offs. It can take very
careful work and many rounds of revision to settle on an interface design
that’s both efficient and user-friendly.
Modern UNIX-derived OSes operating systems inherited the fork-and-exec style from the original UNIX. On those systems,
forkwas extremely easy to implement, and it wasn’t that slow (because CPUs were relatively slower in those days). The performance problems withforkare bigger now, and modern operating systems have a number of optimizations that aim to makeforkrun quickly, including copy-on-write memory. Some people, though, believe thatforkis a “terrible abstraction for the modern programmer” that “compromise[s] OS implementations”. They wrote a whole paper about it (fun fact: the paper was inspired by CS 61).
Running execv() without fork()
Finally let’s take a look at runmyecho.cc:
int main() {
const char* args[] = {
"./myecho", // argv[0] is the string used to execute the program
"Hello!",
"Myecho should print these",
"arguments.",
nullptr
};
fprintf(stderr, "About to exec myecho from pid %d\n", getpid());
int r = execv("./myecho", (char**) args);
fprintf(stderr, "Finished execing myecho from pid %d; status %d\n",
getpid(), r);
}
This program now invokes execv() directly, without fork-ing a child first.
The new program (myecho) will print out the same pid as the original
program. execv() blows away the old program, but it does not change the
pid, because no new processes gets created. The new program runs inside the
same process after the old program gets destroyed.
Note on a common mistake
It’s sometimes tempting to write the following code when using the fork-and-exec style of process creation:
... // set up
pid_t p = fork();
if (p == 0) {
... // set up environment
execv(...);
}
... // do things are parent
Note that the code executes assuming it’s the parent is outside of the if
block. It appears correct because a successful execution of execv blows away
the current program, so the unconditional code following the if block with
execv in the child will never execute. It is, however, not okay to assume
that execv will always succeed (the same can be said with any system call).
If the execv() call failed, the rest of the program will continue executing in
the child, and the child can mistake itself as the parent and run into some
serious logic errors. It is therefore always recommended to explicitly
terminate the child (e.g. by calling exit()) if execv returns an error.
Interprocess communication
Processes operates in isolated address spaces. What if you want processes to talk to each other? After all, the entire UNIX programming paradigm relies on programs being able to easily pass along information among themselves!
One way processes can communication with each other is through the file system. Two processes can agree on the name of a file which they will use for communication. One process then can write to the file, and another process reads from the file. It is possible, but file systems are not exactly built for this purpose. UNIX provides a plethora of specific mechanisms for interprocess communication (IPC).
Exit detection
It’s useful for a parent to detect whether/when the child process has exited.
The system call to detect a process exit is called waitpid. Let’s look at
waitdemo.cc for an example.
int main() {
fprintf(stderr, "Hello from parent pid %d\n", getpid());
// Start a child
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
usleep(500000);
fprintf(stderr, "Goodbye from child pid %d\n", getpid());
exit(0);
}
double start_time = tstamp();
// Wait for the child and print its status
int status;
pid_t exited_pid = waitpid(p1, &status, 0);
assert(exited_pid == p1);
if (WIFEXITED(status)) {
fprintf(stderr, "Child exited with status %d after %g sec\n",
WEXITSTATUS(status), tstamp() - start_time);
} else {
fprintf(stderr, "Child exited abnormally [%x]\n", status);
}
}
The program does the following:
- Creates a child.
- The child sleeps for half a second, prints out a message, and exits.
- The parent waits for the child to finish, and prints out a message based on
the child’s exit status, which is usually 0 (which is also
EXIT_SUCCESS) on successful exit and 1 (EXIT_FAILURE) on error exit.
The interesting line in the program is the call to waitpid() in the parent.
Note the last argument to waitpid(), 0, which tells the system call to
block until the child exits. This makes the parent not runnable after
calling waitpid() until the child exists. Blocking, as opposed to polling,
can be a more efficient way to programmatically "wait for things to happen".
It is a paradigm we will see over again in the course.
The effect of the waitpid() system call is that the parent will not print
out the "Child exited..." message until after the child exits. The two
processes are effectively synchronized in this way.
Exit detection communicates very little information between processes. It essentially only communicates the exit status of the program exiting. The fact that it can only deliver the communication after one program has already exited further restricts the types of actions the listening process can take after hearing from the communication. Clearly we would like a richer communication mechanism between processes. If only we can create some sort of channel between two processes which allows them to exchange arbitrary data.
Stream communication: pipes
UNIX operating systems provide a stream communication mechanism called
"pipes". Pipes can be created using the pipe() system call. Each pipe has 2
user-facing file descriptors, corresponding to the read end and the write
end of the pipe.
The signature of the pipe() system call looks like this:
int pipe(int pfd[2]);
A successful call creates 2 file descriptors, placed in array pfd:
pfd[0]: read end of the pipepfd[1]: write end of the pipe
Useful mnemonic to remember which one is the read end:
- 0 is the value of
STDIN_FILENO, 1 is the value ofSTDOUT_FILENO- Program reads from stdin and writes to stdout
pfd[0]is the read end (input end),pfd[1]is the write end (output end)
Data written to pfd[1] can be read from pfd[0]. Hence the name, pipe.
The read end of the pipe can’t be written, and the write end of the pipe can’t be read. Attempting to read/write to the wrong end of the pipe will result in a system call error (the
read()orwrite()call will return -1).
Let’s look at a concrete example in selfpipe.cc:
int main() {
int pfd[2];
int r = pipe(pfd);
assert(r == 0);
char wbuf[BUFSIZ];
sprintf(wbuf, "Hello from pid %d\n", getpid());
ssize_t n = write(pfd[1], wbuf, strlen(wbuf));
assert(n == (ssize_t) strlen(wbuf));
char rbuf[BUFSIZ];
n = read(pfd[0], rbuf, BUFSIZ);
assert(n >= 0);
rbuf[n] = 0;
assert(strcmp(wbuf, rbuf) == 0);
printf("Wrote %s", wbuf);
printf("Read %s", rbuf);
}
In this program we create a pipe, write to the pipe, and then read from the pipe. We then assert that the string we get out of the pipe is the same string we wrote into the pipe. We do everything all within the same process.
Question: Where does the data go after the write but before the read from the pipe?
The data doesn’t live in the process's address space! It actually goes into the buffer cache, which is in the kernel address space.
The read() system call blocks when reading from a stream file descriptor
that doesn’t have any data to be read. Pipe file descriptors are stream file
descriptors, so reading from an empty pipe will block. write() calls to a
pipe when the buffer is full (because the reader is not consuming the data quickly enough)
will also block. A read() from a pipe returns EOF if all write ends of a
pipe are closed. A pipe can have multiple read ends and write ends, as we will
show below.
