Overview
In this first lecture in the kernel unit, we introduce the goals of operating systems and introduce our tiny operating system in depth.
Full lecture notes on kernel — Textbook readings
Calling convention and red zone
asm/redzonef01.ccasm/redzonef02.cc
Typical stack frame layout
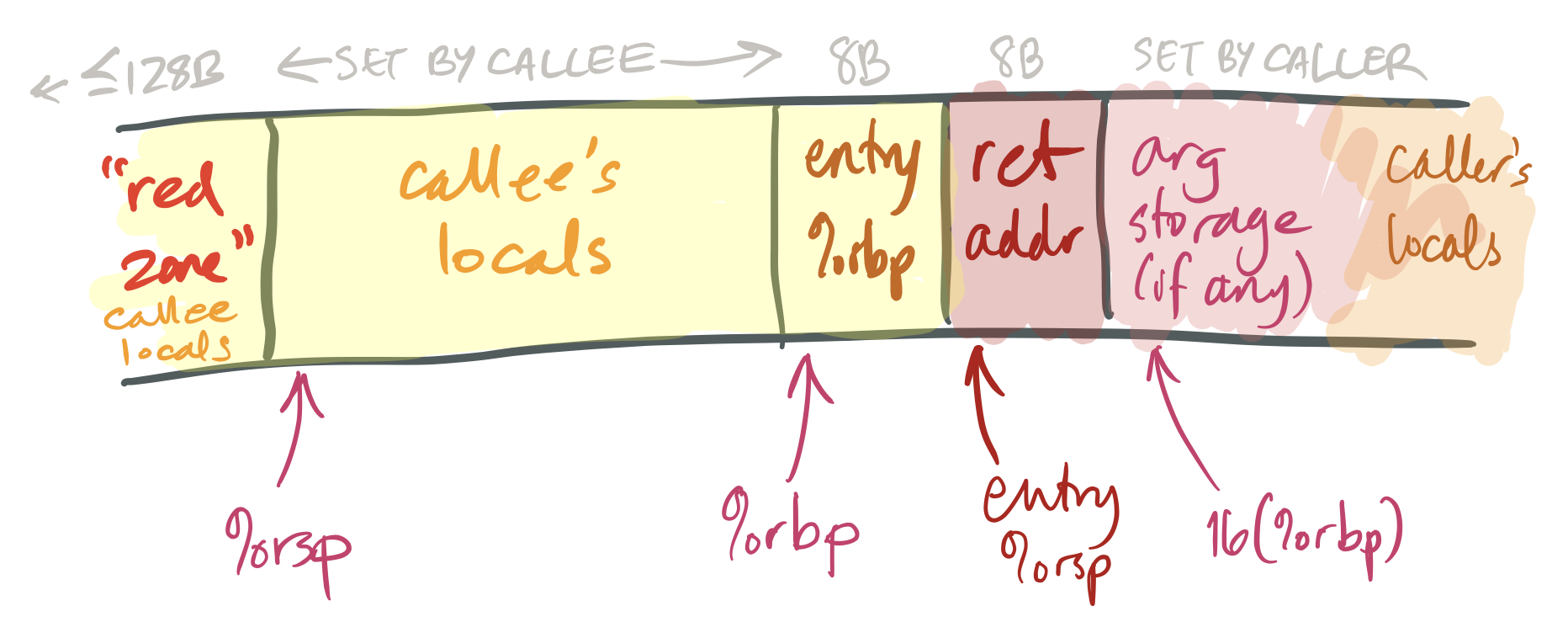
- Be careful about conventions/rules vs. typical usage!
- Calling convention: %rbp is callee-saved
- Typical usage: %rbp acts as a stable pointer near the top of the current
function’s stack frame
- Supports variable-sized stack frames (
man alloca)
- Supports variable-sized stack frames (
- But typical usage can differ
- Optimizer might decide this function benefits from treating %rbp like a normal callee-saved register
Other uses of condition flags
asm/cmaxf01.ccasm/cmaxf02.cc
System instructions
asm/print.cc
What is happening behind syscall??
