Show all solutions
Rules
The exam is open book, open note, open computer. You may access the book and your own notes. You may also use computers or electronic devices to access your own class materials and public class materials. Specifically:
- You may access a browser and a PDF reader.
- You may access your own notes and problem set code electronically.
- You may access Internet sites on which your own notes and problem set code are stored.
- You may access the course site.
- You may access pages directly linked from the course site, including our lecture notes, exercises, and section notes.
- You may access our lecture, problem set, and section code.
- You may run a C or C++ compiler, including an assembler and linker.
- You may access manual pages and common utilities, including calculators and a Python interpreter.
However:
- You may not access class discussion forums or other question forums such as Stack Overflow.
- You may not access an on-line disassembler or compiler explorer.
- You may not access solutions from any previous exam, by paper or computer, except for those on the course site.
- You may not broadly search the Internet for answers to questions or access other courses’ materials. Stick to our course site.
- You absolutely may not contact other humans with questions about the exam—whether in person, via IM, or by posting questions to forums—with the exception of course staff.
Any violations of this policy are breaches of academic honesty and will be treated accordingly. Please appreciate our flexibility and behave honestly and honorably.
Additionally, students are taking the exam at different times. Do not post publicly about the exam until given permission to do so by course staff. This includes general comments about exam difficulty.
Completing your exam
You have 3 hours to complete the exam starting from the time you press Start. Different students may have different exams. Enter your answers directly in this form; a green checkmark appears when an answer is saved.
Students with extra time accommodations: If your extra time is not reflected next to the start button, contact course staff and wait for confirmation before pressing it.
You should not need to attach a drawing or other longer notes, but you may do
so by adding them to a final subdirectory in your cs61-f21-psets
repository. Make sure you push your changes to GitHub before time is up, and
explain in this form where we should look at your notes.
Notes
Assume a Linux operating system running on the x86-64 architecture unless otherwise stated. If you get stuck, move on to the next question. If you’re confused, explain your thinking briefly for potential partial credit.
1. Segments (15 points)
QUESTION 1A. List these segments in order by virtual memory address in a Linux process, lowest address first. Answer format: “1234”.
- Heap segment
- Data segment
- Stack segment
- Code segment
QUESTION 1B. Match each segment with an object that would be located in that segment. Answer format: “1A, 2B, 3C, 4D”.
- Heap segment
- Data segment
- Stack segment
- Code segment
- Global
int- Global
const int- Dynamically-allocated
int- Local
int
QUESTION 1C. Complete this function, which should return some virtual address in the stack segment. Your function should compile without warnings and run without undefined behavior or memory leaks.
uintptr_t example_stack_address() { ... }
QUESTION 1D. Complete this function, which should return a virtual address in the heap segment. Your function should compile without warnings and run without undefined behavior or memory leaks.
uintptr_t example_heap_address() { ... }
QUESTION 1E. Complete this function, which should return a virtual address in the code segment. Your function should compile without warnings and run without undefined behavior or memory leaks.
uintptr_t example_code_address() { ... }
QUESTION 1F. Sometimes it is possible to infer from an x86-64 instruction that a
register contains a virtual address in a specific segment. For example,
following this instruction, %rax most likely contains a virtual address in
the heap segment (because malloc returns a pointer to dynamically-allocated storage):
callq malloc@PLT
Give (1) a single instruction that implies that register %rbx most likely
contains a virtual address in the stack segment, and (2) a single
instruction that implies that %rbx most likely contains a virtual address in
the code segment. Your answer will be two instructions, one per segment.
QUESTION 1G. True or false? The physical memory addresses of the pages in a Linux process’s program image have the same order as the corresponding virtual memory addresses.
QUESTION 1H. List these segments in increasing order by virtual memory address in a WeensyOS process. Answer format: “1234567”.
- Process heap segment
- Process data segment
- Process stack segment
- Process code segment
- Kernel data segment
- Kernel stack segment
- Kernel code segment
QUESTION 1I. The WeensyOS problem set comprises an initial state (Step 0) plus 7 steps (Steps 1–7). Match each state with the maximum virtual address that process 1 can successfully read after each step. You will use some addresses multiple times and others not at all. Answer format: “0A, 1A, 2B, 3C, 4D, 5E, 6A, 7A”.