So far, we’ve only seen pipe functioning within the same process. Since the
pipe lives in the kernel, it can also be used to pass data between processes.
Let's take a look at childpipe.cc as an example:
int main() {
int pipefd[2];
int r = pipe(pipefd);
assert(r == 0);
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
const char* message = "Hello, mama!\n";
ssize_t nw = write(pipefd[1], message, strlen(message));
assert(nw == (ssize_t) strlen(message));
exit(0);
}
FILE* f = fdopen(pipefd[0], "r");
while (!feof(f)) {
char buf[BUFSIZ];
if (fgets(buf, BUFSIZ, f) != nullptr) {
printf("I got a message! It was “%s”\n", buf);
}
}
printf("No more messages :(\n");
fclose(f);
}
Again we use fork() to create a child process, but before that we created a
pipe first. The fork() duplicates the two pipe file descriptors in the
child, but note that the pipe itself is not duplicated (because the pipe
doesn’t live in the process's address space). The child then writes a message
to the pipe, and the same message can be read from the parent. Interprocess
communication!
Note that in the scenario above we have 4 file descriptors associated with
the pipe, because fork() duplicates the file descriptors corresponding to
two ends of a pipe. The pipe in this case has 2 read ends and 2 write ends.
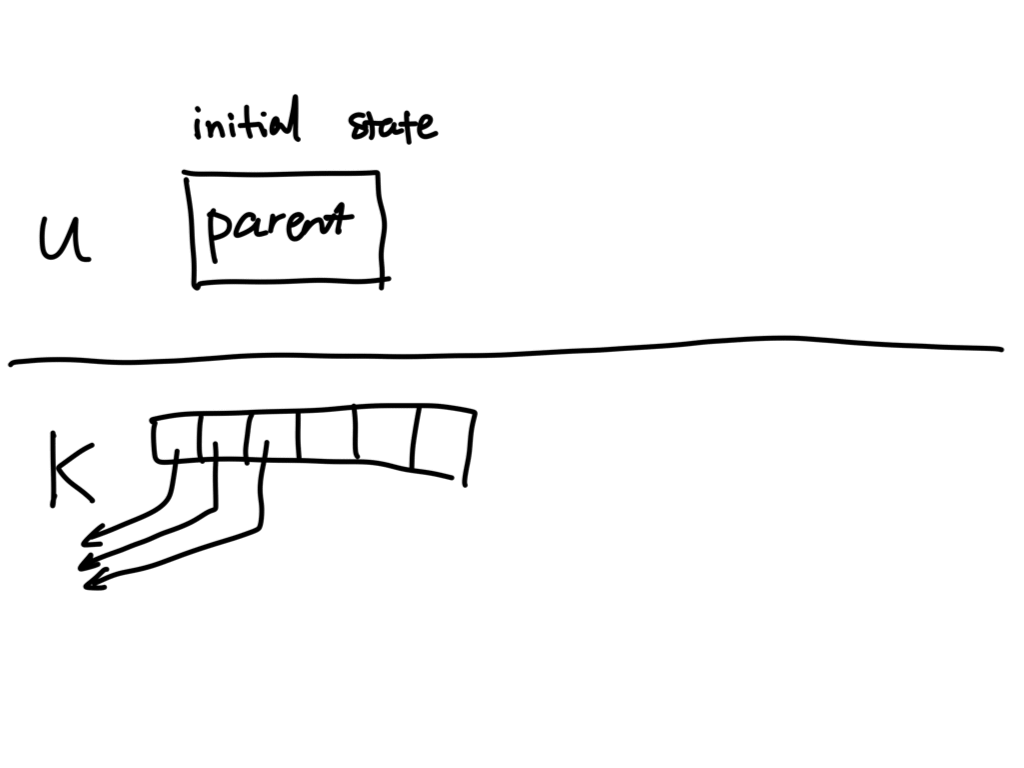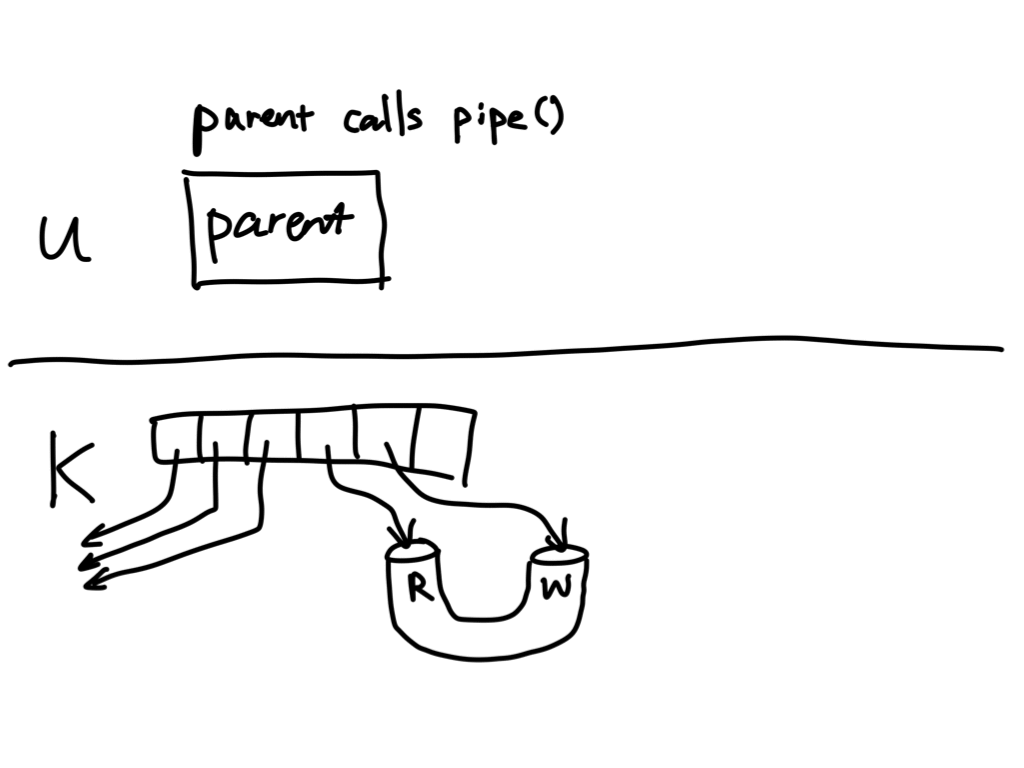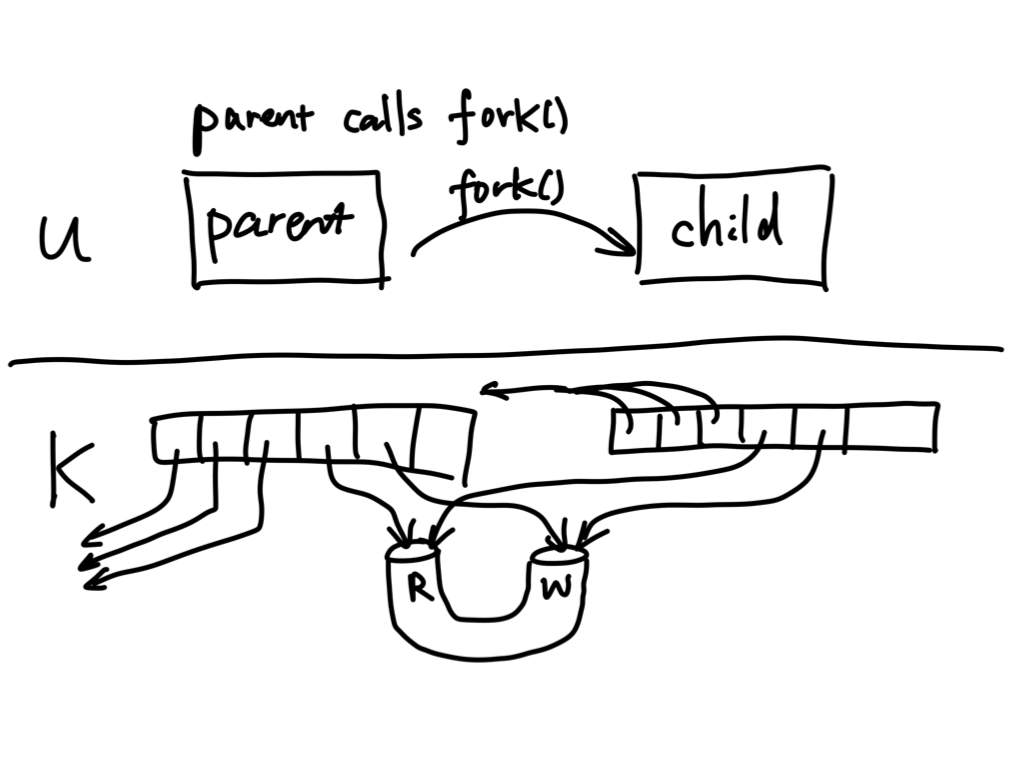
The program doesn’t exactly behave as expected, because the parent never receives an end of file (EOF) while reading, so it hangs after printing out the message from the child. This is because there always exists a write end of the pipe in the parent itself that never gets closed.
In order for the program to work, we need to close the write end of the pipe
in the parent, after the fork():
...
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
... // child code
}
close(pipefd[1]); // close the write end in the parent
FILE* f = fdopen(pipefd[0], "r");
...
Pipe in a shell
Recall how we connect programs into “pipelines” using a shell:
/bin/echo 61 | wc
This syntax means we create a pipe between /bin/echo 61 and wc.
/bin/echo’s standard output becomes a stream that is read from wc’s
standard input.
A shell sets up such a pipe using a multi-step procedure that involves work in both the parent shell process and in the child processes that eventually run other programs. One good way to get a handle on this procedure is to consider the initial state of the shell, and work incrementally toward the goal state, which is shown below.

-
Here’s the initial state of the shell.

-
Child processes inherit file descriptors from their parents only at
forktime. Since pipes must be accessible to children in the pipeline, the pipe must be created first, before the child processes.
-
Now the pipe exists, we can create the left-hand child. It is still running shell code.

-
We switch our attention to the left-hand child. Inside the code for the child (
if (result_of_fork == 0) { ... }), we must reconfigure the process environment to match the requirements of the pipeline. We start by setting up the standard output file descriptor (recall that standard output’s file descriptor number is1). It’s important not to do this in the parent shell—the parent needs itsstdout!
-
That done, we no longer need the
pfd[1]file descriptor…
-
…or the
pfd[0]file descriptor. (Not all these steps are order-sensitive—we could have closedpfd[0]first.)
-
Now the child’s environment matches all requirements, it is safe to replace its program image via
