Overview
In lecture, we discuss protected control transfers and virtual memory.
Full lecture notes on kernel — Textbook readings
Eve attacks
if (n % 1024 == 0) {
console_printf(CS_YELLOW "Hi, I'm Eve! #%u\n", n);
while (true) {}
}
obj/p-eve.asm
140046: 89 de mov %ebx,%esi
140048: be 6d 0c 14 00 mov $0x141171,%edi
14004d: b8 00 00 00 00 mov $0x0,%eax
140052: e8 10 10 00 00 callq 141067 <console_printf(char const*, ...)>
140057: 90 nop
140058: eb fe jmp 140058 <process_main()+0x58> ; ****
Defending against processor time attack
- Eve is monopolizing processor time
- Needs hardware defense
- Implementing software defense too expensive
- Timer interrupt
- An “alarm clock” that goes off N times a second
- Passes control to kernel via a privileged control transfer
- Only affects processor in unprivileged mode
Implementing timer interrupts
void kernel_start(const char* command) {
// initialize hardware
init_hardware();
init_timer(100); // 100 Hz
void exception(regstate* regs) {
...
switch (regs->reg_intno) {
case INT_IRQ + IRQ_TIMER:
// handle timer interrupt
lapicstate::get().ack(); // reset timer
schedule(); // run a different process
Interrupts and CPU starvation
- Alice still runs much slower; why?
- Alice uses very little of each “timeslice” they are given, but Eve uses all of each timeslice
- Solution?
- Shorter timeslices
Calling convention for interrupts
- A hardware interrupt, such as a timer interrupt, can happen at any time
- When an interrupt occurs, the processor:
- Finishes executing the current instruction
- Transfers control to the kernel
- A function call is another kind of control transfer
- Function calls have a calling convention
- What should be the hardware interrupt calling convention?
Differences between functions and interrupts
- Function calls happen voluntarily
- The caller decides to call the callee
- The caller can save state before transferring control
- In its stack frame
- The caller can restore state when it resumes
- The callee can clobber caller-saved registers as allowed by the convention
- Interrupts happen involuntarily
- The caller has no idea when an interrupt will occur
- When the interrupt is over, the caller must resume where it left off
- All of its registered must have their original values!
- The callee (the kernel) must save all registers
- The callee must restore registers before returning
Protected control transfer
- Transferring control across a privilege boundary (from process to kernel, or
kernel to process)
- Process → kernel, voluntary: system call
- Process → kernel, involuntary: exception (interrupt, trap, or fault)
- Kernel → process: resume process
- Process → kernel transfers are dangerous!
- Kernel has more machine privilege than processes
- Kernel must not be tricked into breaking isolation
- Hardened entry points
Inside an interrupt
- To initialize, kernel:
- Configures hardened interrupt entry point in processor (
k-hardware.cc) - Interrupt entry point = code + stack
- Configures hardened interrupt entry point in processor (
- During interrupt, processor:
- Changes privilege mode
- Saves some registers on preconfigured kernel stack (e.g.
%rip,%rsp) - Changes
%ripand%rspto preconfigured interrupt entry point - Starts executing kernel code
- Kernel’s interrupt entry point:
- Saves remaining registers (
k-exception.S) - Jumps to C++ interrupt handler (
exception)
- Saves remaining registers (
- Kernel’s interrupt handler:
- Saves process’s registers in process descriptor (
proc::regs) - Responds to interrupt
- Saves process’s registers in process descriptor (
- To resume process after interrupt, kernel calls
run(proc*)- Restores most registers from process descriptor
- Executes
iretinstruction to restore%rip,%rsp, and privilege mode
Voluntary process → kernel control transfer
- Unlike interrupts, system calls are voluntary
- Allowed shared responsibility for saving and restoring state
- Registers are reserved for system call parameters and return values
- Example: in WeensyOS (like x86-64 Linux),
%raxboth is a parameter register (the system call number) and the return register;%rdiholds the first system call parameter; etc.
