In this lecture, we discuss the ways harms and technical systems can interact, using language coding systems as an example.
This material is by Eddie Kohler, Eliza Wells, and William Cochran.
Harm
- Harm: damage, injury
- A central concept in many ethical systems, including “classical” liberalism
- “People should be free to act however they wish unless their actions cause harm to somebody else”
- But what counts as harm?
- And who count as people?
- Useful to name harms apart from a specific value system
- Naming a harm does not imply intent
- Evaluating and weighing harms and benefits comes later
Kinds of harm
- Physical
- Emotional
- Political
- Economic
- Allocative
- When resources or opportunities are withheld from an individual or group
- Representational
- When an identity is denied, denigrated, or subordinated
Reasonable accommodation and undue burden
- New functionality often opens new opportunity for harm
- Focusing only on benefit is irresponsible
- Focusing only on harm can cause paralysis
- Need a framework for weighing harms
- Reasonable accommodation
- Reduce harm when doing so is “reasonable”
- Meaning it does not cause “undue burden” on provider
- Technical advances can reduce burdens and make accommodations more reasonable!
Examples involving the US legal system
- Reasonable accommodations
- Wheelchair-accessible sidewalks and buildings
- Extended exam times
- Prayer breaks during the workday
- Undue burdens
- Paying for an ASL interpreter (Searls v. Johns Hopkins Hospital, 2016)
- Changing employee duties (Treadwell v. Alexander, 1983)
- Paying for an audio transcription service (Dobard v. San Francisco Bay Area Rapid Transit Authority, 1993)
Ethical questions for a design decision
- Who will likely benefit from this decision?
- Who could it harm?
- In what ways, specifically, could it benefit or harm them?
- What will it take to avoid or mitigate such harm(s)?
- Does the work to avoid the harm constitute a reasonable accommodation or an undue burden?
For instance,
- Who has the resources to shoulder this burden?
- Who has the responsibility to shoulder it?
An example at Harvard
- National Association for the Deaf v. Harvard University, 2015
- “The NAD claimed that Harvard and MIT denied people who are deaf and hard of
hearing equal access to the universities’ free and online programming.
Notably, these lawsuits were the first of their kind to address the accuracy
and quality of the captions provided.”
(link)
- “The lawsuit was prompted by the recognition that, notwithstanding the description of Harvard’s online resources as available to ‘learners throughout the world,’ many of its videos and audio recordings lacked captions or used inaccurate captions. … [In response to motions to dismiss], the court ruled that federal laws prohibiting disability discrimination covered Harvard’s online content.” (link)
- “Websites are public spaces. … [O]nline presence may be interpreted as a public space and would need to be accessible … [A]uto-captions (such as YouTube’s auto-transcription feature) would not be considered equitable access under the ADA due to a high error rate.” (link)
Accessible videos
-
“In order to ensure captions meet the accuracy standards of Harvard’s Policy, any captions produced with AI will need to be edited before the video is posted online.” (link)
- “Zoom offers automatically generated live transcripts for every meeting, and meeting hosts are encouraged to turn on live captions in Zoom as an inclusive practice. Note: If live transcripts/captions have been requested as an accommodation for an event, or if Harvard's Digital Accessibility Policy requires your event to be live captioned, auto-generated captions are not sufficient. A professional vendor such as Vitac must be used to provide live captions in such cases.”
-
Example prices: $120–$150/hour for live transcription, $100–$120/hour for 24–48 hour turnaround
-
Is this cost affordable?
-
This solves the allocative harm on a group, but imposes a broader harm
Data representation: Human language
History of character encoding
- Written language centers on the concept of character
- “The smallest component of written language that has semantic value” (ref)
- Once language is encoded in characters, characters themselves can be encoded in other forms



Encoding requirements
- Interchange: Messages can be exchanged without losing information
- Efficiency/parsimony: Representation of language uses few bytes
- Unambiguity: A message has one fixed meaning
- Robustness: A message preserves meaning despite transmission errors
- These goals conflict!