execvp. We must set up the environment before callingexecvpbecause the new program,/bin/echo, can run in many environments and simply accepts its initial environment as a given. An advantage of this separation of concerns is that the shell does not rely on/bin/echo(a program it does not control) to perform thedup2/closesystem calls correctly.
-
The left-hand child is on its merry way and is no longer running shell code. (In fact, it may execute now, writing its output into the pipe buffer!) We switch our attention back to the parent shell, which has been continuing in the meantime.
The pipe’s write end is no longer needed once the child on the left-hand side of that pipe is forked. Once a file descriptor is no longer needed by the parent shell or any of its future children, it’s safe for the parent to close it. (You could close that file descriptor later, too, but that might affect future child processes: remember that all redundant file descriptors to pipe ends require closing.)

-
The parent can now create the right-hand child.

-
The right-hand child now proceeds to reconfigure its environment, first with
dup2(pfd[0], 0), …
-
…and then
close(pfd[0]).
-
The child’s environment matches our goal, so the child calls
execvpto replace its program image with the new program.
-
Meanwhile, the parent shell closes its now-redundant read end of the pipe with
close(pfd[0]).
-
And we have arrived at our goal.
This presentation has showed the steps required to set up a two-process pipeline. Can you work out how to set up a three-process pipeline on your own?

Pipe blocking
We mentioned above that I/O operations on pipe file descriptors have blocking semantics when the operation cannot be immediately satisfied. This can occur when the buffer for the pipe is full (when writing), or when there is no data ready to be read from the pipe (when reading). If any of these situations occur, the corresponding I/O operation will block and the current process will be suspended until the I/O operation can be satisfied or encounters an error.
The blocking semantics is useful in that it simplify congestion control within the pipe channel. If two processes at the two ends of the pipe generate and consume data at different rates, the faster process will automatically block (suspend) to wait for the slower process to catch up, and the application does not need to program such waiting explicitly. It provides an illusion of a reliable stream channel between two processes in that no data can ever be lost in the pipe due to a full buffer.
The Linux kernel implements fixed-size buffers for pipes. It is merely an
implementation choice and a different kernel (or even a different flavor of
the Linux kernel) can have different implementations. We can find out the size
of these pipe buffers using the blocking behavior of pipe file descriptors: we
create a new pipe, and simply keep writing to it one byte at a time. Every
time we successfully wrote one byte, we know it has been placed in the buffer
because there is no one reading from this pipe. We print the number of bytes
written so far every time to wrote one byte to the pipe successfully. The
program will eventually stop printing numbers to the screen (because write()
blocks once there is no more space in the buffer), and the last number printed
to the screen should indicate the size of the pipe buffer. The program in
pipesizer.cc does exactly this:
int main() {
int pipefd[2];
int r = pipe(pipefd);
assert(r >= 0);
size_t x = 0;
while (1) {
ssize_t nw = write(pipefd[1], "!", 1);
assert(nw == 1);
++x;
printf("%zu\n", x);
}
}
It will show that in our Ubuntu VM the size of a pipe buffer is 65536 bytes (64 KB).