- Step 0
- Step 1 (kernel isolation)
- Step 2 (process isolation)
- Step 3 (virtual page allocation)
- Step 4 (overlapping address spaces)
- Step 5 (fork)
- Step 6 (exit)
- Step 7 (shared read-only pages)
- 0x100FFF
- 0x13FFFF
- 0x140000
- 0x1CFFFF
- 0x200000
- 0x2FFFFF
- 0x300000
QUESTION 1J. From this WeensyOS image, which demonstrates an execution of
the p-fork process and its children, you can figure out the number of pages
in process 1’s code and stack segments. Say how many these are and explain
briefly.
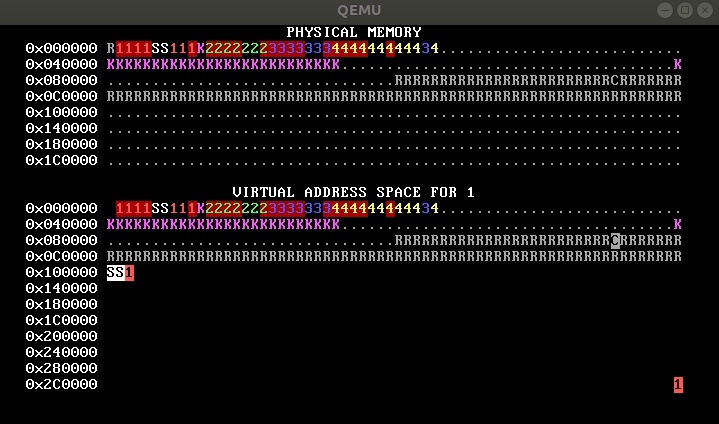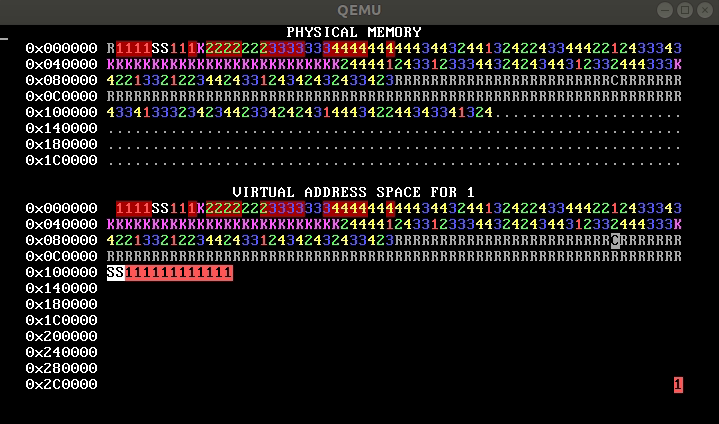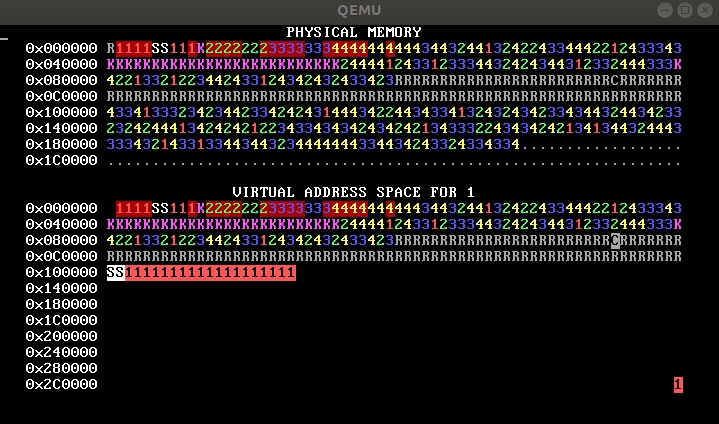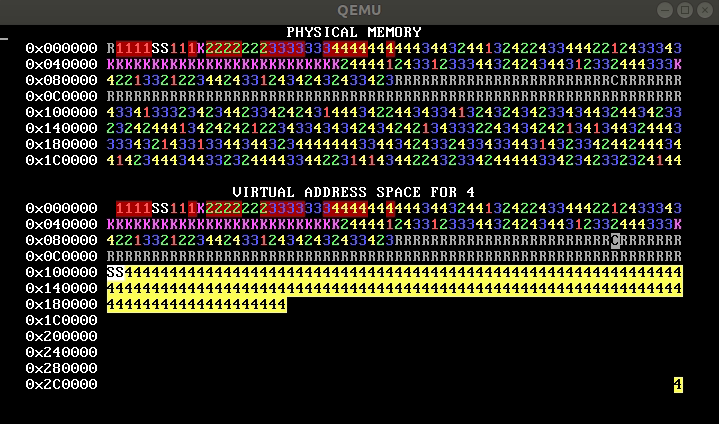
2. Memory inference (10 points)
Recall that a C++ std::vector<T> represents a dynamically-sized array of T
objects. Vectors have both a size and a capacity. The size,
v.size(), equals the number of items currently stored, whereas the capacity,
v.capacity(), equals the number of items for which space has been allocated.