Encoding history
- Early encodings represented only unaccented capital Roman letters
- IBM’s BCDIC based on 1880s technology developed for the US Census
- To represent new characters, some encodings used shift codes that change
the mode for future codes
- CCITT-2:
0b01010meansRin “letter shift” mode and4in “figure shift” mode - Shift code
0b11011changes to figure shift mode,0b11111to letter shift mode
- CCITT-2:
- Storage becomes more plentiful → more bits per character
- ASCII: 7-bit code, upper and lower case
- ISO 8859-1: 8-bit code, adds accented letters
- Many other ISO encodings support other languages
Harms and one-byte encodings
- Say that the only available text encodings were ISO 8859 variants
- Who would be harmed? In what way?
- Can you suggest ways to alleviate these harms? Are they reasonable accommodations or undue burdens?
Enter Unicode
- A single encoding to support all human languages with one code point per character
- First thought 216 = 65536 code points would suffice
- Now 1,112,064 ≅ 17×216 code points
- U+0000 – U+10FFFF; requires up to 21 bits to represent
- 149,186 code points used as of Unicode 15.0
- Covering 161 modern and historic scripts
Harms and Unicode
- Does Unicode alleviate any of the harms caused by one-byte encodings?
- Have any new harms been created? On whom?
Problems with 16- and 32-bit encodings for Unicode
- Expensive relative to 7-bit ASCII or 8-bit ISO 8859
- 2x or 4x!
- Ambiguity
- Does the byte sequence
0x65 0x00represente(little-endian U+0065) or攀(big-endian U+6500)? - Solution: U+FEFF BYTE ORDER MARK
- Does the byte sequence
- Incompatibility with existing programming languages
- In the C programming language, the zero byte
0x00ends a string - In 16- or 32-bit encodings of Unicode, zero bytes abound
- In the C programming language, the zero byte
Desiderata for an 8-bit encoding for Unicode
- Byte-based
- Compatible with ASCII
- Any byte corresponding to ASCII should indicate that character
- Regardless of where it appears
- Resistant to errors
- Not shift-based
- Self-synchronizing: only one way to decode a sequence of bytes
- Relatively efficient
Idea #1: Unary
-
Bytes
0x00–0xFDrepresent characters U+0000–U+00FD -
Character C > \texttt{0xFD} represented by
0xFE, followed by (C-\texttt{0xFE})0xFFbytes -
Examples
Text Code points Encoding Hi! U+0048 U+0069 U+0021 0x48 0x69 0x21ATĀ U+0041 U+0054 U+0100 0x41 0x54 0xFE 0xFF 0xFF -
Desiderata
- Byte-based?
- Compatible with ASCII?
- Not shift-based?
- Self-synchronizing?
- Efficient?
Text Code points Encoding «Allô !» U+00AB U+0041 U+006C U+006C U+00F4 U+0020 U+0021 U+00BB 0xAB 0x41 0x6C 0x6C 0xF4 0x20 0x21 0xBB你好 U+4F60 U+597D 0xFE 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFE 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF …(42,723 bytes total)
Harm, undue burden, reasonable accommodation
- Idea #1:
- Bytes
0x00-0xFDrepresent U+0000–U+00FD - Character C > \texttt{0xFD} represented by
0xFE, followed by (C-\texttt{0xFE})0xFFbytes
- Bytes
- Say that Idea #1 was the only available text encoding
- Who would be harmed? In what way?
- What harms would be alleviated? And from whom?
- Does this encoding represent a reasonable accommodation?