Sieve of Eratosthenes and pipes
The sieve of Eratosthenes is an ancient algorithm for finding all prime numbers up to an arbitrary limit. The algorithm outputs prime numbers by filtering out, in multiple stages, multiples of known prime numbers. The algorithm works as follows:
- Start with a sequence of integers from 2 up to the given limit;
- Take the first number off sequence and outputs it as a prime p;
- Filter out all multiples of p in the sequence;
- Repeat from step 2 using the filtered sequence;
The following is a demonstration of using the sieve of Eratosthenes to find all prime numbers up to 33:
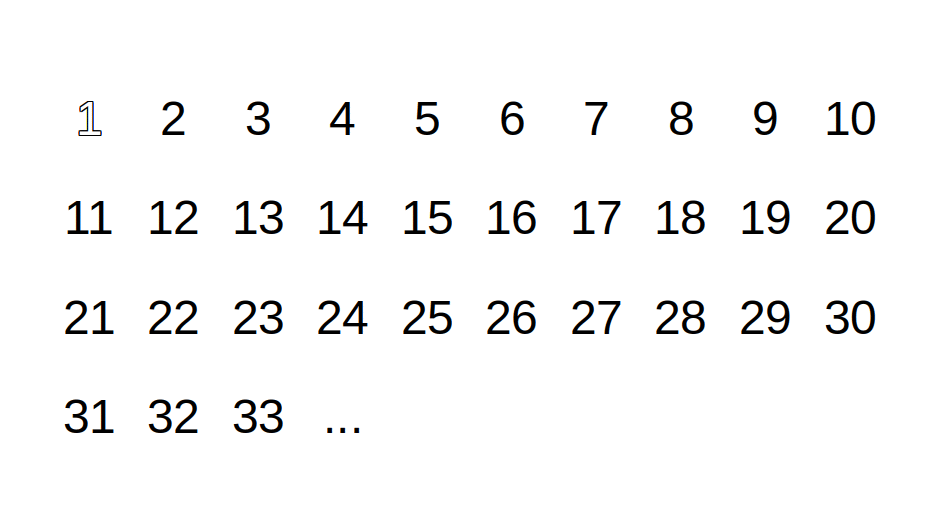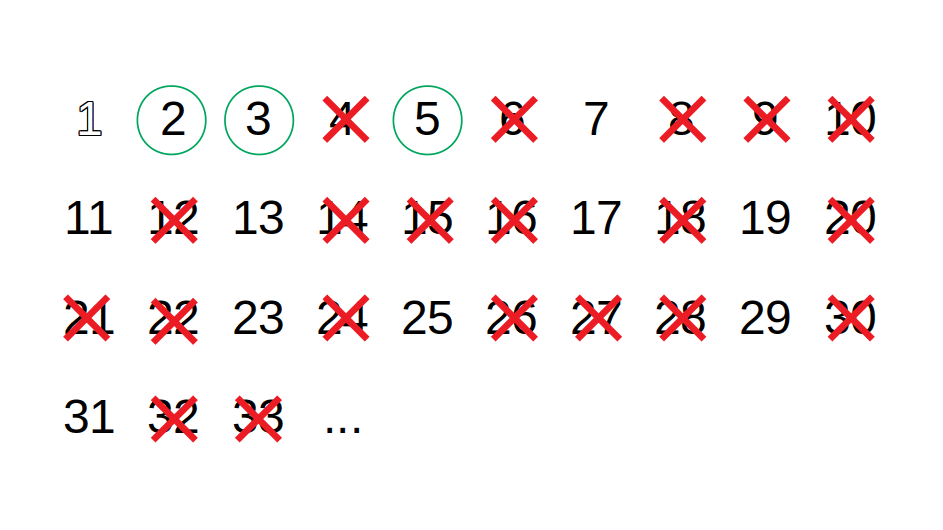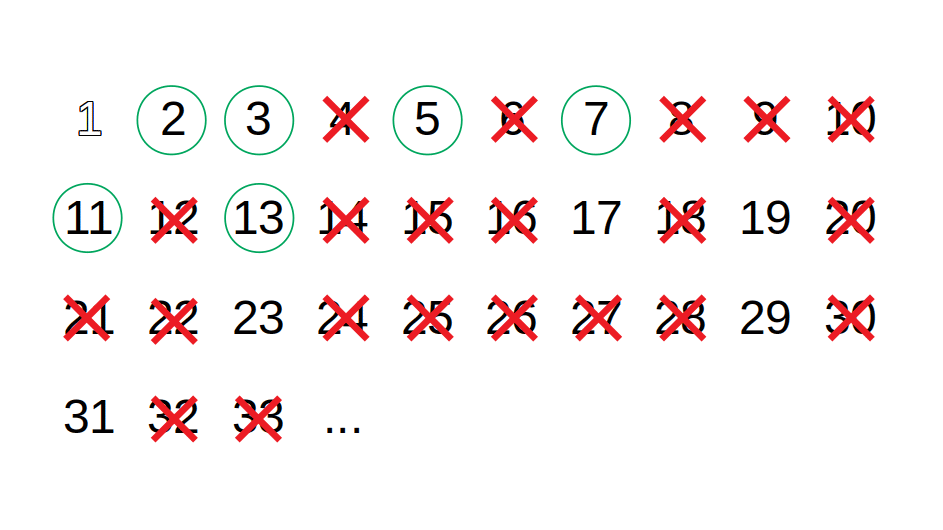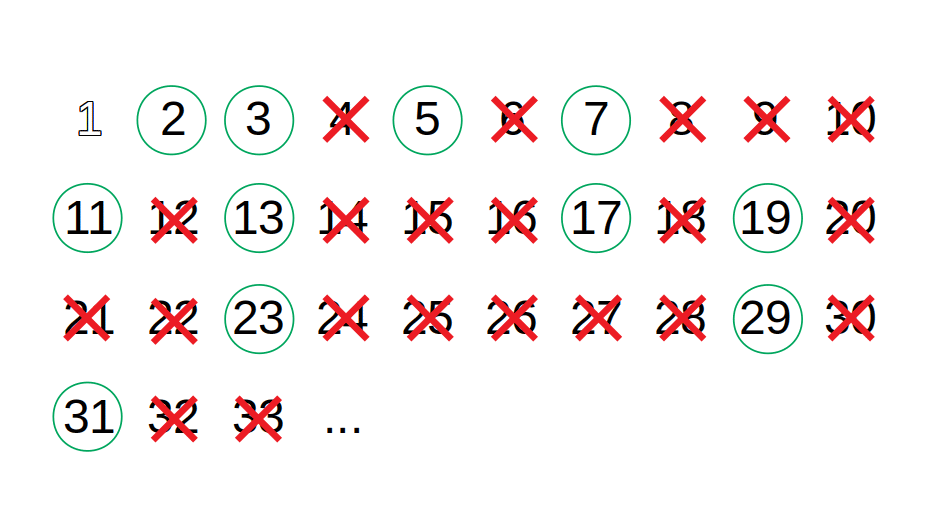
The sieve of Eratosthenes algorithm can be easily translated into a
dynamically extending UNIX pipeline. Every time the algorithm outputs a new
prime number, a new stage is appended to the pipeline to filter out all
multiples of that prime. The following animation illustrates how the pipeline
grows as the algorithm proceeds. Each fm program contained in a pipeline
stage refers to the filtermultiple program, which is a simple program that
reads a sequence of integers from its stdin, , filters out all multiples of
the given argument, and writes the filtered sequence to stdout:

How can we write such a program? The tricky part lies with dynamically extending the pipeline every time a new prime is generated.