A vector can grow to contain v.capacity() items without reallocating the
underlying data array.
You’re investigating four different implementations of std::vector. You run
this code for four different std::vector libraries (with the same T each
time):
std::vector<T> v;
for (int i = 0; i != 4; ++i) {
v.push_back(T());
}
hexdump_object(v);
The result is these four hexdumps:
v1(library 1):7ff7b27c0970 00 51 cb 01 00 60 00 00 |.Q...`..| 7ff7b27c0978 10 51 cb 01 00 60 00 00 |.Q...`..| 7ff7b27c0980 20 51 cb 01 00 60 00 00 | Q...`..|
v2(library 2):7ff7b27c0970 80 41 9b 00 00 60 00 00 |.A...`..| 7ff7b27c0978 10 00 00 00 04 00 00 00 |........|
v3(library 3):7ff7b27c0970 88 09 7c b2 f7 7f 00 00 |..|.....| 7ff7b27c0978 98 09 7c b2 f7 7f 00 00 |..|.....| 7ff7b27c0980 98 09 7c b2 f7 7f 00 00 |..|.....| 7ff7b27c0988 00 00 00 00 00 00 00 00 |........| 7ff7b27c0990 00 00 00 00 00 00 00 00 |........|
v4(library 4):7ff7b27c0970 30 00 eb 01 00 60 00 00 |0....`..| 7ff7b27c0978 40 00 eb 01 00 60 00 00 |@....`..| 7ff7b27c0980 40 00 eb 01 00 60 00 00 |@....`..|
QUESTION 2A. Which of these libraries might have the same underlying data representation for vectors, if any?
QUESTION 2B. What is sizeof(T)?
QUESTION 2C. Give three distinct types that might equal T. Answer
format: “char, char*, float”.
QUESTION 2D. All four vectors v1–v4 have the same v.size(), namely 4. What
are their likely values for v.capacity()?
QUESTION 2E. Write likely C++ structure definitions for each vector.
Answer format for v1: “struct v1 { int size; T* data; long long int capacity; }”
QUESTION 2F. Write functions in assembly that implement
std::vector<T>::size() for each vector.
Notes: (1) Your assembly functions may assume that T is fixed (it has the
size you computed in Part B). (2) The functions will take one parameter,
namely a pointer to the vector. When called on the above vectors, the register
holding the first parameter would contain the value 0x7ff7'b27c'0970. (3)
Three of these implementations can use the same instructions.
QUESTION 2G. One of these implementations uses the so-called small-vector optimization. This optimization reserves space within the vector structure for a small number of items. Small-sized vectors can store their items in the reserved space, thereby avoiding all dynamic allocation. Which implementation implements the small-vector optimization, and how many items can fit in its reserved space?
QUESTION 2H. Complete this function for the implementation with the
small-vector optimization. The function should return true iff the vector
data is using the reserved space.
bool std::vector<T>::is_using_small_vector_space() { ...
3. Assembly in context (10 points)
QUESTION 3A. Which of these instructions, when executed by an unprivileged WeensyOS process, always cause an exceptional control transfer (also known as protected control transfer) to the kernel, which maybe cause an exceptional control transfer, and which never cause an exceptional control transfer? (Do not count external sources of exceptional control transfers, such as timer interrupts.)
movq %rax, %rbxmovq %rax, (%rbx)movq 0x0, %raxmovq $0x0, %raxsyscallretq
QUESTION 3B. When a WeensyOS process executes a syscall instruction, what
best describes the contents of the %rax register? Give the best answer. If
unsure, look at the syscall() function definition in kernel.cc.