Idea #2: Byte pairs
- Bytes
0x00–0x7Frepresent characters U+0000–U+007F - Divide C > \texttt{0x7F} into two 7-bit blocks
- C_0 has bits 0–6 of C, and C_1 has bits 7–13
- Alternately, C_0 = C \bmod 128 and C_1 = \lfloor C / 128 \rfloor
- C = C_0 + 128 \times C_1, where 0 \leq C_0, C_1 \leq \texttt{0x7F}
- Use bytes ⟨\texttt{0x80} + C_1⟩ ⟨\texttt{0x80} + C_0⟩
- Examples
Text Code points Encoding Hi! U+0048 U+0069 U+0021 0x48 0x69 0x21ATĀ U+0041 U+0054 U+0100 0x41 0x54 0x82 0x80«Allô !» U+00AB U+0041 U+006C U+006C U+00F4 U+0020 U+0021 U+00BB 0x81 0xAB 0x41 0x6C 0x6C 0x81 0xF4 0x20 0x21 0x81 0xBB你好 U+4F60 U+597D …? - Say that Idea #2 was the only available text encoding
- Who would be harmed? In what way?
- What harms would be alleviated? And from whom?
- Does this encoding represent a reasonable accommodation?
Idea #3: Byte triples
- Bytes
0x00-0x7Frepresent characters U+0000–U+007F - Divide C > \texttt{0x7F} into three 7-bit blocks
- C_0 has bits 0–6 of C; C_1 has bits 7–13; C_2 has bits 14–20
- Use bytes ⟨\texttt{0x80} + C_2⟩ ⟨\texttt{0x80} + C_1⟩ ⟨\texttt{0x80} + C_0⟩
- Examples
Text Code points Encoding Hi! U+0048 U+0069 U+0021 0x48 0x69 0x21ATĀ U+0041 U+0054 U+0100 0x41 0x54 0x80 0x82 0x80«Allô !» U+00AB U+0041 U+006C U+006C U+00F4 U+0020 U+0021 U+00BB 0x80 0x81 0xAB 0x41 0x6C 0x6C 0x80 0x81 0xF4 0x20 0x21 0x80 0x81 0xBB你好 U+4F60 U+597D 0x81 0x9E 0xD0 0x81 0xB2 0xFD - Desiderata
- Byte-based?
- Compatible with ASCII?
- Not shift-based?
- Self-synchronizing? No
Idea #4: Self-synchronizing byte quadruplets
- Bytes
0x00-0x7Frepresent characters U+0000–U+007F - Divide C > \texttt{0x7F} into four 6-bit blocks
- C_0 has bits 0–5 of C; C_1 has bits 6–11; C_2 has bits 12–17; C_3 has bits 18–20
- Use bytes ⟨\texttt{0xC0} + C_3⟩ ⟨\texttt{0x80} + C_2⟩ ⟨\texttt{0x80} + C_1⟩ ⟨\texttt{0x80} + C_0⟩
- Can always tell if a byte starts a character (self-synchronizing)
0x00–0x7Fis a one-byte character,0xC0–0xC4starts a four-byte character,0x80-0xBFcontinues a four-byte character
- Examples
Text Code points Encoding Hi! U+0048 U+0069 U+0021 0x48 0x69 0x21ATĀ U+0041 U+0054 U+0100 0x41 0x54 0xC0 0x80 0x84 0x80«Allô !» U+00AB U+0041 U+006C U+006C U+00F4 U+0020 U+0021 U+00BB 0xC0 0x80 0x82 0xAB 0x41 0x6C 0x6C 0xC0 0x80 0x83 0xB4 0x20 0x21 0xC0 0x80 0x82 0xBB你好 U+4F60 U+597D 0xC0 0x84 0xBD 0xA0 0xC0 0x85 0xA5 0xBD - Say that Idea #4 was the only available text encoding
- Who would be harmed? In what way?
- What harms would be alleviated? And from whom?
- Does this encoding represent a reasonable accommodation?