Adding a pipeline stage
There are several high-level goals we need to achieve when extending a
pipeline. We would like a filtermultiple program to be running in the added
pipeline stage, and we would like it to be reading from the output from the
previous stage. There also exist a parent process (our primesieve program),
which is the main coordinator program responsible for the creation and
management of all filtermultiple programs in the pipeline. We also need
to pay attention to pipe hygiene, which means by the end of our pipeline
extension all pipes should look clean: each end of any pipe is only associated
with one file descriptor from any process.
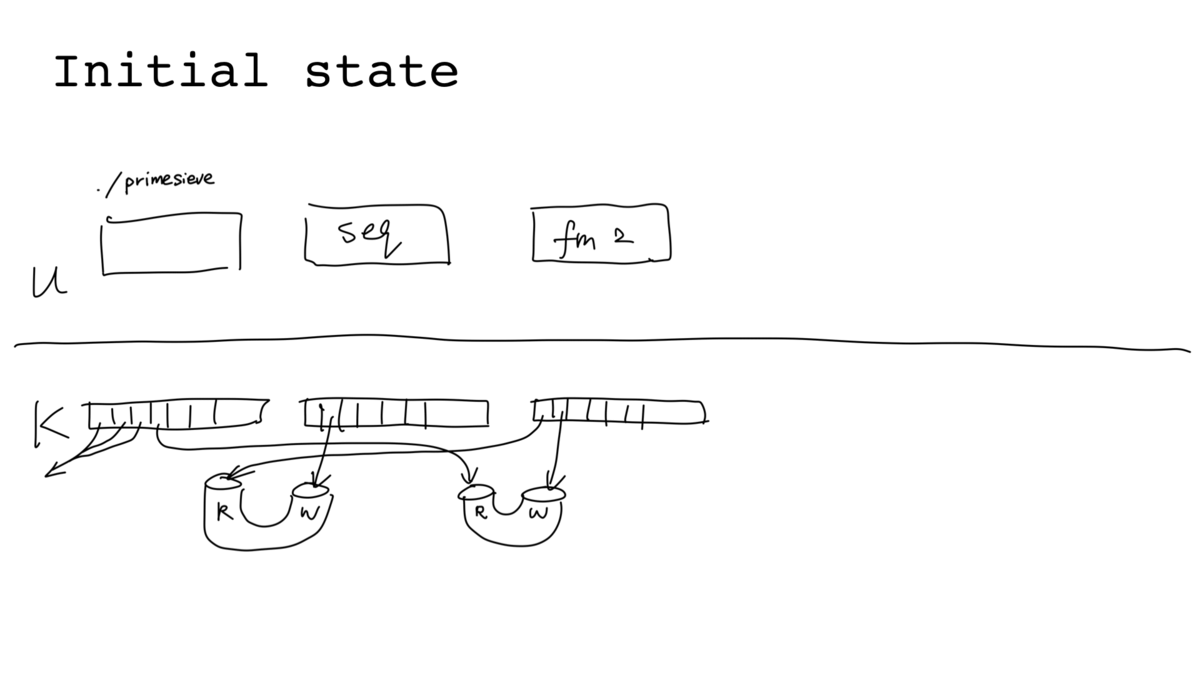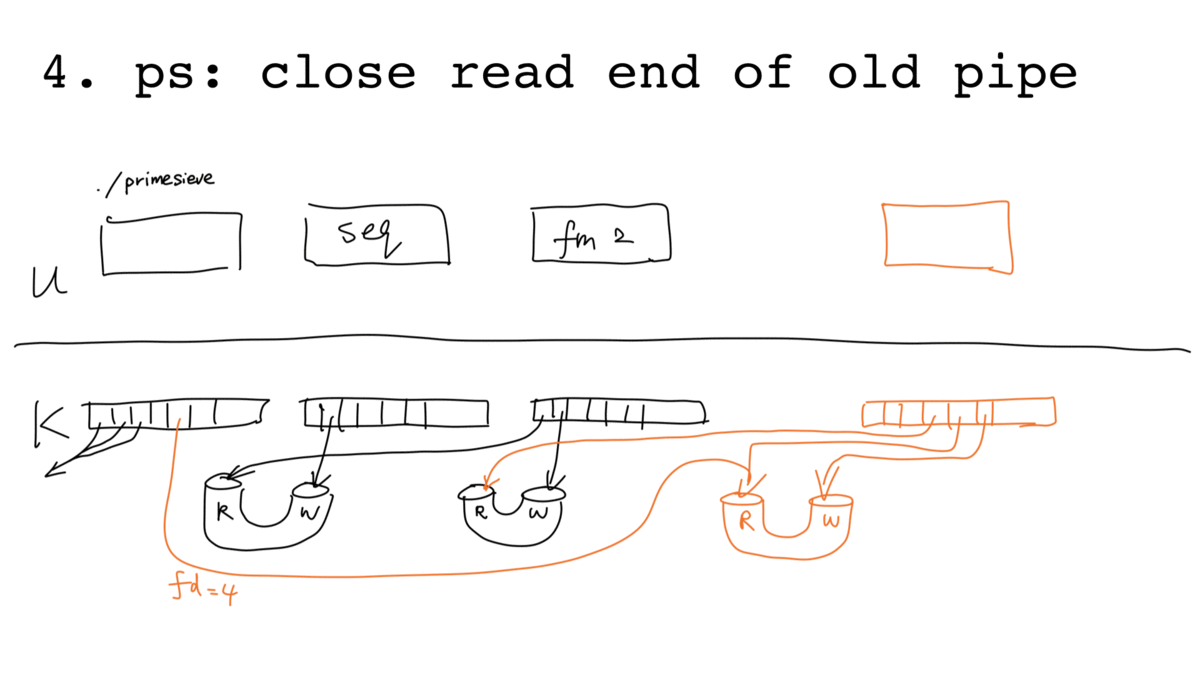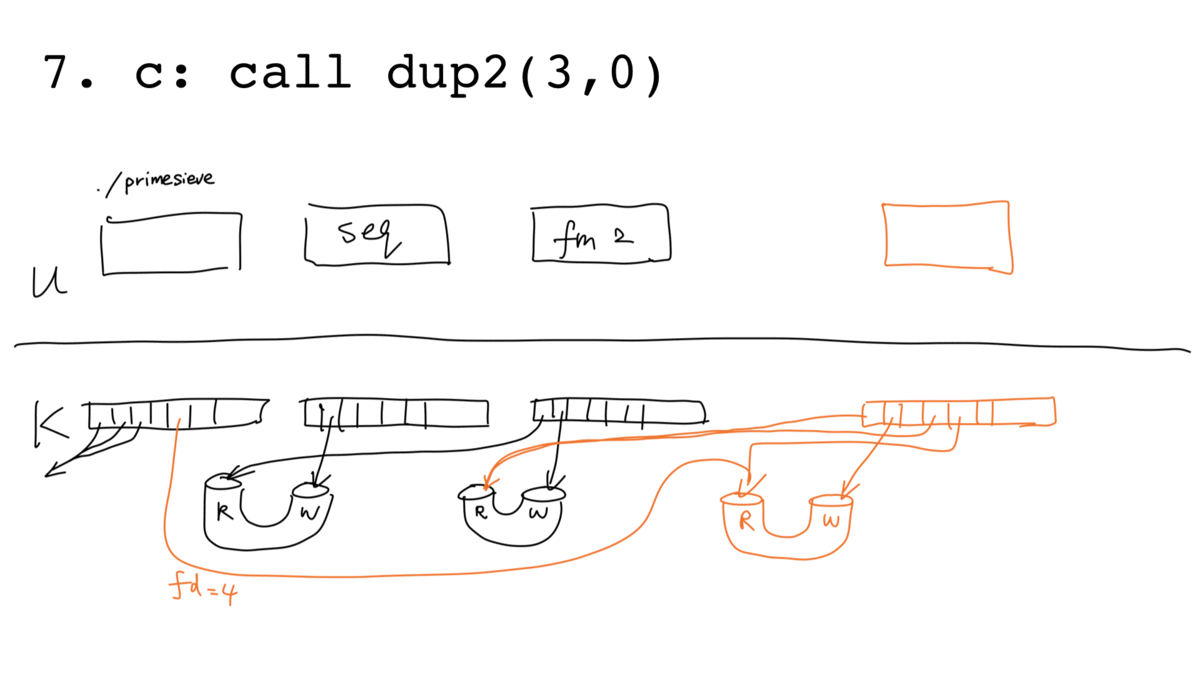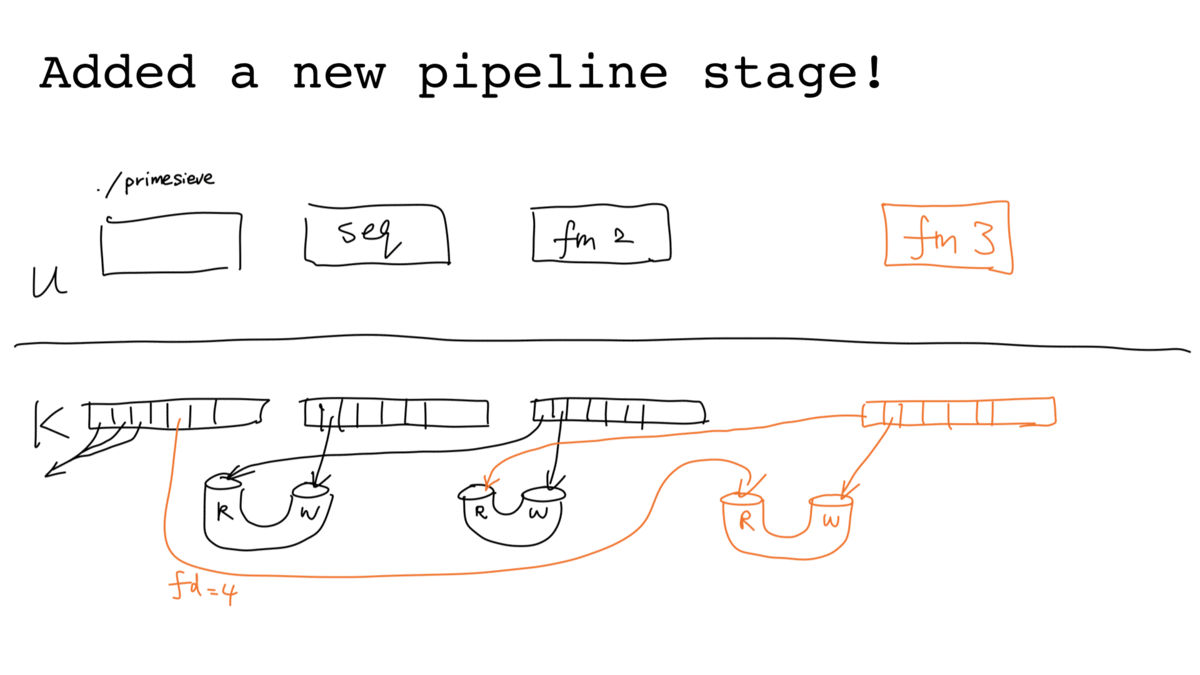
More concretely, adding a pipeline stage involves the following 8 steps ("ps:"
means running as the parent ./primesieve process; "c:" means running as
child process). Assuming at the initial stage the parent reads the first
element of the stream from the read end of a pipe via file descriptor 3:
- ps: call
pipe(), assuming returned file descriptors 4 (read end) and 5 (write end) - ps: call
fork() - ps:
close(5)(write end of the new pipe not used by parent) - ps:
close(3)(read end of the old pipe no longer used by parent) - c: call
dup2(5, 1), redirect stdout to write end of the new pipe - c: call
dup2(3, 0), redirect stdin from read end of the old pipe - c: call
close()on fds 3, 4 ,5 (pipe hygiene) - c: call
execvp(), start running./filtermultiple
The process is illustrated below (with slightly more steps because of the sequence we close "unhygienic" pipe file descriptors):
Polling and blocking
Computer systems offer two basic approaches to waiting for an event: polling and blocking.
- Polling: A process waits for an event while remaining runnable. It repeatedly checks whether the event has occurred.