- Unlike function calls, the kernel (callee) and process (caller) are in
different failure domains
- A buggy or malicious process must not confuse or trick the kernel
- Can’t allow processes to start executing kernel code at arbitrary locations
Inside a system call
- To initialize, kernel:
- Configures hardened system call entry point in processor
- To execute a system call, process:
- Prepares parameter registers, saves registers as needed on process stack
- Executes
syscallinstruction
- During
syscall, processor:- Changes privilege mode
- Changes some registers (e.g., return
%ripis stored in%r11) - Changes
%ripto preconfigured system call entry point - Starts executing kernel code
- Kernel’s system call entry point:
- Changes
%rspto kernel stack - Saves registers in same format as for interrupt
- Calls C++ system call handler
- Changes
- Kernel’s system call handler:
- Saves process’s registers in process descriptor
- Executes system call
- To resume process after system call, kernel either:
- Returns from
syscall(which restores registers and executesiretorsysret) - Or calls
run(proc*)(which restores registers and executesiret)
- Returns from
Yielding in depth
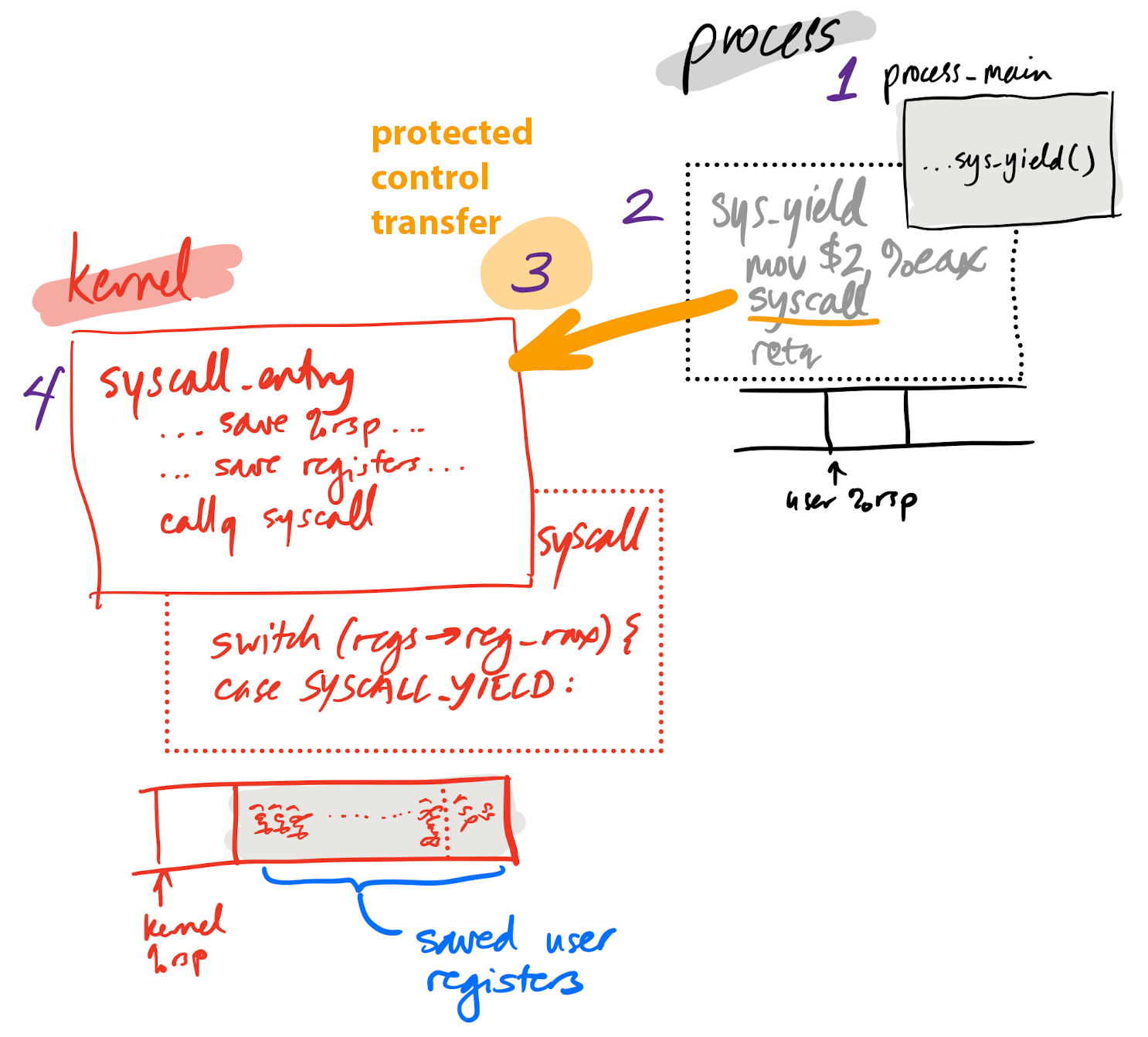
Yielding in depth 1
1. p-alice calls sys_yield
void process_main() {
unsigned n = 0;
while (true) {
++n;
if (n % 1024 == 0) {
console_printf(CS_NORMAL "Hi, I'm Alice! #%u\n", n);
}
sys_yield(); // <- ********
}
}
Yielding in depth 2
2. sys_yield prepares registers, executes syscall instruction
int sys_yield() {
return make_syscall(SYSCALL_YIELD);
}
uintptr_t make_syscall(int syscallno) {
register uintptr_t rax asm("rax") = syscallno;
asm volatile ("syscall"
: "+a" (rax)
: /* all input registers are also output registers */
: "cc", "memory", "rcx", "rdx", "rsi", "rdi", "r8", "r9",
"r10", "r11");
return rax;
}
obj/p-alice.asm
0000000000100ba0 <sys_yield()>:
100ba0: f3 0f 1e fa endbr64
100ba4: b8 02 00 00 00 mov $0x2,%eax ; `SYSCALL_YIELD` defined in `lib.hh`
100ba9: 0f 05 syscall
100bab: c3 retq
Yielding in depth 3
3. Processor performs protected control transfer
- Kernel configures processor with entry point for
syscallinstruction during boot - When
syscallinstruction happens, machine switches privilege modes, kernel takes over
Why does syscall work this way?