%raxis garbage, but after the system call completes, it will hold the system call’s return value.%raxholds the first parameter to the system call.%raxholds the system call number.%raxholds the process ID.- None of the above.
QUESTION 3C. The next parts concern this assembly, which corresponds to an
implementation of ssize_t io61_read(io61_file* f, unsigned char* buf, size_t sz) from problem set 4.
_Z9io61_readP9io61_filePhm:
endbr64
testq %rdx, %rdx
jne .L12
xorl %eax, %eax
ret
.L12:
pushq %rbp
movq %rsi, %rbp
pushq %rbx
movq %rdi, %rbx
subq $8, %rsp
call _Z10io61_readcP9io61_file@PLT
testl %eax, %eax
jns .L13
movl (%rbx), %edi
addq $8, %rsp
movq %rbp, %rsi
movl $1, %edx
popq %rbx
popq %rbp
jmp read@PLT
.L13:
movb %al, 0(%rbp)
addq $8, %rsp
movl $1, %eax
popq %rbx
popq %rbp
ret
What does this function return if sz == 0?
QUESTION 3D. What is the maximum value this io61_read function can return?
QUESTION 3E. What is the best explanation for why this io61_read
function executes pushq %rbp after label .L12? Select one.
- The function needs to align the stack before calling
io61_read. - The
%rbpregister is needed to save the%rsiregister. - The
%rbpregister is callee-saved, so this function needs to restore its initial value before returning. - The
%rbpregister is caller-saved, so this function needs to restore its initial value before returning. - Compilers are smarter than us.
QUESTION 3F. Is this compiler running with optimization? Explain briefly.
QUESTION 3G. Is it possible that this io61 implementation is using a
cache for sequential reads? Explain briefly.
4. Weensy messages (15 points)
QUESTION 4A. Give a virtual address that would cause a page fault
when accessed by any user process (using their page tables) or by the kernel
(using kernel_pagetable). Answer format: 0x40000
QUESTION 4B. Give a virtual address that would not cause a
page fault when accessed by a user process (using its page table), but
would cause a page fault when accessed by the kernel (using
kernel_pagetable). Answer format: 0xB8000
QUESTION 4C. Use vmiter to complete this kernel function.
// Return the length of the NUL-terminated string located starting at
// address `addr` in `p`’s virtual memory, or -1 if any part of that
// string is not readable by user process `p`.
ssize_t check_user_string(proc* p, uintptr_t addr) {
... YOUR CODE ...
QUESTION 4D. This implementation of check_user_string sometimes works,
but certain arguments can crash the kernel by dereferencing an invalid virtual
address and causing a page fault. Explain briefly how that problem could
occur.
ssize_t broken_check_user_string(proc* p, uintptr_t addr) {
// `addr` must be in the portion of the address space reserved for processes
if (addr < PROC_START_ADDR || addr >= MEMSIZE_VIRTUAL) {
return -1;
}
// install `p`’s page table!
set_pagetable(p->pagetable);
// using that page table, call `strlen`
size_t len = strlen((const char*) addr);
// restore `kernel_pagetable` and return
set_pagetable(kernel_pagetable);
return len;
}
QUESTION 4E. The remaining parts of this problem concern a new inter-process communication
primitive in WeensyOS called the message. A message is an unsigned value
associated with a string name. A single system call implements messages:
long sys_msg(const char* name, int flags [, unsigned value])- Return the value associated with the message named
nameon the kernel’s message board. Returns-1if the message does not exist.flagsmay contain:MSG_POST: If set, postvalueto the message board forname, so that future calls tosys_msg(name)will returnvalue. Returnsvalueon success,-1on failure (for example, because there’s not enough space for a new message, ornameis too long).
In the kernel’s system call handler for SYSCALL_MSG, which
arguments need to be checked for validity to avoid confused-deputy attacks and
which do not?
QUESTION 4F. You’re comparing the merits of two implementations for an in-kernel message structure. Here they are:
struct msg1 {
const char* name;
// -> points to process memory in the first process that
// called MSG_PUT
unsigned value;
};
struct msg2 {
char name[32];
unsigned value;
};
Which implementation would you choose, msg1 or msg2? Explain briefly.