- Blocking: A process requests the kernel to waits for an event. The kernel blocks the process, making it non-runnable, until the event occurs, when it wakes up.
Polling is sometimes also referred to as non-blocking. Strictly speaking, there is a slight conceptual distinction between the two: non-blocking refers to the property of a single interface call, whereas polling refers to the action of repeatedly querying a non-blocking interface until some condition is met.
Polling and blocking each have advantages and disadvantages. Polling is more efficient if wait time is expected to be very short, but it can waste energy and lower utilization (because it takes up more CPU time on non-interesting “are we there yet?” questions). Polling is also easier to get right. Blocking generally has better CPU utilization and energy usage, but it can be difficult to block on complex events.
We’ll illustrate this difference using racer programs.
In a racer program, a parent process starts a child, then waits for that child
to finish or for a timeout, whichever happens first. If the child finishes its
work before the timeout, the parent prints quick; if it does not, the parent
prints SLOW. Normally a racer program just prints quick or SLOW, but if
we give it a -V argument, we can see additional information, such as how
long the parent took to make up its mind.
$ cd cs61-lectures/process1
$ ./racer-poll # default: child does 0.5sec work, parent timeout is 0.75sec
quick
$ ./racer-poll -V
quick 0.501711
$ ./racer-poll -w 0 -V # `-w` sets child work time
quick 0.000469
$ ./racer-poll -t 0 -V # `-t` sets parent timeout
SLOW 0.000251 (child has not exited)
How can we wait for this combination of conditions (timeout or child
termination, whichever happens first)? waitpid() jumps to mind.
Unfortunately, waitpid offers no way to specify a timeout, so if the child
doesn’t exit quickly waitpid will wait for too long.
The WNOHANG option to waitpid changes the system call to polling mode.
With WNOHANG, waitpid never blocks; instead, it returns 0 if no relevant
process has exited. We can implement this compounded waiting using
non-blocking waitpid. The relevant code is in racer-poll.cc:
int status;
pid_t wp = 0;
while (timestamp() - start_time < timeout && wp == 0) {
wp = waitpid(p1, &status, WNOHANG);
assert(wp == 0 || wp == p1);
}
This is a form of “busy waiting”: the process continuously queries the exit status of the child until the condition is met. Ideally we would like a “waiting” process to be taken off the CPU until the condition it's waiting on becomes satisfied. In order for a process to yield the CPU resources in this way some blocking needs to be introduced. What we also need is to unblock at the right time. If only the blocked process can receive a “interrupt” when, for example, 0.75 seconds has elapsed or when the child has exited.
Signals
Signals are like user-level versions of interrupts. A signal has the following effects:
- A signal interrupts normal process execution.
- A signal interrupts blocked system calls, making them immediately return -1 with
errnoset toEINTR.
We have in fact all used signals to manage processes before. When we hit
CTRL+C on the keyboard to kill a running program, we are actually telling
the operating system to send a signal (SIGINT in this case) to the program.
The default behavior of the SIGINT signal is to kill the process.
Recall that one very important functionality of an operating system is to provide user-accessible abstractions of the underlying hardware features that are inconvenient or unsafe for a user process to access directly. UNIX-like systems abstract interrupts (as hardware feature) to user-space signals.
Here’s a comparison between interrupts and signals:
| Interrupts | Signals |
|---|---|
| Can happen at any time | Can happen at any time |
| Many interrupts can be blocked (delayed) | Many signals can be blocked (delayed) |
| Hardware saves machine state on interrupt using protected control transfer | Kernel saves process state on signal |
| Hardware invokes interrupt handler in kernel mode on the kernel stack | Kernel invokes signal handler in user mode on a signal stack |
Handling signals
We use the following system calls to manipulate signals:
kill(pid, sig): sends a signalsigaction(sig, handler, oldhandler): installs a signal handler
Every signal has a default handler, which typically kills the process or does
nothing. But for many signals, we can change the handler. The sigaction
library function installs a handler for a specified signal.
Signal handlers are very restricted: they should not call complex library
functions or modify memory. This is because a signal can arrive at any time
between any two program instructions, so the signal handler cannot rely on the
program’s primary memory to have a predictable state. In fact, it’s
illegal for signal handlers to call complex library functions like
malloc()! (A signal could arrive in between 2 instructions in the malloc()
routine itself, leaving the internal state and data structure used by
malloc() inconsistent.)
Typical signal handlers examine memory, modify local variables, modify global
variables of type volatile sig_atomic_t (which is a kind of int), and
perform system calls like write. Any complex tasks are left to the main
process.
For a list of functions that can safely be used in signal handlers, see
man 7 signal-safetyon Linux.
Racer signals
We use a signal handler to help us with the racer task.
Certain blocking system calls, including usleep (the system call behind the
dsleep function), will return early when a process receives a non-ignored
signal. These system calls return -1, which normally indicates an error; but
the error code errno is set to EINTR, one of the restartable
errors that indicates a non-erroneous
condition. That means that if we install a signal handler for SIGCHLD, a
system call to usleep will be interrupted when a child exits—which seems
like exactly the functionality we want!
Here’s racer-block.cc:
void signal_handler(int signal) {
(void) signal;
}
int main(int argc, char** argv) {
parse_arguments(argc, argv);
// Demand that SIGCHLD interrupt system calls
int r = set_signal_handler(SIGCHLD, signal_handler);
assert(r >= 0);
double start_time = timestamp();
// Start child
pid_t p1 = racer_fork(work_time);
// Wait for the timeout or child exit.
// `dsleep` will either succeed, returning 0 after `timeout` sec,
// or be interrupted by SIGCHLD, returning -1. (Maybe.)
r = dsleep(timeout);
// Print results
int status;
pid_t wp = waitpid(p1, &status, WNOHANG);
double elapsed = timestamp() - start_time;
if (elapsed >= timeout) {
printf("SLOW%s\n", racer_status(elapsed, wp, status).c_str());
} else {
printf("quick%s\n", racer_status(elapsed, wp, status).c_str());
}
}
The SIGCHLD signal is delivered to the process when any of its children
exits. The default behavior of SIGCHLD is to ignore the signal, so we need
to explicitly define and register a handler to override the default behavior.
For descriptions and list of all signals supported by the Linux kernel, use manual page
man 7 signal.
The parent simply goes to sleep for 0.75 seconds. If the child exited before the
0.75-second deadline, the SIGCHLD signal will cause the usleep() system call
to unblock with errno == EINTR. This way the parent does no busy waiting and
will only be blocked for at most 0.75 seconds.
Race conditions
The code above looks correct and, if run a couple times, behaves as expected.
It is really correct though? What if the child exits right away, instead
of waiting for half a second before exiting? If the child exits quickly
enough, and scheduling is unlucky, then the parent will receive SIGCHLD
before it calls usleep—and usleep will wait for the full timeout, even
though the child exited immediately (within milliseconds). This is not what we
want!