- Pre-configured entry point
- Kernel can harden that entry point
- Check all system call arguments carefully
- Like a city with thick walls and one fortified gate
Yielding in depth 4
4. Kernel entry point saves processor state, changes stack pointer to kernel stack
_Z13syscall_entryv:
movq %rsp, KERNEL_STACK_TOP - 16 // save entry %rsp to kernel stack
movq $KERNEL_STACK_TOP, %rsp // change to kernel stack
// structure used by `iret`:
pushq $(SEGSEL_APP_DATA + 3) // %ss
subq $8, %rsp // skip saved %rsp
pushq %r11 // %rflags
...
// call syscall()
movq %rsp, %rdi
call _Z7syscallP8regstate
...
Why switch to kernel stack?
- Kernel memory is isolated from process memory
- Kernel has its own call stack, functions, local variables
- Worse, unprivileged process might have garbage stack pointer!
- Kernel cannot depend on process correctness
- Kernel relies on memory it controls
- All accesses to process-controlled memory are checked
Yielding in depth 5
5. syscall function in kernel runs; its argument, regs, contains a copy
of all processor registers at the time of the system call
uintptr_t syscall(regstate* regs) {
// Copy the saved registers into the `current` process descriptor.
current->regs = *regs;
regs = ¤t->regs;
...
switch (regs->reg_rax) {
case SYSCALL_YIELD:
current->regs.reg_rax = 0;
schedule();
Returning from a protected control transfer
- Each system call has the same “callee”: the kernel
- But the kernel may not return from the system call right away
- It might need to wait
- It might run another process first
- Not like a simple function call!
- Kernel saves process state to kernel memory
- Can restart process at arbitrary future point
Process state
struct proc {
x86_64_pagetable* pagetable; // process's page table
pid_t pid; // process ID
int state; // process state (see above)
regstate regs; // process's current registers
// The first 4 members of `proc` must not change, but you can add more.
};
extern proc ptable[16];
- To run process
PID, callrun(&ptable[PID]) currentis a pointer to theprocthat most recently ranscheduleruns a process that is notcurrent
Kernel state note
- In WeensyOS, every protected control transfer resets the kernel stack
- Local variables do not persist
- The
runandschedulefunctions do not return- Instead, the kernel eventually regains control from another system call or exception
Memory protection
- Must prevent processes from jumping to arbitrary locations in the kernel
- Must prevent processes from accessing or modifying kernel memory
- Modification would allow controlling kernel code
- Access could be used to steal secrets
Eve attacks kernel memory
uint8_t* ip = (uint8_t*) 0x40ed0; // address of `_Z7syscall...` from `obj/kernel.sym`
ip[0] = 0xeb;
ip[1] = 0xfe;
(void) sys_getpid();
What happened?
- Eve has written an infinite loop into kernel memory
- Specifically, Eve overwrote the instructions for
syscall- With an infinite loop
- We must protect kernel memory from unprivileged access
Invisibility cloak
- What if we could tell the processor that some of memory did not exist?
Using vmiter to isolate the kernel
for (; it.va() < MEMSIZE_PHYSICAL; it += PAGESIZE) {
uintptr_t addr = it.va();
int perm = PTE_P | PTE_W | PTE_U;
if (addr == 0) {
// nullptr is inaccessible even to the kernel
perm = 0;
} else if (addr < PROC_START_ADDR && addr != CONSOLE_ADDR) {
// prevent unprivileged access
perm = PTE_P | PTE_W;
}
// install identity mapping
int r = it.try_map(addr, perm);
assert(r == 0);
}