QUESTION 4G. Lastly, we introduce a new MSG_WAIT flag to sys_msg. If
(flags & MSG_WAIT) != 0, then the system call should block until the
message value equals the value argument.
Describe briefly how you could implement this functionality in WeensyOS. You
may reference this baseline implementation of the kernel’s SYSCALL_MSG
handler if you’d like.
case SYSCALL_MSG: {
ssize_t len = check_user_string(current, current->regs.reg_rdi);
if (len < 0 || len >= 1024) {
return -1;
}
char* name = ... [the `name` argument] ...;
int flags = current->regs.reg_rsi;
unsigned value = current->regs.reg_rdx;
// find (or possibly create) the message associated with `name`
msg* m = find_message(name, flags);
if (m) {
// act on that message
if (flags & MSG_POST) {
m->value = value;
}
return m->value;
} else {
// not found and/or no space
return -1;
}
}
5. Reading optimizations (10 points)
QUESTION 5A. The lecture code repository contains six programs that read a file sequentially. Rank-order these programs from slowest to fastest. Answer format: “123456”.
r-exitbyter-mmapbyter-osblock -b 512r-osbyter-stdioblock -b 512r-stdiobyte
QUESTION 5B. Which of these programs uses the batching technique? List all that apply (by number).
QUESTION 5C. Which of these programs uses the prefetching technique? List all that apply (by number).
QUESTION 5D. Which of these programs will make the same number of system calls when run on the same input file? Explain briefly.
QUESTION 5E. Name a system call that is always used for nonsequential file access, but rarely used for sequential file access.
QUESTION 5F. Give an example reference string that would perform better for a 3-slot cache using the First-In, First-Out eviction policy than one using the Least Recently Used eviction policy. Example reference string: “12345”.
6. Process control (13 points)
In lecture we divided process state into three components: program image (registers, memory), identity (process ID, parent process ID), and environment (file descriptor table).
QUESTION 6A. Which of these system calls might modify a process’s program image? List all that apply. Do not count system call return values as modifying the program image.
writereaddup2getpidmmapforkopenexecvp- None of the above
QUESTION 6B. Which of the system calls in Part A might modify a process’s environment? List all that apply.
QUESTION 6C. Which of the system calls in Part A might modify a process’s identity? List all that apply.
QUESTION 6D. Which of the system calls in Part A might create a new process? List all that apply; and for each listed system call, describe how the newly created process’s state differs from the original process’s state.
QUESTION 6E. The remaining parts concern the following simplified strace
output, which was extracted from an example shell running a three-command
pipeline, then postprocessed as suggested in section
notes to group
system calls by process ID. (clone, wait4, and dup3 correspond to
fork, waitpid, and dup2, respectively.)
145 clone(child_stack=NULL, flags=SIGCHLD) = 147
145 clone(child_stack=NULL, flags=SIGCHLD) = 149
145 clone(child_stack=NULL, flags=SIGCHLD) = 150
145 close(4) = 0
145 close(6) = 0
145 close(15) = 0
145 close(16) = 0
145 wait4(147, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], 0, NULL) = 147
145 --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=147, si_uid=0, si_status=0, si_utime=0, si_stime=0} ---
145 wait4(149, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], 0, NULL) = 149
145 --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=149, si_uid=0, si_status=0, si_utime=0, si_stime=0} ---
145 wait4(150, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], 0, NULL) = 150
147 close(4) = 0
147 close(16) = 0
147 close(15) = 0
147 dup3(6, 1, 0) = 1
147 close(6) = 0
147 execve("/usr/bin/echo", ["echo", "foo"], 0xffffbe8f3d30 /* 15 vars */ <unfinished ...>
149 close(4) = 0
149 close(6) = 0
149 close(16) = 0
149 dup3(15, 0, 0) = 0
149 close(15) = 0
149 execve("/usr/bin/wc", ["wc", "-c"], 0xffffbe8f3d30 /* 15 vars */ <unfinished ...>
150 close(6) = 0
150 dup3(4, 0, 0) = 0
150 dup3(16, 1, 0) = 1
150 close(4) = 0
150 close(15) = 0
150 close(16) = 0
150 execve("/usr/bin/tr", ["tr", "-s", "o"], 0xffffbe8f3d30 /* 15 vars */ <unfinished ...>
In the strace above, does the pipeline exit successfully? Explain briefly how you can tell.