UTF-8
- Bytes
0x00–0x7Frepresent characters U+0000–U+007F - Divide \texttt{0x80} \leq C \leq \texttt{0x7FF} into two blocks and encode in two bytes
- C_0 has bits 0–5 of C; C_1 has bits 6–10
- Use bytes ⟨\texttt{0xC0} + C_1⟩ ⟨\texttt{0x80} + C_0⟩
- First byte has value
0xC2–0xDF
- Divide \texttt{0x800} \leq C \leq \texttt{0xFFFF} into three blocks and encode in three bytes
- C_0 has bits 0–5 of C; C_1 has bits 6–11; C_2 has bits 12–15
- Use bytes ⟨\texttt{0xE0} + C_2⟩ ⟨\texttt{0x80} + C_1⟩ ⟨\texttt{0x80} + C_0⟩
- First byte has value
0xE0–0xEF
- Divide \texttt{0x10000} \leq C \leq \texttt{0x10FFFF} into four blocks and encode in four bytes
- C_0 has bits 0–5 of C; C_1 has bits 6–11; C_2 has bits 12–17; C_3 has bits 18–20
- Use bytes ⟨\texttt{0xF0} + C_3⟩ ⟨\texttt{0x80} + C_2⟩ ⟨\texttt{0x80} + C_1⟩ ⟨\texttt{0x80} + C_0⟩
- First byte has value
0xF0–0xF4
- Sketched on a placemat in 1992 by Ken Thompson, one of the Unix inventors (citation)
Advantages of UTF-8
- Compatible with existing software and libraries
- Every ASCII file is also a UTF-8 file with the same meaning