The program has what we call a race condition. A race condition is a bug that's dependent on scheduling ordering. These bugs are particularly difficult to deal with because they may not manifest themselves unless specific scheduling conditions are met.
Race conditions are terrible bugs because they are so dependent on random
environmental conditions. (A fruitful area of computer science research
involves making race conditions more repeatable and debuggable.) For instance,
we ran ./racer-block in a loop to see how often the bug would occur:
$ while true; do ./racer-block -w 0.000000001; done | uniq -c
On a Linux machine that was otherwise idle, racer-block ran more than 1
million times times without missing a child wakeup. This is because in those
conditions on Linux, the parent is very likely to reach its usleep system call
before the child gets a chance to exit.
But on the same four-CPU machine, we started four loops that fork and exit repeatedly. As soon as the machine became busy, the race condition triggered far more often—roughly 1 in 300 times!
Perhaps we can eliminate the race condition by having the signal handler
actually do something. We modify the signal handler to set a flag variable
when a SIGCHLD signal is received. The modified program is in
racer-blockvar.cc.
static volatile sig_atomic_t got_signal = 0;
void signal_handler(int signal) {
(void) signal;
got_signal = 1;
}
int main(int, char** argv) {
...
if (!got_signal) {
r = dsleep(timeout);
}
...
}
The parent now checks the flag before calling usleep. If the flag is
set—meaning the SIGCHLD signal occurred right away—the parent skips sleeping
altogether. Does this solve our problem?
No! The SIGCHLD signal might arrive after we check the flag variable in
the if conditional, but before the usleep system call is invoked. A
signal can be delivered in between any two instructions, and here, again,
there’s a tiny window where the parent can miss the signal and do the wrong
thing. A race condition is a bug unless every execution is correct.
(On a loaded Linux machine, a loop running ./racer-blockvar -w 0.000000001
still produces incorrect results, though less often than
./racer-block—around 1 in 750 times. Changes to the code that narrow the
window between the if statement and usleep can make errors less likely—I
got down to 1 in 25,000 times!—but cannot completely eliminate them.)
Race condition solutions
Take a look at code in racer-selfpipe.cc for a correct solution. The
relevant portion of the code is pasted below.
int signalpipe[2];
void signal_handler(int signal) {
const char* msg = signal == SIGCHLD ? "E" : "T";
ssize_t r = write(signalpipe[1], msg, 1);
assert(r == 1);
}
int main(int, char** argv) {
// Create the signal pipe
int r = pipe(signalpipe);
assert(r >= 0);
// SIGCHLD writes `E` to the pipe, SIGALRM writes `T`
r = set_signal_handler(SIGCHLD, signal_handler);
assert(r >= 0);
r = set_signal_handler(SIGALRM, signal_handler);
assert(r >= 0);
...
// Set an alarm for `timeout` sec, after which kernel delivers SIGALRM
struct itimerval itimer;
timerclear(&itimer.it_interval);
itimer.it_value = make_timeval(timeout);
r = setitimer(ITIMER_REAL, &itimer, nullptr);
assert(r >= 0);
// `read` will either succeed or be interrupted by a signal
// (either SIGCHLD or SIGALRM); we don’t care which!
char c;
ssize_t n = read(signalpipe[0], &c, 1);
(void) n;
...
}
We simply write one character into the pipe in the signal handler (it is fine
to invoke system calls in signal handlers), and then we use the read()
system call in the parent to wait for the read end of the pipe to become
ready. This eliminates all potential race conditions.
It may be surprising that we need so much machinery to solve this seemingly simple problem. The race condition we discussed in this example is a very common occurrence at all levels of concurrent systems design. It is so important that there is a name for it: the sleep–wakeup race condition or the lost wakeup problem.
select
The setitimer system call delivers a signal after a specific amount of time,
which can solve timeout problems. However, timeout signals are inflexible
(there’s only one timeout interval allowed per process!) and expensive to
manipulate. Most programs with timeout requirements instead use a system calls
that have an explicit timeout argument, such as select. See
racer-selectpipe.cc for an example:
int signalpipe[2];
void signal_handler(int) {
ssize_t r = write(signalpipe[1], "E", 1);
assert(r == 1);
}
int main(int, char** argv) {
// Create the signal pipe
int r = pipe(signalpipe);
assert(r >= 0);
// SIGCHLD writes `E` to the pipe, SIGALRM writes `T`
r = set_signal_handler(SIGCHLD, signal_handler);
assert(r >= 0);
...
// Wait for `timeout` sec, or until a byte is written to `signalpipe`,
// whichever happens first
fd_set fds;
FD_ZERO(&fds);
FD_SET(signalpipe[0], &fds);
struct timeval timeout_timeval = make_timeval(timeout);
r = select(signalpipe[0] + 1, &fds, nullptr, nullptr, &timeout_timeval);
...
}
The select() system call is very commonly seen in event-driven programs
(like a server). It has the following signature:
int select (
int nfds, // largest fd value to monitor + 1
fd_set* read_set,
fd_set* write_set,
fd_set* exp_set,
timeval* timeout
);
The system call will return at the earliest of:
- Some fd in
read_setbecomes readable (meaning thatread(fd)will not block); - Some fd in
write_setbecomes writable (write(fd)will not block); - Timeout elapses; or
- A signal is delivered.
signalfd
A more modern way to handle this problem involves the newer signalfd system
call. With signalfd, a process tells the operating system to respond to
signal by writing structured data to a file descriptor. That is, instead
of calling a handler, the kernel writes information about the signal to a
pipe-like file descriptor that can be read or blocked upon. This is more
efficient than the roundabout method of a user-level handler that writes to a
signal pipe.
Code for doing this is in racer-signalfd.cc. Note that there is no
definition of a signal handler any more! Instead, the main thread blocks until
data is written to the sigfd file descriptor or the timeout, whichever comes
first. (A full solution using signalfd would need to read the structured
data from the sigfd descriptor, thus clearing this SIGCHLD notification
and readying the descriptor for the next one.)
int main(int, char** argv) {
sigset_t mask;
sigemptyset(&mask);
sigaddset(&mask, SIGCHLD);
int r = sigprocmask(SIG_BLOCK, &mask, nullptr);
assert(r == 0);
int sigfd = signalfd(-1, &mask, SFD_CLOEXEC);
assert(sigfd >= 0);
...
// Wait for 0.75 sec, or until something is written to `sigfd`,
// whichever happens first
struct timeval timeout = { 0, 750000 };
fd_set fds;
FD_SET(sigfd, &fds);
r = select(sigfd + 1, &fds, nullptr, nullptr, &timeout);
...
}