QUESTION 6F. In the strace above, which process ID corresponds to the process in the middle of the pipeline? Explain briefly how you can tell.
QUESTION 6G. In the strace above, which file descriptors correspond to write ends of pipes?
QUESTION 6H. In the strace above, what command line is being executed?
Answer format: “cat /dev/null | rev | rev”.
QUESTION 6I. Give an example of a single line in the strace above where if the corresponding system call were removed, some processes in the pipeline would never terminate.
7. Peeps (15 points)
This question concerns a pipe-like abstraction called a peep. Peeps, like pipes, can be used to transfer data between processes, and in many cases a peep can be used in place of a pipe. Unlike pipes, however, peeps have no in-kernel buffering capacity.
- On success, the
int peep(int pfd[2])system call creates two file descriptors:pfd[0], the read end, andpfd[1], the write end. - A
write(pfd[1], buf, sz)system call will write at most one byte of data to the write end of the peep. The system call will block until another process or thread callsreadon the read end, or the read end is closed. - Similarly,
read(pfd[0], buf, sz)will read at most one byte of data from the read end of the peep. It will block until another process or thread callswriteon the write end, or the write end is closed. - Just as with pipes, when all copies of a peep’s write end are closed, then
read(pfd[0])returns0, indicating end-of-file; and when all copies of a peep’s read end are closed, thenwrite(pfd[1])delivers aSIGPIPEsignal to the calling process.
QUESTION 7A. Will pipelines using peeps generally perform worse than with pipes, better than with pipes, or about the same as with pipes? Explain briefly, referring to the benefits of caching optimizations if appropriate.
QUESTION 7B. Peeps transfer at most one character per system call. On Linux, by default, what is the maximum number of characters that can be transferred to or from a pipe in one system call? (Hint: We investigated this in lecture.)
QUESTION 7C. Peeps can cause many short reads and writes. Complete this function, which tries to avoid short reads.
// readall(fd, buf, sz)
// Like `read(fd, buf, sz)`, but tries extra hard to read all `sz`
// requested bytes. Rather than returning a short read, `readall`
// will call `read` again, returning only after reading all `sz`
// characters, encountering end-of-file, or encountering an error.
ssize_t readall(int fd, char* buf, size_t sz) {
QUESTION 7D. Peeps cannot be used to implement the “self-pipe” signal
handler we saw in Process 3
(process3/timedwait-selfpipe.cc) that helped solve the timed-wait problem. Why not? Explain briefly.
QUESTION 7E. This code for running a two-process pipeline is incorrect. Nevertheless, it appears to run some pipelines correctly.
// Run the pipeline `argv1... | argv2...`, returning the exit status of `argv2`.
int broken_simple_pipeline(char* argv1[], char* argv2[]) {
int pfd[2];
P1: int r = pipe(pfd); // OR peep(pfd);
assert(r >= 0);
pid_t lhpid = fork();
assert(lhpid >= 0);
if (lhpid == 0) {
dup2(pfd[1], 1);
close(pfd[0]);
close(pfd[1]);
execvp(argv1[0], argv1);
assert(false);
}
r = waitpid(lhpid, nullptr, 0);
assert(r == lhpid);
pid_t rhpid = fork();
assert(rhpid >= 0);
if (rhpid == 0) {
dup2(pfd[0], 0);
close(pfd[0]);
close(pfd[1]);
execvp(argv2[0], argv2);
assert(false);
}
close(pfd[0]);
close(pfd[1]);
int status;
r = waitpid(rhpid, &status, 0);
assert(r == rhpid);
return status;
}
Write a shell command that broken_simple_pipeline would run correctly
whether or not line P1 used pipe or peep.
QUESTION 7F. Write a shell command that broken_simple_pipeline would run
correctly if line P1 used pipe, but incorrectly if line P1 used peep.
QUESTION 7G. Write a shell command that broken_simple_pipeline would run
incorrectly whether or not line P1 used pipe or peep.