- UTF-8 does not use the 0 byte, so existing C library functions continue to work on UTF-8 strings! (UTF-16 texts contain tons of zero bytes)
- Resistant to errors
- No synchronization issues: an error in one byte affects at most one character
- Contrast the telegraphy system, where an error in a “shift byte” can affect the interpretation of all future characters
- Relatively efficient
- Unicode code points U+0080–U+07FF can be represented in two bytes
- So texts in European Latin script, African Latin script, Greek script, Cyrillic script, and most Arabic-script languages take no more space than in UTF-16
- But other scripts may take more space than UTF-16: Brahmic (Indic), Han, Japanese, Korean
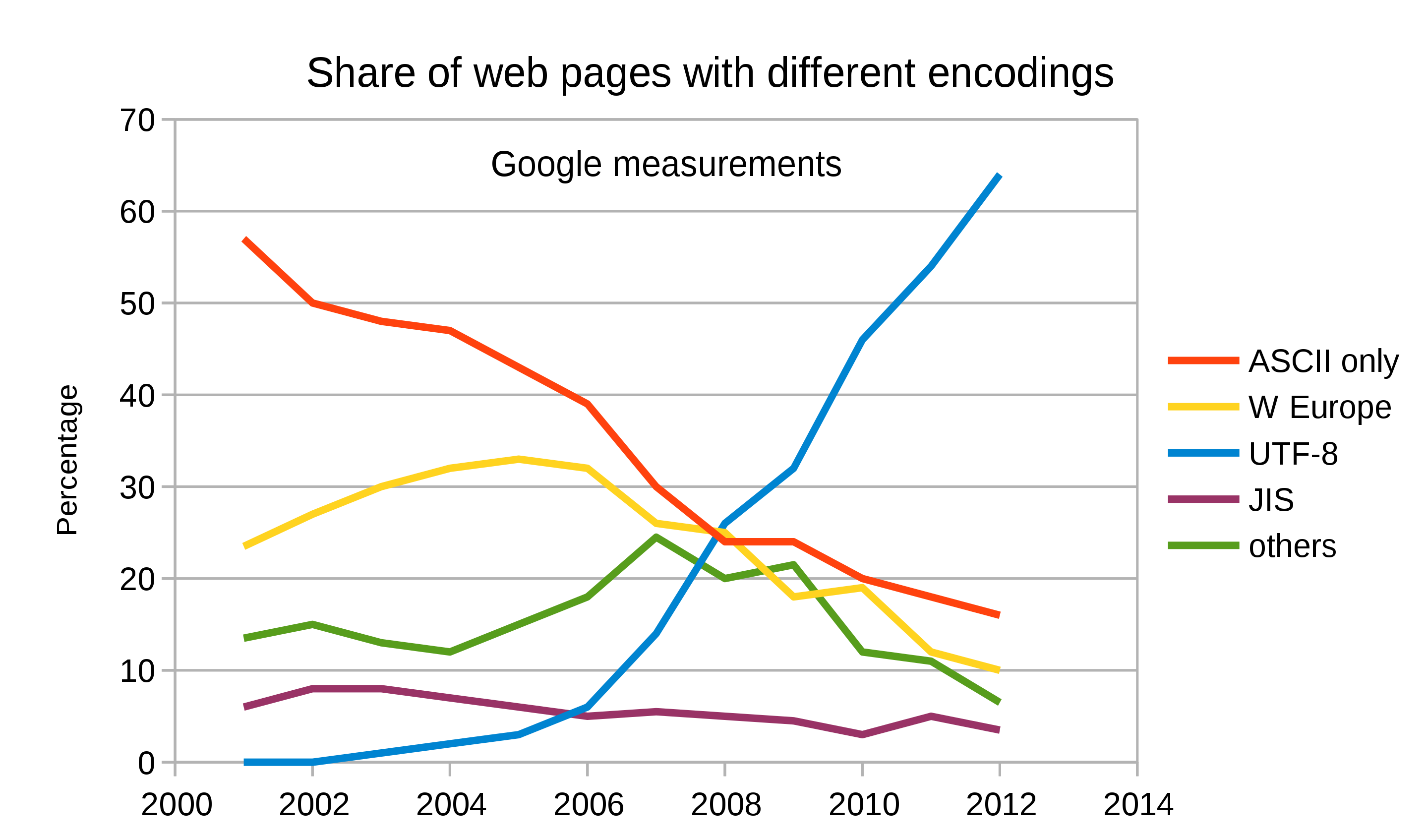
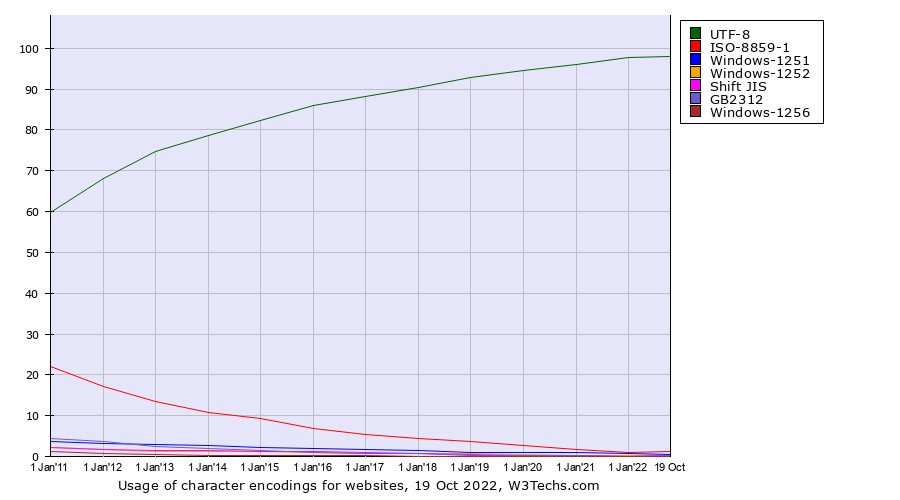
UTF-8 deployment
- Now over 97% of web pages!
- Increasingly the default in programming languages and operating systems
 |
 |
Harms in UTF-8
- Say that Unicode UTF-8 were the only available text encoding
- Who would be harmed? In what way?
- What harms would be alleviated? And from whom?
- Would requiring this encoding represent a reasonable accommodation?