syscall invokes the kernel
- All of the software we’ve written so far runs in a protected, isolated environment called a process environment
- The process environment is restricted in several ways to make the computer
as a whole more robust
- A process cannot monopolize computer resources
- A process cannot directly access computer hardware
- If a process wants to access hardware, it calls out to a special, more privileged running program called the kernel
- The kernel is the software running with full privilege over the
underlying machine hardware
- The kernel may monopolize computer resources
- The kernel may directly access computer hardware
- The kernel should make processes’ lives easier by providing useful abstractions (like files), and by protecting processes from each others’ bugs
- Different operating systems have different kernels (Linux vs. Mac OS X vs. Windows); processes running on the same operating system interact with the same kernel
Goal: Process isolation
- Process interactions are restricted by operating system policy
- For instance, processes may interact by reading and writing files
- Not by overwriting each other’s memory
- A critically important computer systems goal
- Without it, any bug in any software could cause a “blue screen of death”
Goal: Kernel isolation
- The kernel always retains full privilege over all machine operations
- Unprivileged processes cannot stop the kernel from running
- Unprivileged processes cannot corrupt the kernel
Process isolation’s consequences for hardware design
- There are at least two classes of software running on a computer
- The kernel has full control over computer resources
- Processes do not
- We often call processes unprivileged processes or user processes to highlight this distinction
- Restrictions on processes cannot be enforced by software alone
- The processor and other computer hardware must have a notion of privilege
- The processor and other computer hardware must handle privilege violations
Exception: Some experimental systems have fully-trusted source code chains, where, for example, the compiler has been proven correct, and all code running on the machine passes through the trusted compiler. In these systems, it’s theoretically possible to implement process isolation without hardware support.
Some processor features we’ll investigate
- Special instructions for transferring control to the operating system
- System calls and the
syscallinstruction
- System calls and the
- Processor privilege modes
- Hardware features that prevent monopolization of resources
- Protection of memory
- Virtual memory
Why learn about kernels?
- It is natural for programmers to think about performance and functionality
- Harder to think about security and robustness
- Keeping a program safe from attackers
- Limiting the impact of bugs (which are inevitable)
- Kernels sharpen these issues
- Understand how software and hardware interact
- Kernels are super powerful and fun
Alice and Eve in WeensyOS