QUESTION 7H. A peepbuffer helper process can implement buffering even
without kernel help. When inserted into a peepline, as in prog1 | peepbuffer | prog2, peepbuffer should let prog1 and prog2 run in parallel—prog1
can write many characters before prog2 reads any.
Complete this program, peepbuffer.cc. For full credit, your solution should
have no data races.
#include <thread>
#include <mutex>
#include <condition_variable>
#include <unistd.h>
... YOUR CODE AS NEEDED ...
int main() {
... YOUR CODE ...
8. Shared locks (12 points)
The std::shared_mutex synchronization object is a mutex that supports two
kinds of ownership. Exclusive ownership provides full mutual exclusion,
just like std::mutex. Once a thread acquires the mutex using sm.lock(), no
other thread can acquire the mutex in any mode. Shared ownership, in
contrast, allows multiple threads to share the mutex. Once a thread acquires
the mutex using sm.shared_lock(), no other thread can acquire the mutex in
exclusive mode, but other threads can acquire the mutex in shared mode.
Here are the operations:
sm.lock()- Acquire
smin exclusive mode. sm.unlock()- Release
smfrom exclusive mode. This thread must have previously calledsm.lock(). sm.lock_shared()- Acquire
smin shared mode. sm.unlock_shared()- Release
smfrom shared mode. This thread must have previously calledsm.lock_shared().
QUESTION 8A. Implement the lock() and lock_shared() methods for the
following definition of shared_mutex, using atomics. We’ve written
unlock and unlock_shared for you.
class shared_mutex {
std::atomic<unsigned> shcount = 0;
std::atomic<unsigned> excount = 0;
void lock() { ... YOUR CODE ... }
void unlock() {
--this->excount;
}
void lock_shared() { ... YOUR CODE ... }
void unlock_shared() {
--this->shcount;
}
};
QUESTION 8B. Which of the functions in Part A’s shared_mutex block, and
which spin (poll), if any? Describe briefly.
QUESTION 8C. Implement all four methods for the the following definition of
shared_mutex, using std::mutex and no atomics. For full credit, your
lock and lock_shared functions should block. Try to minimize the number of
new member variables.
class shared_mutex2 {
std::mutex m;
int mode = 0; // -1 means exclusive mode, 0 means unlocked, >0 means shared mode
... MAYBE YOUR CODE ... // add anything else you need
void lock() { ... YOUR CODE ... }
void unlock() { ... YOUR CODE ... }
void lock_shared() { ... YOUR CODE ... }
void unlock_shared() { ... YOUR CODE ... }
};
QUESTION 8D. Assume that the function thread_index() returns a number
between 0 and NTHREADS - 1, inclusive, that identifies the currently-running
thread uniquely. Use the thread_index() function to implement all four
methods for the following definition of shared_mutex. For full credit, you
should add no new member variables.
class shared_mutex3 {
std::mutex ms[NTHREADS];
void lock() { ... YOUR CODE ... }
void unlock() { ... YOUR CODE ... }
void lock_shared() { ... YOUR CODE ... }
void unlock_shared() { ... YOUR CODE ... }
};
QUESTION 8E. Use one or more mutexes and/or shared_mutexes to add correct
synchronization to this resizable array. Your implementation should:
- Have no data races.
- Allow threads to call
getin parallel on arbitrary indexes. - Provide mutual exclusion for calls to
seton the same index. - Allow different threads to call
setin parallel on different indexes.
class shared_vector {
T* data;
size_t size;
M1: // add any members/helper functions you need
void resize(size_t new_size) {
R1: T* new_data = new T[new_size];
R2: memcpy(new_data, this->data, std::min(new_size, this->size) * sizeof(T));
R3: delete[] this->data;
R4: this->data = new_data;
R5: this->size = new_size;
}
T get(size_t index) const {
G1: assert(index < this->size);
G2: return this->data[index];
}
void set(size_t index, T value) {
S1: assert(index < this->size);
S2: this->data[index] = this->size;
}
};
You may refer to line numbers in your answer, or rewrite the complete code.
9. The end (5 points)
QUESTION 9A. What improvements would you suggest to the class? Any answer but no answer will receive full credit.
QUESTION 9B. What topics do you wish we had spent more time on? Any answer but no answer will receive full credit.