Case studies
Emoji
- If you’re interested in digging deeper into encoding issues, consider emoji
- Intersection between technical and social issues
- Many of the same high-level issues encountered in encoding written language recur
- Similar solutions recur too
Emoji history
- People have built tiny pictures from punctuation for years, including
artists and poets but also scientists and engineers
- September 1982: A message thread at CMU spins out of control. Tone is hard to communicate electronically!
- “Maybe we should adopt a convention of putting a star (*) in the subject field of any notice which is to be taken as a joke.”
- “I propose the following character sequence for joke markers: :-) Read it sideways.” (citation)
- Modern emoji were invented for cell phones in Japan by 1997
- Carriers competed on their emoji sets
- Initially not interoperable!
Emoji and Unicode
- Emoji became so popular that Unicode encoding was inevitable
- Enormous technical challenges
- First characters where color is important—font standards require changes
- Social challenges: Which emoji deserve representation?
-
Unicode code points are a finite resource
-
The powerful start lobbying

-
Will a fixed emoji set suffice?
-
Issues of unequal representation
-
Emoji sets from Japan used a light skin tone for many characters

SoftBank is a Japanese cell phone carrier, the original inventors of emoji. This is from their 1999 set, the first set that had color (and animations). Image from Emojipedia
-
How to represent varieties of skin tone? Some designers went for non-representational tones (gray, bright yellow), but that didn’t suffice
-
Make 5x as many emoji? Why stop at 5x?
Emoji and culture
- Is character encoding normative?
- Images that seem inoffensive in one culture and time aren’t appropriate in others
- People interpret the default emoji set as a statement by society, or by the computer industry, of what is right or most normal
- Consider some characters added to Unicode 6.0 in 2010, adopted from
Japanese mobile phone emoji sets:
U+1F48F KISS U+1F46F WOMAN WITH BUNNY EARS 

Reducing undesirable signification
-
Emoji representations lose specificity
U+1F48F in 2010 U+1F48F in 2020 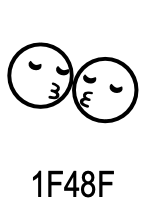
-
Emoji representations change appearance more fundamentally
U+1F46F in 2010 U+1F46F in 2020 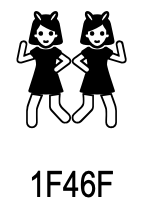
- The standards now say the emoji is “most popularly depicted as two women dancing”; some redefine it to be gender neutral, as “people with bunny ears” or “party”
Representing more cultures
- Erasing cultural differences is not the best way to achieve equality
- People want to be represented!
- Impossible or inefficient to represent all important representations with individual code points
- Try variable-length encoding?
Example: Kiss
- U+1F48F KISS 💏 now represents gender-nonspecific people
- To represent more specific people kissing, use a Unicode combiner, U+200D ZERO WIDTH JOINER, invented to represent scripts such as Arabic and Indic where sometimes characters are visually connected
- “Kiss: Woman, Man” 👩❤️💋👨 is represented as:
- U+1F469 WOMAN 👩
- U+200D ZERO WIDTH JOINER
- RED HEART ❤️, which is represented as…
- U+2764 HEAVY BLACK HEART ❤︎
- U+F30F EMOJI VARIATION SELECTOR
- U+200D ZERO WIDTH JOINER
- U+1F48B KISS MARK 💋
- U+200D ZERO WIDTH JOINER
- U+1F468 MAN 👨
- That might seem crazy, but look at the HTML source using
hexdump -Cto verify. It takes 31 bytes:f0 9f 91 a9(WOMAN)e2 80 8d(ZWJ)e2 9d a4(HEAVY BLACK HEART)ef b8 8f(EMOJI VARIATION SELECTOR)e2 80 8d(ZWJ)f0 9f 92 8b(KISS MARK)e2 80 8d(ZWJ)f0 9f 91 a8(MAN).