p-alice: PrintsHi, I’m Alice!and yieldsp-eve: PrintsHi, I’m Eve!and yields
WeensyOS commands
make runormake run-PROCESS- Run WeensyOS (with a specific first process)
make stop- Stop all WeensyOSes in this Docker environment
make STOP=1 run+gdb -ix build/weensyos.gdb- Run those commands in separate terminals open to the same Docker environment
- The first command boots WeensyOS, but stops before the kernel gets control
- In
gdb, set breakpoints and typecto continue
Emulation
- WeensyOS runs inside a machine emulator called QEMU
- QEMU is a software program that can behave like a complete x86-64 computer system
- Interprets instructions, translates input/output to a more convenient format
- For example, instead of generating electrical signals that could be sent to a television (like the original IBM Personal Computer), QEMU’s emulated display hardware can produce commands understood by the terminal
- QEMU has many other uses too
Protected control transfer
- To yield (or initiate any system interaction), a process must communicate with the kernel
- Processes are isolated
- Kernel mediates communication according to policy
- Kernel communication is a security risk
- Unprivileged process must not simply gain privilege! (Could misuse that privilege)
- Unprivileged process must not execute arbitrary kernel code! (Could crash the machine)
- Protected control transfer: transfer control across a privilege boundary
- “Control” refers to control flow: which instruction runs next
System call in depth
- User calls wrapper function for system call
- Wrapper function prepares registers, executes
syscallinstruction - Processor performs protected control transfer to kernel
- Switches privilege, starts executing kernel code at pre-configured address
- Kernel entry point saves processor registers so process can be restarted
- Kernel
syscall()function handles system call
Yielding in depth
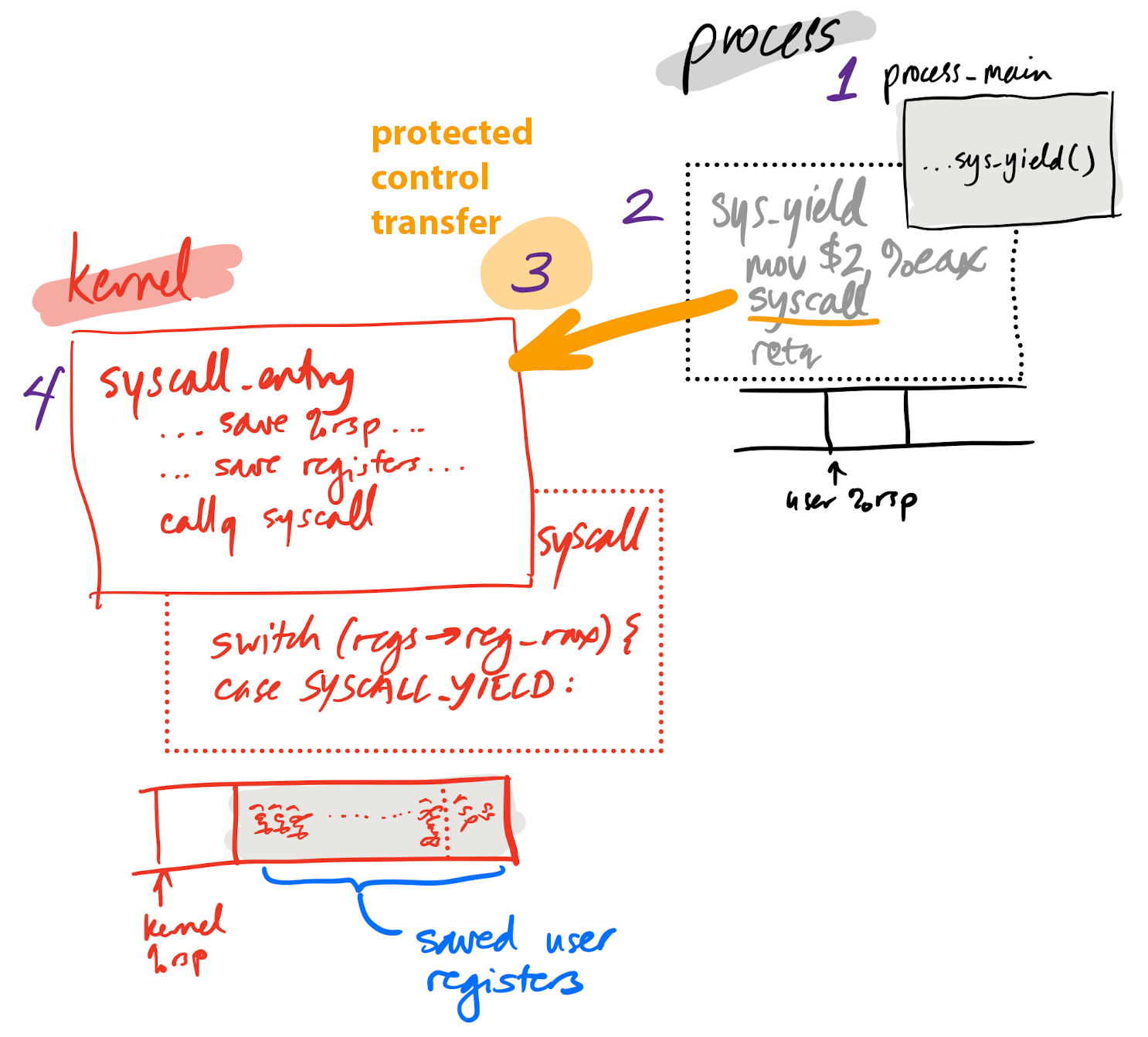
Yielding in depth 1
1. p-alice calls sys_yield
void process_main() {
unsigned n = 0;
while (true) {
++n;
if (n % 1024 == 0) {
console_printf(0x0F00, "Hi, I'm Alice! #%u\n", n);
}
sys_yield(); // <- ********
}
}
Yielding in depth 2
2. sys_yield prepares registers, executes syscall instruction
int sys_yield() {
return make_syscall(SYSCALL_YIELD);
}
uintptr_t make_syscall(int syscallno) {
register uintptr_t rax asm("rax") = syscallno;
asm volatile ("syscall"
: "+a" (rax)
: /* all input registers are also output registers */
: "cc", "memory", "rcx", "rdx", "rsi", "rdi", "r8", "r9",
"r10", "r11");
return rax;
}
0000000000100ba0 <sys_yield()>:
100ba0: f3 0f 1e fa endbr64
100ba4: b8 02 00 00 00 mov $0x2,%eax ; `SYSCALL_YIELD` defined in `lib.hh`
100ba9: 0f 05 syscall
100bab: c3 retq
Yielding in depth 3
3. Processor performs protected control transfer
- Kernel configures processor with entry point for
syscallinstruction during boot - When
syscallinstruction happens, machine switches privilege modes, kernel takes over
Why does syscall work this way?
- Pre-configured entry point
- Kernel can harden that entry point
- Check all system call arguments carefully
- Like a city with thick walls and one fortified gate
Yielding in depth 4
4. Kernel entry point saves processor state, changes stack pointer to kernel stack
_Z13syscall_entryv:
movq %rsp, KERNEL_STACK_TOP - 16 // save entry %rsp to kernel stack
movq $KERNEL_STACK_TOP, %rsp // change to kernel stack
// structure used by `iret`:
pushq $(SEGSEL_APP_DATA + 3) // %ss
subq $8, %rsp // skip saved %rsp
pushq %r11 // %rflags
...
// call syscall()
movq %rsp, %rdi
call _Z7syscallP8regstate
...
Why switch to kernel stack?
- Kernel memory is isolated from process memory
- Kernel has its own call stack, functions, local variables
- Worse, unprivileged process might have garbage stack pointer!
- Kernel cannot depend on process correctness
- Kernel relies on memory it controls
- All accesses to process-controlled memory are checked
Yielding in depth 5
5. syscall function in kernel runs; its argument, regs, contains a copy
of all processor registers at the time of the system call
uintptr_t syscall(regstate* regs) {
// Copy the saved registers into the `current` process descriptor.
current->regs = *regs;
regs = ¤t->regs;
...
switch (regs->reg_rax) {
case SYSCALL_YIELD:
current->regs.reg_rax = 0;
schedule();
Returning from a protected control transfer
- Each system call has the same “callee”: the kernel
- But the kernel may not return from the system call right away
- It might need to wait
- It might run another process first
- Not like a simple function call!
- Kernel must save process state to kernel memory
- Saved state allows restarting process later
Process state
struct proc {
x86_64_pagetable* pagetable; // process's page table
pid_t pid; // process ID
int state; // process state (see above)
regstate regs; // process's current registers
// The first 4 members of `proc` must not change, but you can add more.
};
extern proc ptable[16];
- To run process
PID, callrun(&ptable[PID]) currentis a pointer to theprocthat most recently ranscheduleruns a process that is notcurrent
Kernel state note
- In WeensyOS, every protected control transfer resets the kernel stack
- Local variables do not persist
- The
runandschedulefunctions effectively do not return- Instead, the kernel eventually regains control from another system call or exception
Eve attacks
if (n % 1024 == 0) {
console_printf(0x0E00, "Hi, I'm Eve! #%u\n", n);
while (true) {}
}
14004e: be 6d 0c 14 00 mov $0x140c6d,%esi
140053: bf 00 0e 00 00 mov $0xe00,%edi
140058: b8 00 00 00 00 mov $0x0,%eax
14005d: e8 d1 0a 00 00 callq 140b33 <console_printf(int, char const*, ...)>
140062: eb fe jmp 140062 <process_main()+0x62> ; ****
Defending against processor time attack
- Eve is monopolizing processor time
- Needs hardware defense
- Implementing software defense too expensive
- Timer interrupt
- An “alarm clock” that goes off N times a second
- Passes control to kernel via a privileged control transfer
- Only affects processor in unprivileged mode
Voluntary vs. involuntary privileged control transfer
syscall: Voluntary control transfer to kernel- Process code can save some registers
- Suitable for calling convention
- Kernel can modify some registers before returning (e.g., system call return value)
- Timer interrupt: Involuntary control transfer to kernel
- Can happen after any instruction whatsoever
- Process code cannot delay or prevent interrupt
- No calling convention possible
- Kernel must save and restore all processor registers accessible to processes
Implementing timer interrupts
void kernel_start(const char* command) {
// initialize hardware
init_hardware();
init_timer(100); // 100 Hz ***
void exception(regstate* regs) {
...
switch (regs->reg_intno) {
case INT_IRQ + IRQ_TIMER:
// handle timer interrupt
lapicstate::get().ack(); // reset timer
schedule(); // run a different process
}
Booting: How a computer starts up
- Computer turns on
- Built-in hardware initializes the system
- Built-in hardware loads a small, extremely constrained program called the boot loader from a fixed location on attached storage (Flash memory, disk)
- Boot loader initializes the processor and loads the kernel