- But this representation naturally generalizes to “Kiss: Man, Man” and “Kiss: Woman, Woman”! (Or “Kiss: Male Astronaut, Female Zombie”)
- Other sequences can represent skin tone, hair color, other features
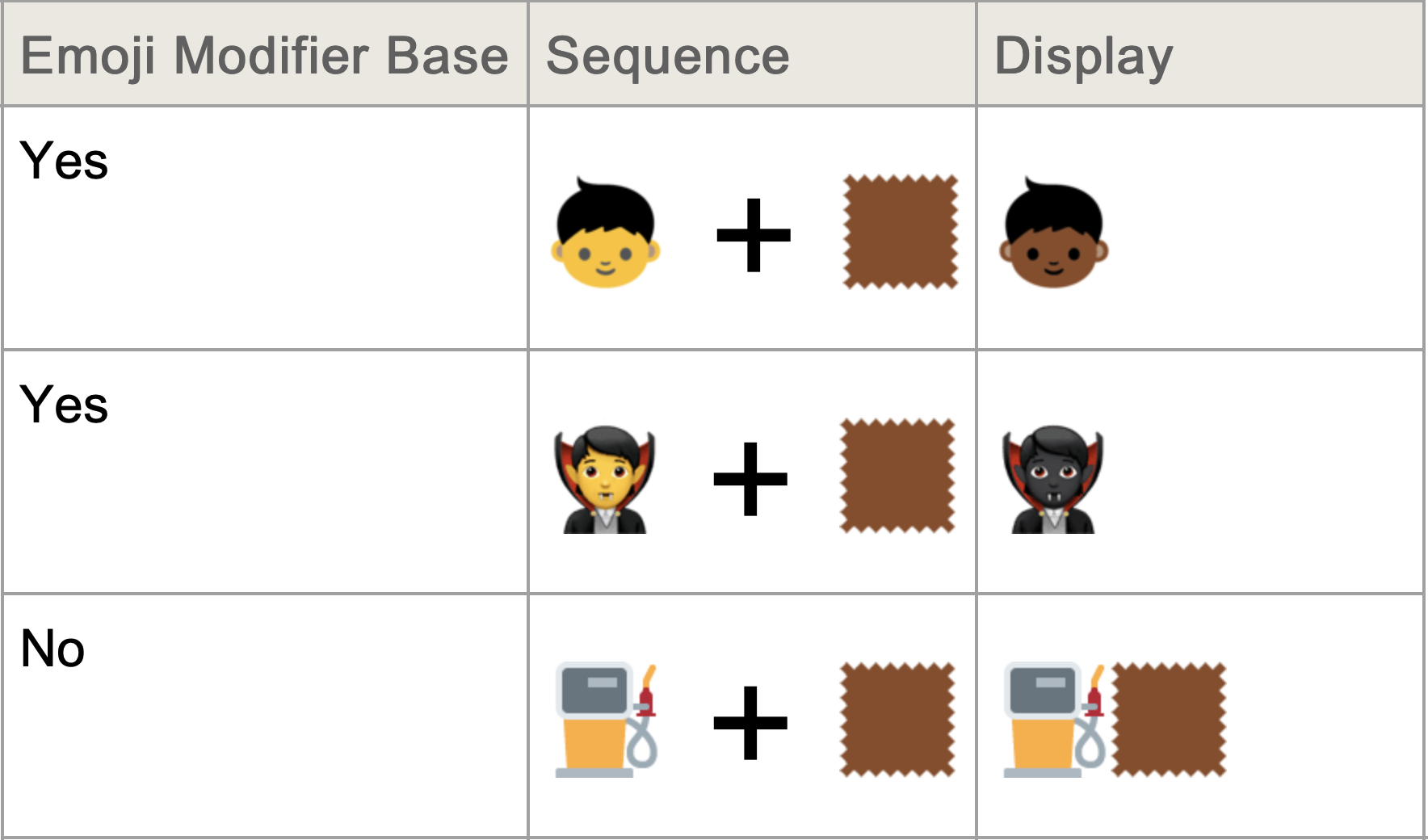
Presented without comment
From The Unicode Emoji technical standard: